
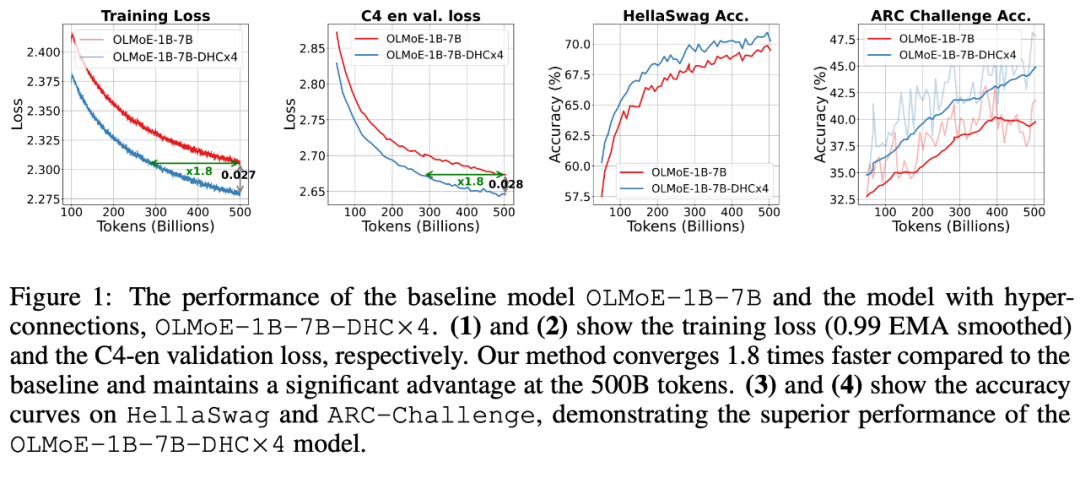
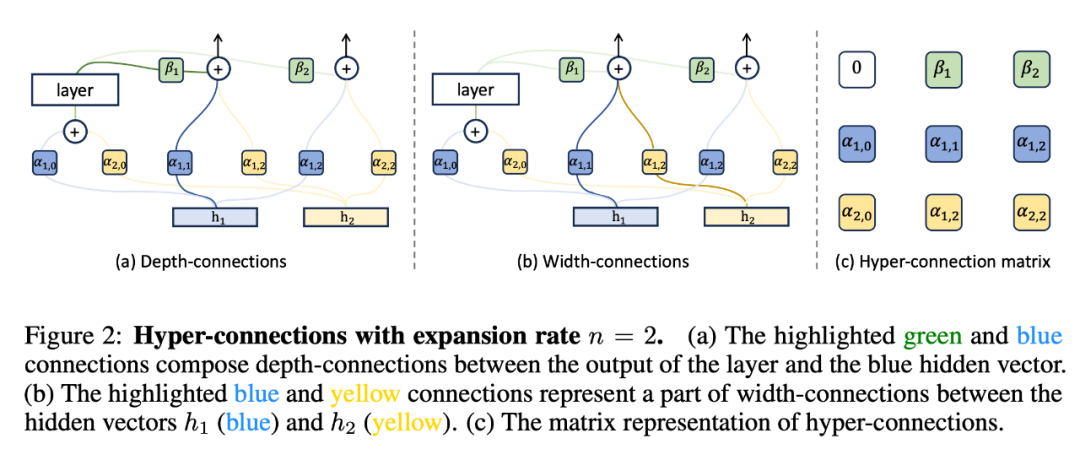
字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。在 Dense 模型和 MoE 模型预训练中,超连接方案展示出显著的性能提升效果,使收敛速度最高可加速 80%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

 ,网络的初始输入为
,网络的初始输入为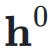 ,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):
,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):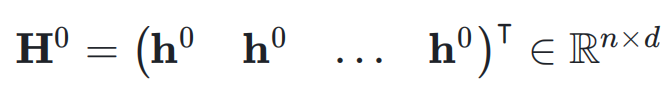
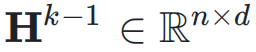 ,即:
,即: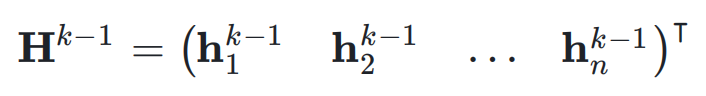
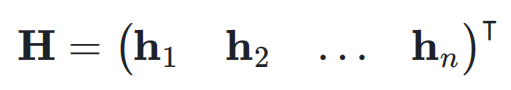

 ,它可能是 Transformer 中的 attention 层或者是 FFN 层。超连接的输出
,它可能是 Transformer 中的 attention 层或者是 FFN 层。超连接的输出  可以简单地表示为:
可以简单地表示为: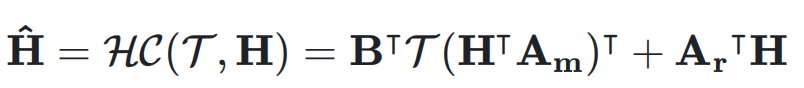
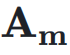 作为权重对输入
作为权重对输入 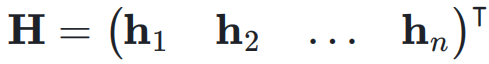 进行加权求和,得到当前层的输入
进行加权求和,得到当前层的输入 :
: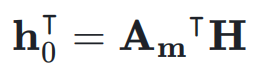 同时,
同时,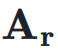 用于将
用于将  映射到残差超隐藏矩阵
映射到残差超隐藏矩阵 ,表示如下:
,表示如下: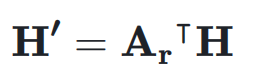
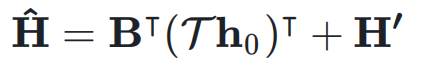

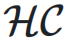 的元素可以动态依赖于输入
的元素可以动态依赖于输入  ,动态超连接的矩阵表示为:
,动态超连接的矩阵表示为: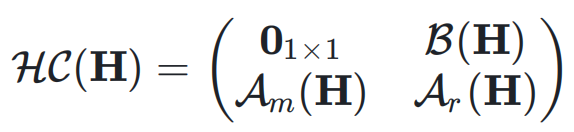
 和输入
和输入 ,可以得到动态超连接的输出:
,可以得到动态超连接的输出: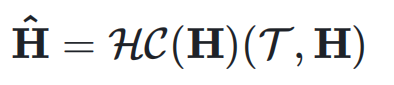

 的超连接矩阵:
的超连接矩阵:
 和
和 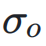 分别表示神经网络层输入和输出的标准差,
分别表示神经网络层输入和输出的标准差, 表示它们之间的协方差。
表示它们之间的协方差。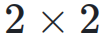 的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 Post-Norm,权重依赖于输入和输出的方差及协方差,形成一个
的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 Post-Norm,权重依赖于输入和输出的方差及协方差,形成一个  的矩阵。因此,它们的超连接矩阵是不可训练的。
的矩阵。因此,它们的超连接矩阵是不可训练的。 矩阵,且权重是可训练的,甚至可以基于输入进行动态预测。
矩阵,且权重是可训练的,甚至可以基于输入进行动态预测。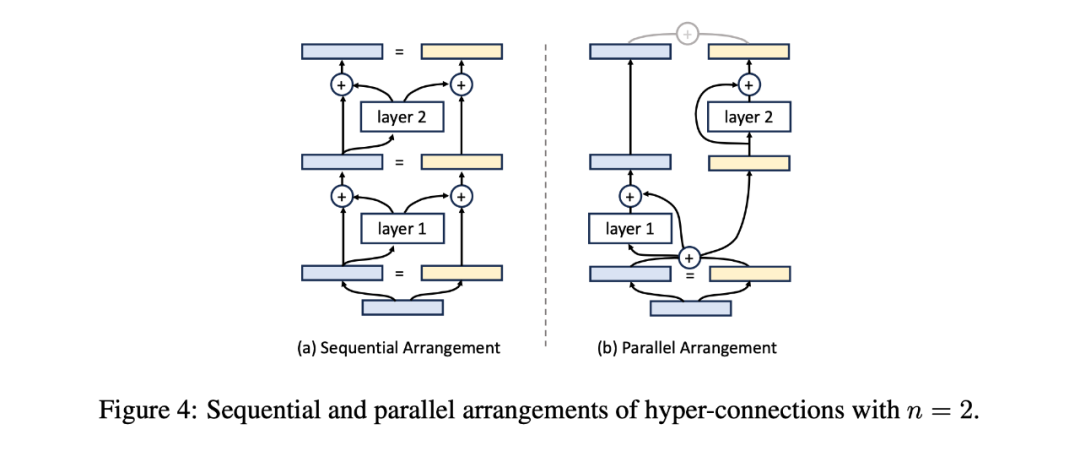
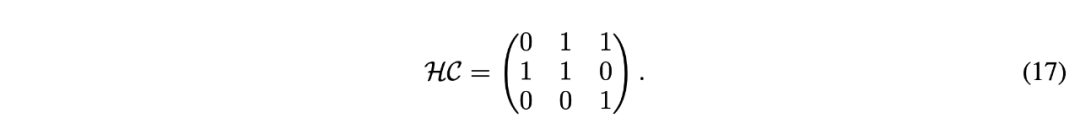

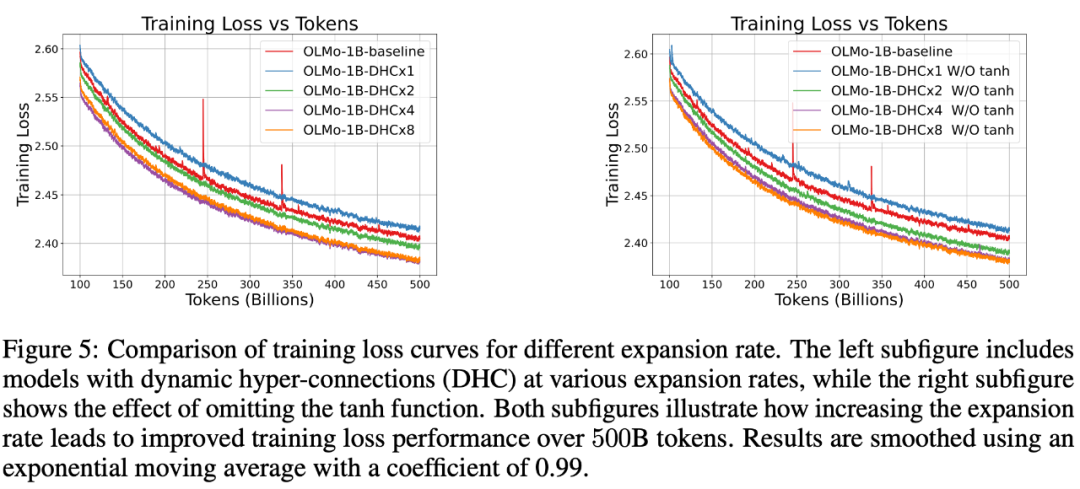
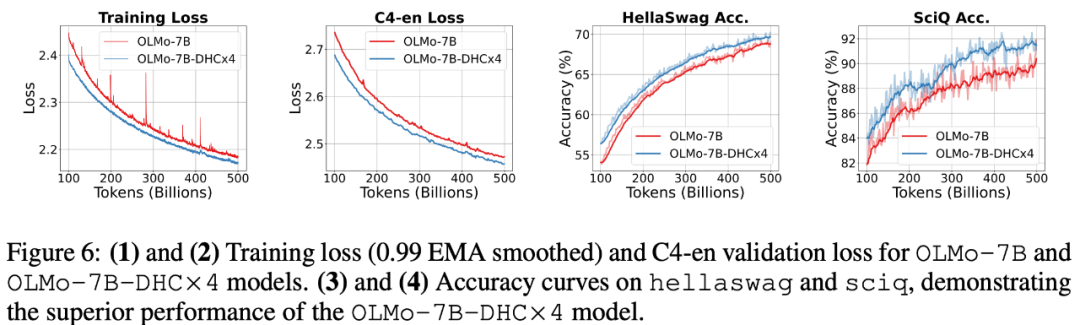
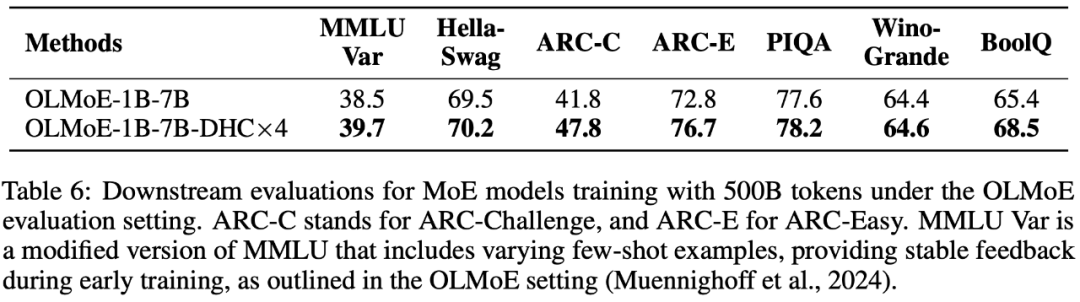
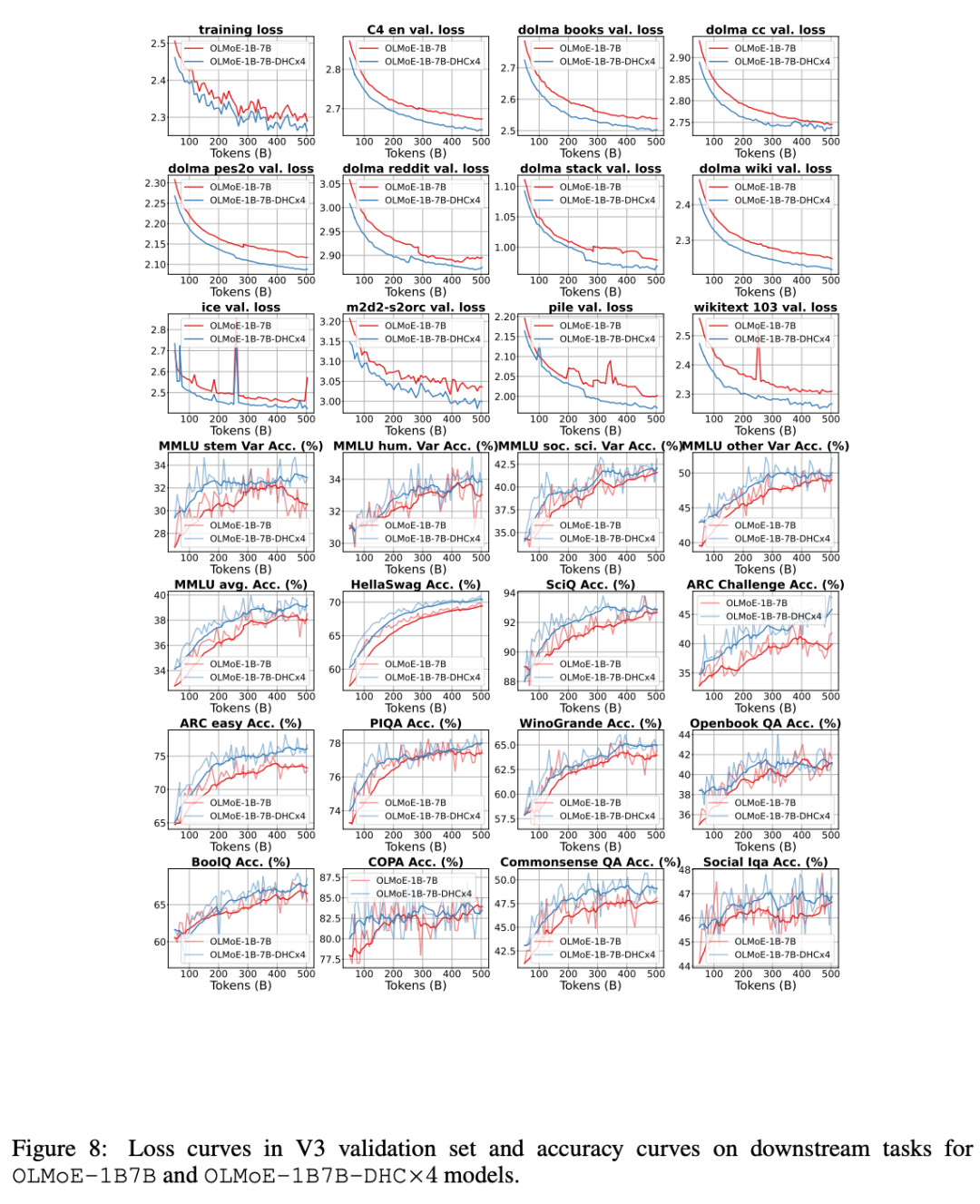
以上就是字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/412327.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















