
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇论文已被NeurIPS 2024接收,论文第一作者郑传阳来自香港中文大学,共同作者包括新加波国立大学高伊杭,诺亚实验室石涵、任晓哲、蒋欣、李震国,香港中文大学 黄敏斌、 李靖瑶,香港大学熊璟,香港浸会大学吴国宝,香港中文大学李煜
在当今的人工智能领域,Transformer 模型已成为解决诸多自然语言处理任务的核心。然而,Transformer 模型在处理长文本时常常遇到性能瓶颈。传统的位置编码方法,如绝对位置编码(APE)和相对位置编码(RPE),虽然在许多任务中表现良好,但其固定性限制了其在处理超长文本时的适应性和灵活性。
为了应对这一挑战,提出了一种全新的位置编码方法:Data-Adaptive Positional Encoding(DAPE)。DAPE 通过动态调整位置编码,使其能够根据输入上下文和学习到的固定先验进行自适应调整。这种创新方法不仅保留了局部和反局部信息,还在模型训练长度和长度泛化方面显著提升了模型性能。相关研究成果已被 NeurIPS 2024 收录。

论文地址: https://arxiv.org/abs/2405.14722
代码地址: https://github.com/chuanyang-Zheng/DAPE
背景与挑战
Transformer 模型的成功离不开其强大的序列处理能力,但在超出其训练长度时,其性能往往会显著下降。这主要是由于传统的位置编码方法(如 APE 和 RPE)在处理长文本时的固定性和缺乏适应性,导致模型难以有效捕捉长距离的依赖关系。最近的一些工作(e.g. Kerple, FIRE, BiPE)指出 transformer 通过合适的位置编码可以提升模型长度外推的能力,但是在外推长度达到训练长度 (512) 16 倍 (8192) 的时候,依然出现了 perplexity 的上升。相反的,DAPE 做到了在 128 长度上训练,在 8192 乃至 16384 上拿到了更低的困惑度(perplexity)。
方法
Additive Relative Position Encoding
对于大多数这些加性相对位置编码(RPE)方法,(softmax 之前的) 注意力 logits 的计算可以通过以下公式统一表示: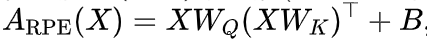 ,其中,偏置矩阵
,其中,偏置矩阵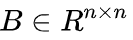 由位置编码函数
由位置编码函数 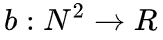 生成,
生成,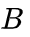 的
的 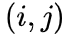 项定义为
项定义为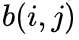 。
。
不同的b的公式和参数化方法导致了各种 RPE 的变体。一些支持任意序列长度的方法包括 T5 的 RPE,ALiBi,Kerple,Sandwich,以及 FIRE。加性 RPE 的示例包括:
(1) ALiBi: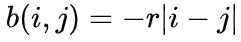 ,其中标量
,其中标量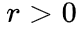 为超参数;
为超参数;
(2) Kerple: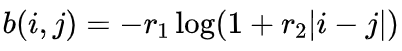 ,其中
,其中 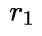 和
和 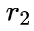 是两个可学习的参数;
是两个可学习的参数;
(3) FIRE: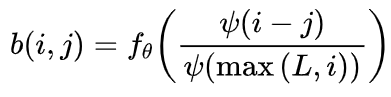 ,其中位置编码函数
,其中位置编码函数 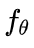 由参数
由参数 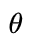 从数据中学习,
从数据中学习,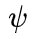 是一个转换函数,旨在为局部位置分配更多的模型能力。
是一个转换函数,旨在为局部位置分配更多的模型能力。
之前方法的局限
这些位置编码的共同特征是它们是预定义且静态的。具体来说,它们在各种任务和模型中都是固定的,这可能导致它们无法有效适应不同的输入长度和上下文。为了解决这个问题,近期的研究提出了相对位置编码的函数插值方法(FIRE),它利用神经网络从输入位置到位置偏置的隐式映射进行学习。尽管 FIRE 使用多层感知机(MLP)来学习位置嵌入,但这些嵌入在训练完成后在不同任务中仍然是固定的。从直观上看,所学习的静态位置编码(如 Kerple 和 FIRE)是所有训练样本的平均最优解。因此,尽管它们通常是有效的,但对于任何特定实例来说,它们本质上是次优的。这种静态特性限制了它们在训练上下文以外的各种实际场景中的灵活性和适用性。
Data-Adaptive Positional Encoding
本文受静态位置编码局限性的启发,提出了一种数据自适应位置编码(DAPE)方法。DAPE 根据语义信息(如当前的注意力值)和位置信息动态调整位置编码。由于 MLP 具有普适逼近能力,本文采用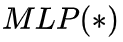 来根据注意力动态调整位置编码。我们注意到 DAPE 与所有加性相对位置编码兼容,并在可解释性和易于实现方面具有优势。所提出的 DAPE 结合了语义信息和位置信息,使得位置编码能够根据输入数据进行自适应调整。这种适应性使 DAPE 能够克服静态编码的局限性,通过对每个具体输入数据的动态调整,实现相对最优的性能。据我们所知,这是在 Transformer 架构中首次引入的基于数据语义依赖的自适应位置编码方法。
来根据注意力动态调整位置编码。我们注意到 DAPE 与所有加性相对位置编码兼容,并在可解释性和易于实现方面具有优势。所提出的 DAPE 结合了语义信息和位置信息,使得位置编码能够根据输入数据进行自适应调整。这种适应性使 DAPE 能够克服静态编码的局限性,通过对每个具体输入数据的动态调整,实现相对最优的性能。据我们所知,这是在 Transformer 架构中首次引入的基于数据语义依赖的自适应位置编码方法。
在这里,我们使用注意力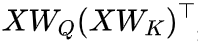 来表示注意力语义信息,使用位置偏置矩阵B(例如 ALiBi, Kerple 和 FIRE)来捕捉位置信息。然后,数据自适应 PE 可表示为
来表示注意力语义信息,使用位置偏置矩阵B(例如 ALiBi, Kerple 和 FIRE)来捕捉位置信息。然后,数据自适应 PE 可表示为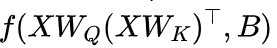 ,其中
,其中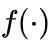 是一个隐式函数,它将语义和位置信息整合为所需的位置编码。因此,结合 DAPE 的 softmax 前注意力 logit 公式如下:
是一个隐式函数,它将语义和位置信息整合为所需的位置编码。因此,结合 DAPE 的 softmax 前注意力 logit 公式如下:
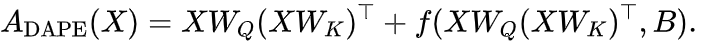
这里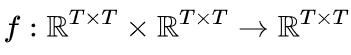 是逐元素函数。实际上,我们采用一个两层
是逐元素函数。实际上,我们采用一个两层 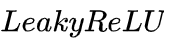 神经网络来参数化
神经网络来参数化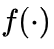 ,因为它具有普适逼近性。所有参数在训练过程中直接从数据中学习。这种架构允许
,因为它具有普适逼近性。所有参数在训练过程中直接从数据中学习。这种架构允许 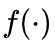 根据输入上下文动态调整位置嵌入,确保编码方法既具有自适应性又依赖于输入数据。
根据输入上下文动态调整位置嵌入,确保编码方法既具有自适应性又依赖于输入数据。
在自然语言任务中,DAPE 的设计旨在捕捉 token 之间复杂的关系。Arora et al. 指出 aassociate recall 占据了 Transformer 模型、基于 RNN 的模型和卷积模型之间困惑度(perplexity)差异的大部分。比如,我们考虑一个在长段落中 “Hakuna” 总是紧跟 “Matata” 的一致配对。这种模式表明模型对位置信息的依赖减少,而更注重增强词嵌入的相似性,从而使得 “Hakuna” 可以有效地与前面的 “Matata” 联系起来。同样,在涉及长上下文理解和搜索的任务中,注意力机制应该优先考虑语义相似性,而不是被与位置编码相关的信息所掩盖,因为在较长距离上位置编码的相关性可能较低。因此,Transformer 应能够保存信息而不受位置距离的过度影响。相反,一个满意的 PE 应该结合语义和位置信息。因此,基于语义依赖的位置编码方法是更优的,预计能够提升模型性能。
实验结果
 盘古大模型
盘古大模型
华为云推出的一系列高性能人工智能大模型
 35 查看详情
35 查看详情 
相比于之前的方法
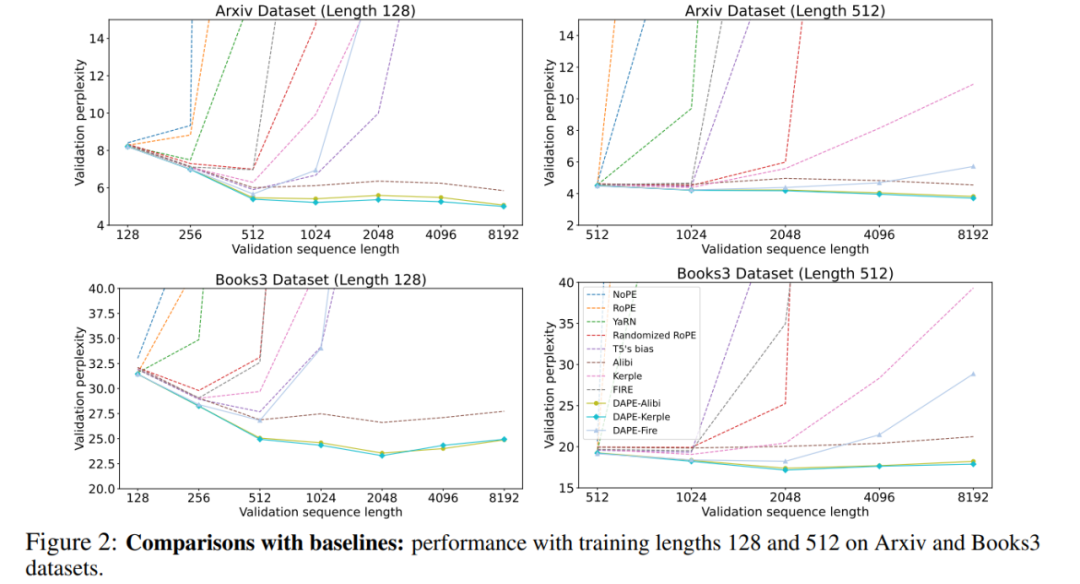
在训练长度内更好的效果。DAPE 增强了在序列长度内部的表现,表明其较低的困惑度可能来自对整个句子的充分利用,而不是忽视长距离信息。与 ALiBi、Kerple 和 FIRE 相比,改进后的版本 DAPE-ALiBi、DAPE-Kerple 和 DAPE-FIRE 在序列长度内部的表现始终显著更好。随着序列长度的增加,ALiBi 往往从全局注意力过渡到几乎局部的注意力,这就是为什么 ALiBi 在训练长度内的表现比大多数基线差,但在超出训练长度后表现更好的原因。结果表明 DAPE 在序列长度内部的优越表现具有统计显著性,p 值小于 0.05。因此,在不同训练长度 (长度 128,512 以及 1024) 中的表现表明,DAPE 较低的困惑度是由于它有效利用了整个序列,而不是仅关注局部部分并忽视长距离信息。
在长度外推上更好的效果。与 ALiBi、Kerple 和 FIRE 相比,DAPE 显著提升了长度外推(length extrapolation)性能。在不同长度的训练和评估中,DAPE-Kerple 明显超越 Kerple 等竞争对手。在 Arxiv 数据集上,训练长度为 128 时,DAPE-Kerple 在评估长度为 8192 时达到了惊人的低困惑度 5.00,而 Kerple 的困惑度为 31.93。同样,在 Books3 数据集上,训练长度为 512 时,DAPE-Kerple 在相同的扩展评估长度下的困惑度为 17.88,远远优于 Kerple 的 39.31。这些结果证明,DAPE 通过其语义适应性和灵活性,持续提升了超出训练长度的性能,超越了静态位置编码方法。
在更大模型上上保持更好的结果
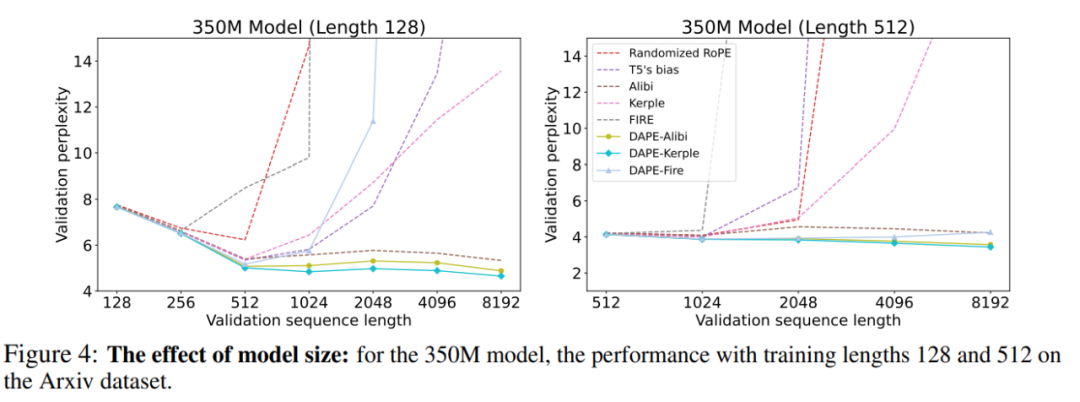
DAPE 在更大模型上有效。随着模型规模的增长(如图 4 所示),DAPE 在性能指标上持续展现出提升。当模型规模从 125M 增加到 350M 时,DAPE-ALiBi 在评估序列长度为 8192(训练长度为 512)时的困惑度显著下降,从 3.82 降至 3.57。这些数值明显小于原始 ALiBi 的困惑度,ALiBi 从 4.54 降至 4.21,表明了 DAPE 的强劲性能提升。此外,DAPE-Kerple 大幅减少了 Kerple 的困惑度,从最初的 22.76 降至令人印象深刻的 3.43。在 2.7B 和 6.7B 的模型上,DAPE-Kerple 依然取得了最低的 perplexity。这些结果证实了 DAPE 即使在模型规模增大的情况下仍能保持其有效性,并继续表现出色,主要得益于其采用了语义自适应的位置编码方法。
不同 hidden dimension 情况下的表现
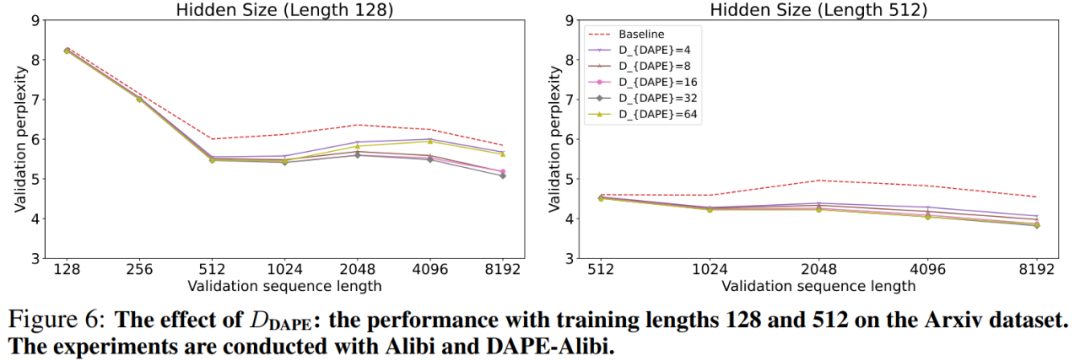
即使是较小的 hidden dimension 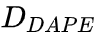 也能提升性能。实验在 ALiBi 和 DAPE-ALiBi 上进行。如附录图 6 所示,当训练长度为 128,且
也能提升性能。实验在 ALiBi 和 DAPE-ALiBi 上进行。如附录图 6 所示,当训练长度为 128,且 设置为 4 时,DAPE-ALiBi 在评估长度为 128 时的困惑度为 8.25,在评估长度为 8192 时为 5.67,均优于 ALiBi 的 8.31 和 5.85。不论 hiddien dimension 设置为 4、16、32 或 64,DAPE 的性能在所有评估长度上都优于原始 ALiBi。这表明即使使用较小的,DAPE 仍然具有有效性。
设置为 4 时,DAPE-ALiBi 在评估长度为 128 时的困惑度为 8.25,在评估长度为 8192 时为 5.67,均优于 ALiBi 的 8.31 和 5.85。不论 hiddien dimension 设置为 4、16、32 或 64,DAPE 的性能在所有评估长度上都优于原始 ALiBi。这表明即使使用较小的,DAPE 仍然具有有效性。
关于偏置矩阵 Bias Matrix 的消融实验
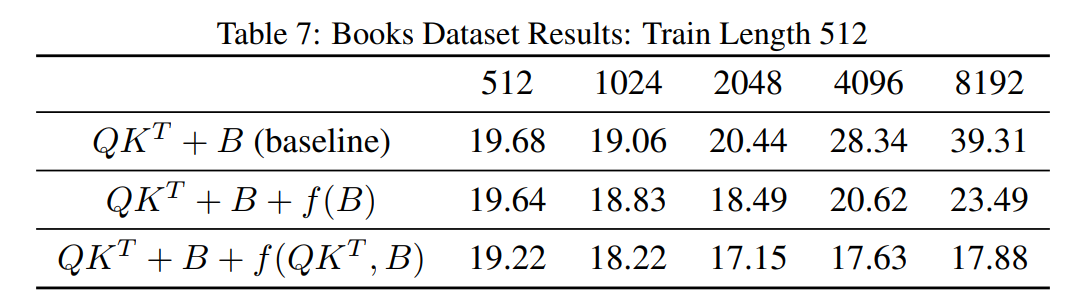
我们进一步对函数 f 进行了消融研究,证明 f 有助于增强偏置矩阵。DAPE(动态位置编码)改进了偏置矩阵,使得最终的注意力矩阵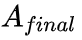 得到了提升,而
得到了提升,而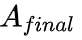 用于计算
用于计算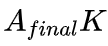 。对于未见过的位置,偏置矩阵 B 部分可以一定程度上处理(FIRE 将问题转化为插值),但不够准确,因此 DAPE 通过注意力得分帮助增强偏置矩阵 B。实验结果表明两点:1).
。对于未见过的位置,偏置矩阵 B 部分可以一定程度上处理(FIRE 将问题转化为插值),但不够准确,因此 DAPE 通过注意力得分帮助增强偏置矩阵 B。实验结果表明两点:1).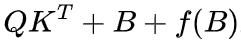 优于
优于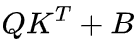 ,这表明通过提高偏置矩阵的表达能力可以获得更好的效果;2). DAPE 的
,这表明通过提高偏置矩阵的表达能力可以获得更好的效果;2). DAPE 的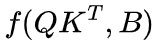 优于简单的
优于简单的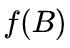 ,这表明上下文自适应是重要的。
,这表明上下文自适应是重要的。
在 CHE 基准上的表现
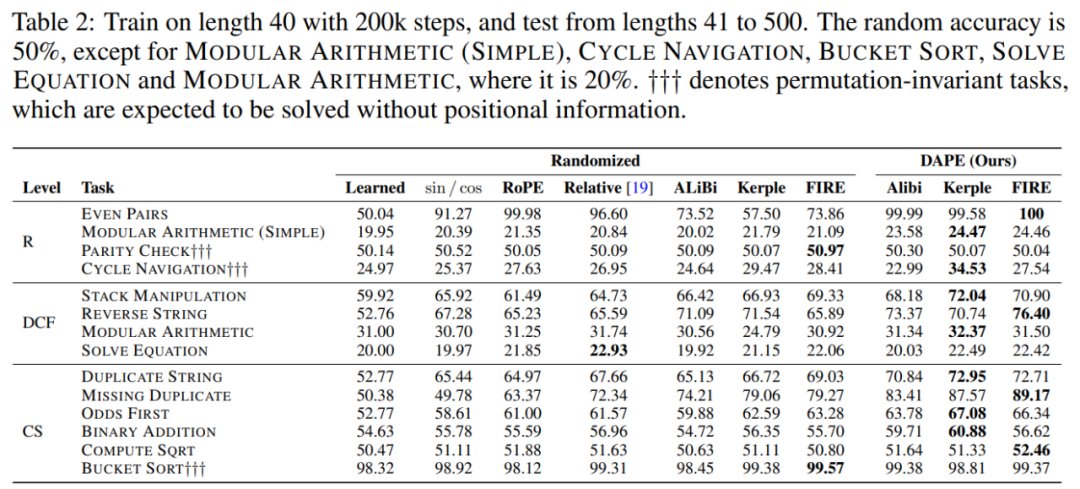
DAPE 在需要位置信息的任务中表现更好。DAPE(与 Kerple 和 FIRE 结合)在 11 项需要位置信息的任务中有 10 项表现最佳,并在 Solve Equation 任务中取得了第二好的表现。这凸显了 DAPE 通过语义适应性处理需要位置信息的任务的有效性。
可视化结果
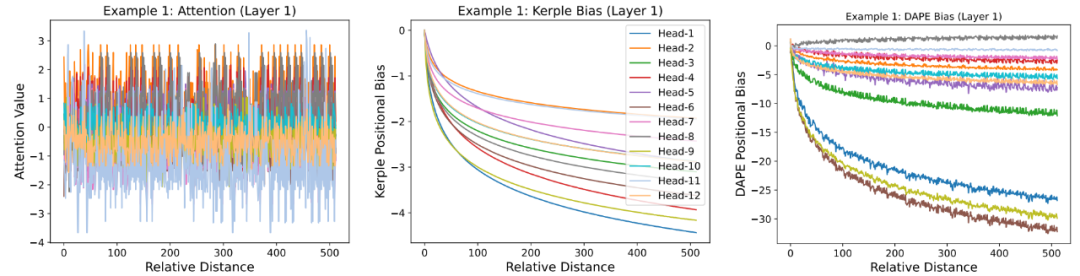
DAPE 展现 local pattern 和 anti-local pattern. 我们在图 1 中绘制了第 8192 个位置的查询 token 的学习位置编码偏置,涵盖了所选层中的所有注意力头。我们想强调 DAPE 的两个特点。首先,与固定的局部归纳偏置(如 Kerple 和 ALiBi)相比,DAPE 的偏置矩阵在不同的注意力头中,能够学习到既包含局部注意力模式,又包含 “反局部” 注意力模式 (DAPE Bias Head-8),强调更远的 key(类似于 FIRE)。其次,与为所有注意力固定的静态偏置相比,DAPE 的偏置矩阵可以根据不同的注意力值动态调整。
代码实现

未来展望
通过引入语义和位置信息的结合,DAPE 极大地提升了 Transformer 模型在长文本处理上的表现。同时,应将继续优化 DAPE 的方法,提高其计算效率和适应性,探索其在更多实际应用中的潜力。
以上就是NeurIPS 2024 | Transformer长度外推,全新位置编码DAPE大幅提升模型性能的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/417012.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















