
让 LLM 在自我进化时也能保持对齐。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
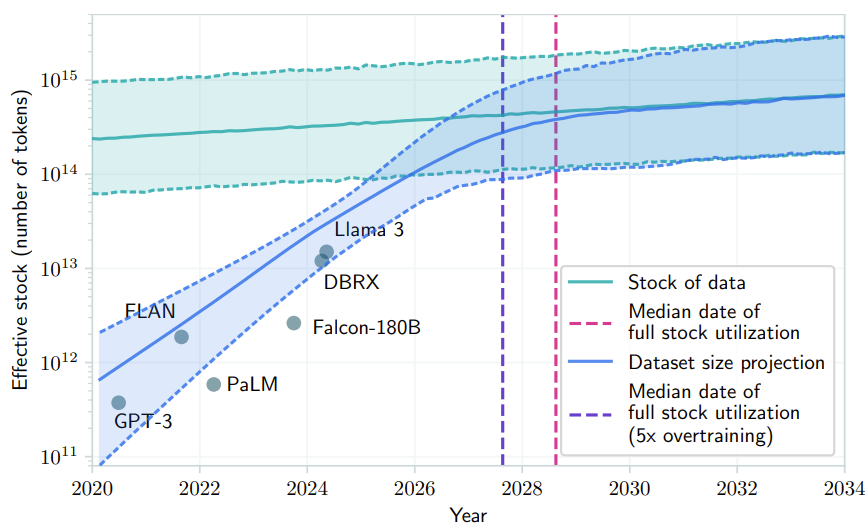 如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》
如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》

论文标题:evolving alignment via asymmetric self-play
论文地址:https://arxiv.org/pdf/2411.00062
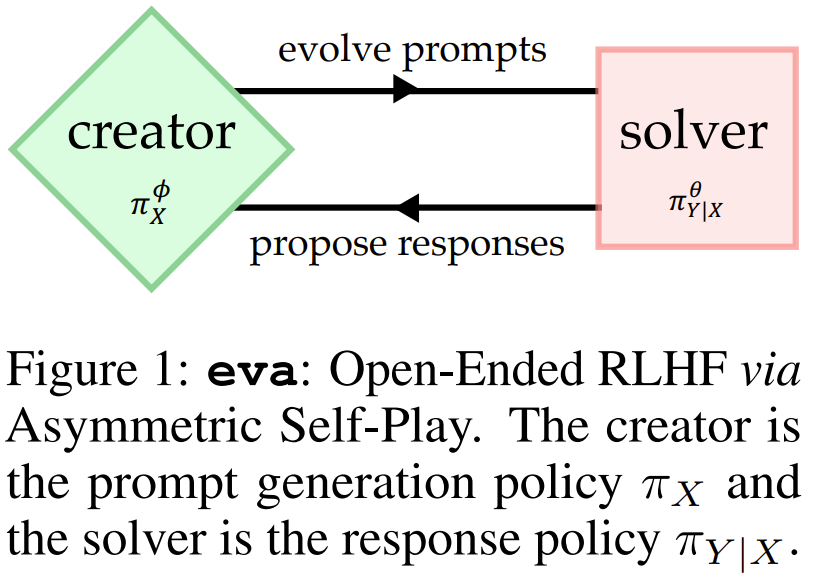



直观地讲,创建器可以通过复杂度不断增加的提示词例程来指导求解器,从而实现高效和一般性的学习,以处理现实任务的多样性。
从数学上看,这类似于通过期望最大化进行的 RL 优化,其中提示词分布的 φ 在每个步骤中都是固定的。
创建器(Creator:提示词博弈者 π_X,其作用是策略性地为求解器生成提示词。
求解器(Solver:响应博弈者 π_{Y|X}(或 π),其作用是学习生成更符合偏好的响应。
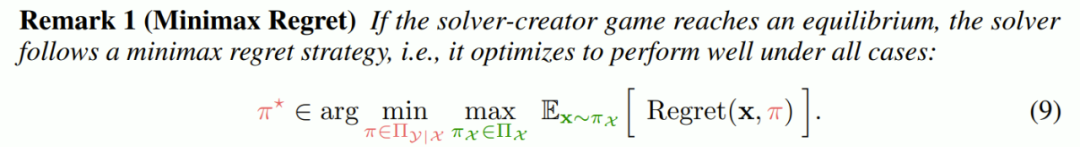

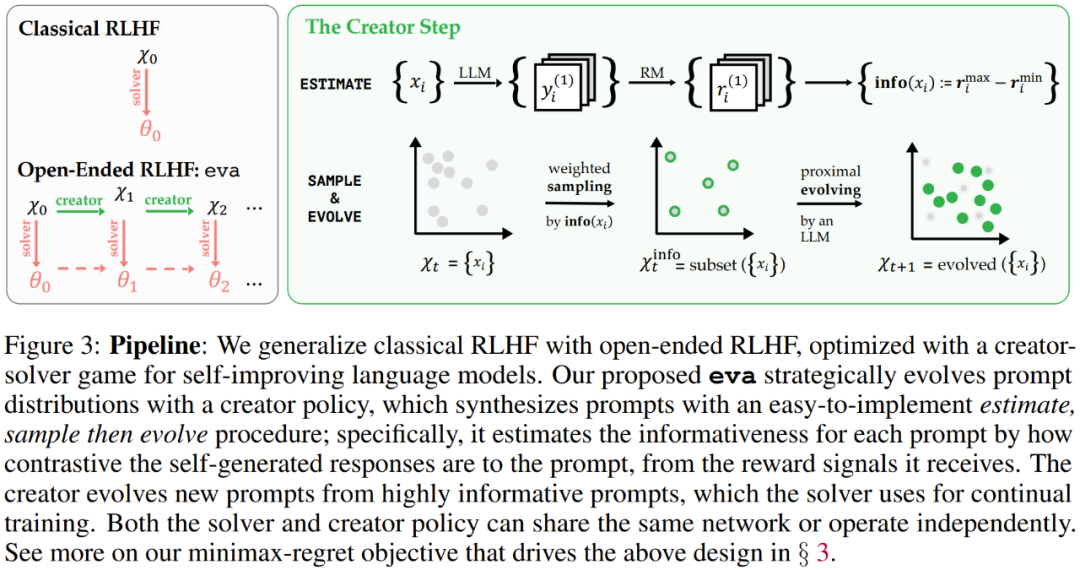
第 1 步:info (・)—— 估计信息量。对于提示集 X) t 中的每个 x,生成响应、注释奖励并通过 (10) 式估计 x 的信息量指标。
第 2 步:sample (・)—— 对富含信息的子集进行加权采样。使用信息量指标作为权重,对富含信息的提示词子集 X^info_t 进行采样,以便稍后执行演进。
 AI建筑知识问答
AI建筑知识问答
用人工智能ChatGPT帮你解答所有建筑问题
 22 查看详情
22 查看详情 
第 3 步:evolve (・)—— 为高优势提示词执行近端区域演进。具体来说,迭代 X^info_t 中的每个提示词,让它们各自都演化为多个变体,然后(可选)将新生成的提示词与对 X_t 的均匀采样的缓存混合以创建 X′_t。
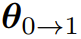 是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到
是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到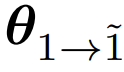 。
。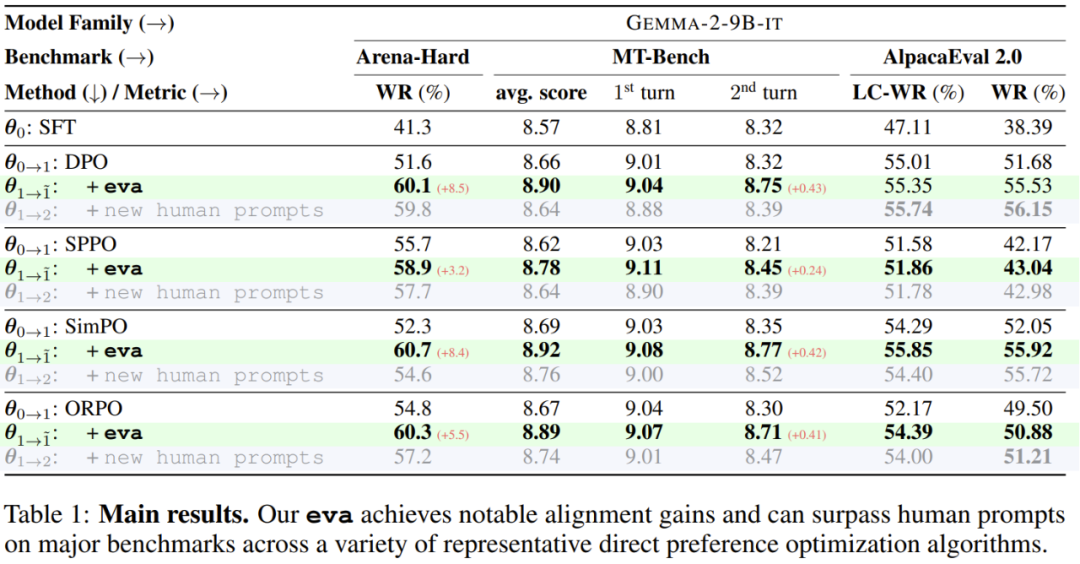
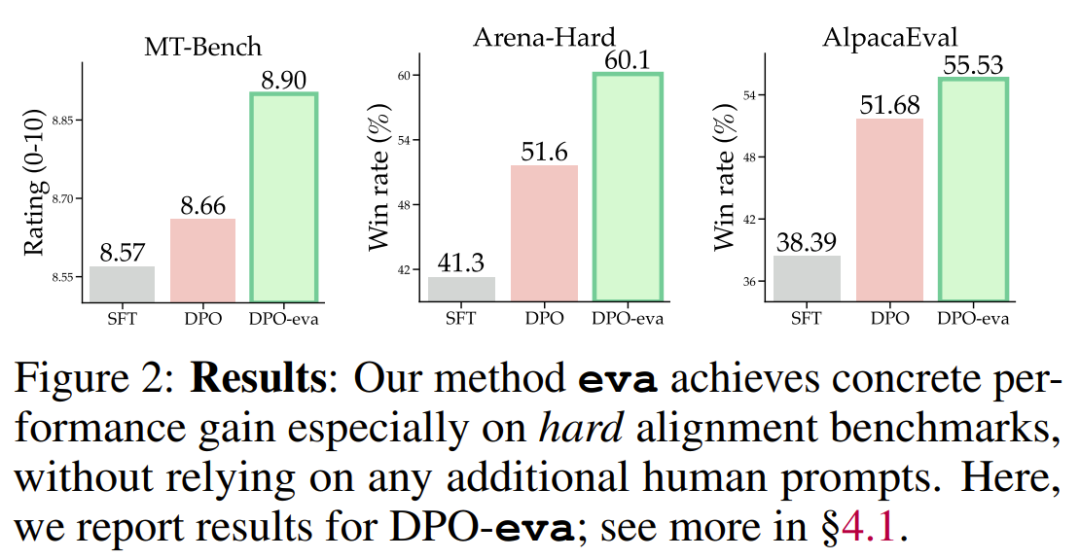
 的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型
的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型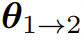 ,这可被视为是人类提示词。同时,前者还能做到成本更低,速度更快。
,这可被视为是人类提示词。同时,前者还能做到成本更低,速度更快。信息量指标:新提出的基于后悔值的指标优于其它替代指标;
采样之后执行演化的流程:新方法优于贪婪选择方法;
使用奖励模型进行扩展:eva 的对齐增益会随奖励模型而扩展;
持续训练:新提出的方法可通过增量训练获得单调增益;eva 演化得到的数据和调度可用作隐式正则化器,从而实现更好的局部最小值。
以上就是LLM超越人类时该如何对齐?谷歌用新RLHF框架解决了这个问题的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/412574.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























