
毫无疑问,多智能体肯定是 openai 未来重要的研究方向之一,前些天 openai 著名研究科学家 noam brown 还在 x 上为 openai 正在组建的一个新的多智能体研究团队招募机器学习工程师。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


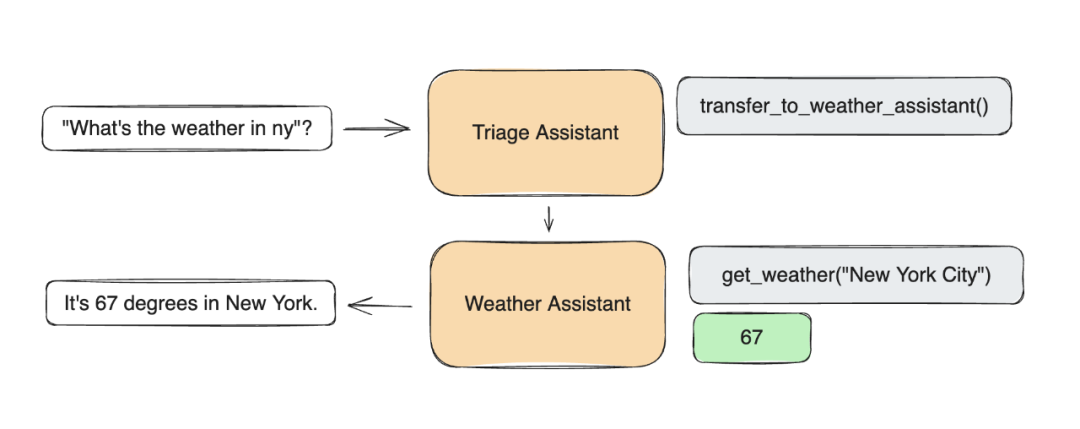
pip install git+ssh://git@github.com/openai/swarm.git
from swarm import Swarm, Agentclient = Swarm()def transfer_to_agent_b():return agent_bagent_a = Agent(name="Agent A",instructions="You are a helpful agent.",functions=[transfer_to_agent_b],)agent_b = Agent(name="Agent B",instructions="Only speak in Haikus.",)response = client.run(agent=agent_a,messages=[{"role": "user", "content": "I want to talk to agent B."}],)print(response.messages[-1]["content"])
Hope glimmers brightly,New paths converge gracefully,What can I assist?
 文心智能体平台
文心智能体平台
百度推出的基于文心大模型的Agent智能体平台,已上架2000+AI智能体
 0 查看详情
0 查看详情 
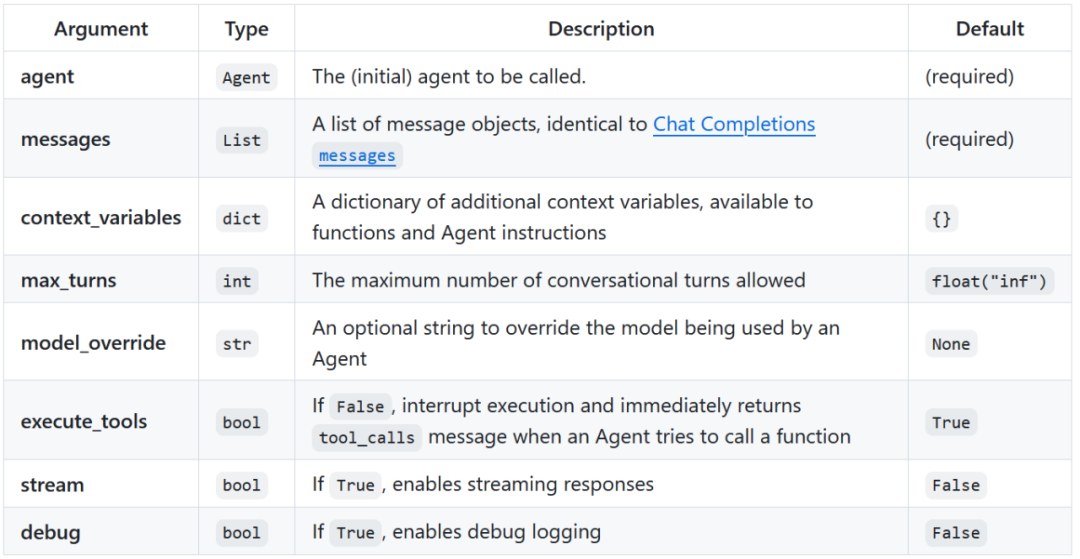
from swarm import Swarmclient = Swarm()
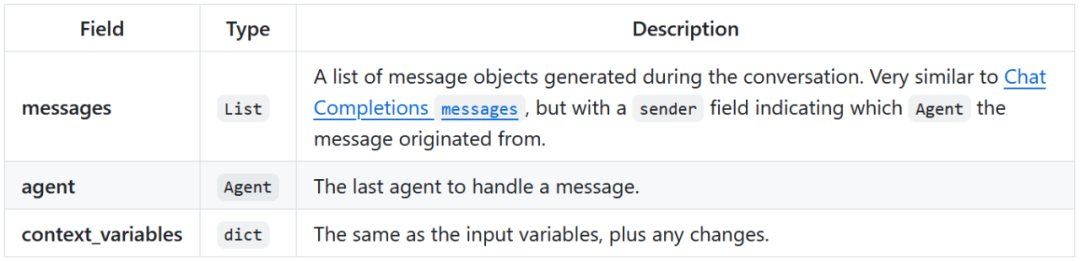
响应字段
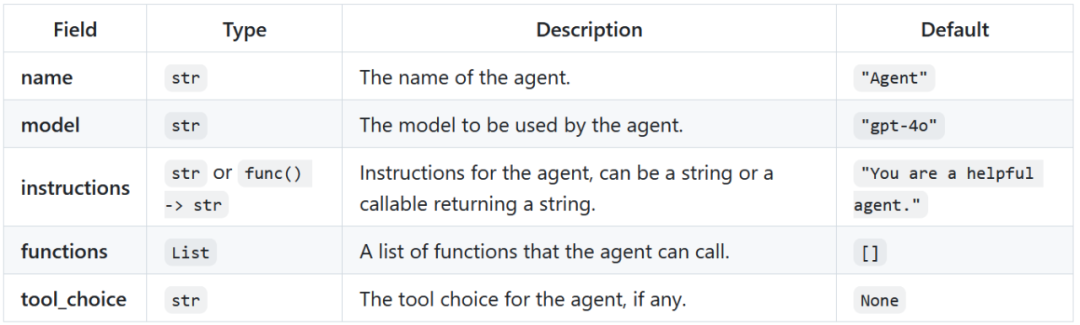
agent = Agent(instructions="You are a helpful agent.")
def instructions(context_variables):user_name = context_variables["user_name"]return f"Help the user, {user_name}, do whatever they want."agent = Agent(instructions=instructions)response = client.run(agent=agent,messages=[{"role":"user", "content": "Hi!"}],context_variables={"user_name":"John"})print(response.messages[-1]["content"])
Hi John, how can I assist you today?
def greet(context_variables, language):user_name = context_variables["user_name"]greeting = "Hola" if language.lower() == "spanish" else "Hello"print(f"{greeting}, {user_name}!")return "Done"agent = Agent(functions=[print_hello])client.run(agent=agent,messages=[{"role": "user", "content": "Usa greet() por favor."}],context_variables={"user_name": "John"})
Hola, John!如果某个 Agent 函数调用出错(缺少函数、参数错误等),则会在聊天之中附加一条报错响应,以便 Agent 恢复正常。如果 Ageny 调用多个函数,则按顺序执行它们。交接和更新上下文变量通过在返回的函数中包含一个 Agent,可将执行过程交接给这个 Agent。sales_agent = Agent(name="Sales Agent")def transfer_to_sales():return sales_agentagent = Agent(functions=[transfer_to_sales])response = client.run(agent, [{"role":"user", "content":"Transfer me to sales."}])print(response.agent.name)
Sales Agent
sales_agent = Agent(name="Sales Agent")def talk_to_sales():print("Hello, World!")return Result(value="Done",agent=sales_agent,context_variables={"department": "sales"})agent = Agent(functions=[talk_to_sales])response = client.run(agent=agent,messages=[{"role": "user", "content": "Transfer me to sales"}],context_variables={"user_name": "John"})print(response.agent.name)print(response.context_variables)
Sales Agent{'department': 'sales', 'user_name': 'John'}
def greet(name, age: int, location: str = "New York"):"""Greets the user. Make sure to get their name and age before calling.Args:name: Name of the user.age: Age of the user.location: Best place on earth."""print(f"Hello {name}, glad you are {age} in {location}!"){"type": "function","function": {"name": "greet","description": "Greets the user. Make sure to get their name and age before calling.nnArgs:n name: Name of the user.n age: Age of the user.n location: Best place on earth.","parameters": {"type": "object","properties": {"name": {"type": "string"},"age": {"type": "integer"},"location": {"type": "string"}},"required": ["name", "age"]}}}
stream = client.run(agent, messages, stream=True)for chunk in stream:print(chunk)
以上就是OpenAI今天Open了一下:开源多智能体框架Swarm的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/416690.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















