☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
来自中科院自动化所的团队提出 FreeVS,一个全生成式的新视角合成方法。相较于仅能在记录的车辆行驶原轨迹上渲染高质量相机视角的基于场景重建的方法,FreeVS 能够作为生成引擎渲染真实场景中任意车辆行驶轨迹下的视频。FreeVS 可被直接部署于任何测试场景,而无需负担通常耗时 2-3 小时的场景重建过程。

真实视频

新轨迹下相机视频

以生成模型合成真实场景中的相机成像
现有驾驶场景中的新视角合成方法多遵循「场景重建 – 新视角渲染」的管线,依靠重建得到的 NeRF 或 3D-GS 等场景表示来渲染新视角下的成像。
然而基于重建的方法具有两大瓶颈,1)无法合理渲染缺少对应观测的新视角上的图像,2)场景重建耗时长;这使得重建方法无法高效高质地在实际数据采集轨迹之外渲染大量新相机视图。
如简单的视角左右平移即会引起前有方法图像渲染质量的严重下降:

与前有重建方法在原训练视角、训练视角右一米、训练视角上一米的视角合成效果对比。
对此,作者提出一种新颖的完全基于生成模型的新视角合成方法 FreeVS。作者采用一简洁有效的生成管线,可严格基于已观测到的三维场景生成任意视角的相机观测,且无需进行场景重建。
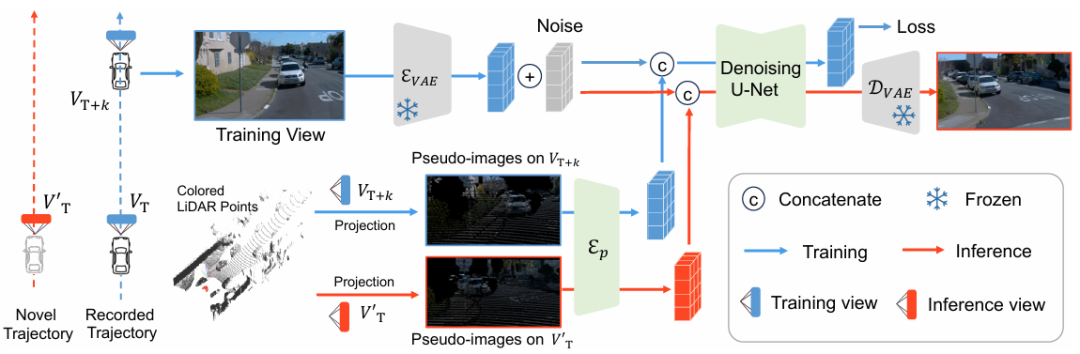
FreeVS 方法管线。生成模型基于染色点云投影恢复相机成像。
作者采用从稀疏点云投影中恢复相机成像的生成管线,这使得生成模型的行为类似于 Inpainting 模型,基于稀疏但可靠的点云投影点补全目标图像。
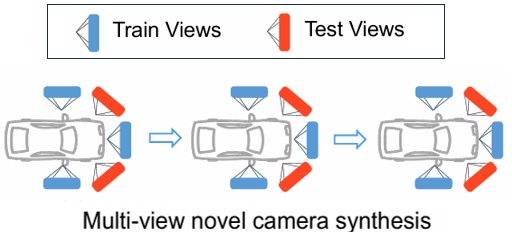
在训练过程中,生成模型学习基于给定帧的三维先验生成邻近帧的相机成像。尽管训练数据中驾驶车辆在绝大多情况下走直线前行,但生成模型可沿车辆轨迹在侧向相机视角学习相机视角的横向移动。
 Q.AI视频生成工具
Q.AI视频生成工具
支持一分钟生成专业级短视频,多种生成方式,AI视频脚本,在线云编辑,画面自由替换,热门配音媲美真人音色,更多强大功能尽在QAI
 73 查看详情
73 查看详情 
在测试阶段,以图像信息染色的场景三维点云被投影至任意所需视角,以控制图像生成结果。

FreeVS 方法训练数据与推理效果示例。即使训练数据中无车辆横向移动到逆行车道的例子,生成模型仍然可依靠侧向相机的训练对((c)->(a))学习相机的侧向移动,从而生成合理的高质量成像 (f)。
车辆行驶模拟与场景编辑
以 Waymo 数据集中的真实场景为例,FreeVS 能够在驾驶车辆原本并未移动的场景模拟车辆移动:
真实视频

新轨迹下相机视频
能模拟车辆变线行驶,甚至能秒变 GTA,使车辆撞向行人:

真实视频

新轨迹下相机视频
能在原本直行的场景令车辆走大 Z 型前进:

真实视频






以上就是把Waymo玩成GTA游戏!全生成式的车辆行驶轨迹视频合成器来了的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/412095.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫