
meta fair 田渊栋参与的研究项目在上个月获得了广泛好评。在他们的论文《mobilellm: optimizing sub-billion parameter language models for on-device use cases》中,他们开始探讨如何优化10亿以下参数的小型模型,旨在实现在移动设备上运行大型语言模型的目标。
3 月 6 日,田渊栋团队发布了最新的研究成果,这次专注于提高LLM内存的效率。除了田渊栋本人,研究团队还包括来自加州理工学院、德克萨斯大学奥斯汀分校以及CMU的研究人员。这项研究旨在进一步优化LLM内存的性能,为未来的技术发展提供支持和指导。
他们联合提出了一种名为 GaLore(Gradient Low-Rank Projection)的训练策略,这种策略允许全参数学习,相比于 LoRA 等常见的低秩自适应方法,GaLore具有更高的内存效率。
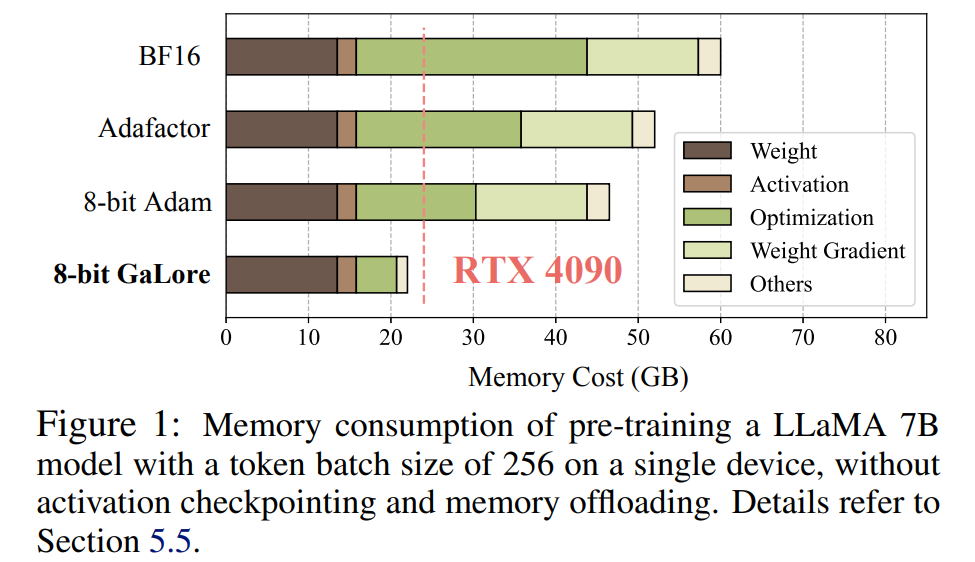
这项研究首次表明,在配备 24GB 内存的消费级 GPU(例如 NVIDIA RTX 4090)上,可以成功地进行 7B 模型的预训练,而无需使用模型并行、检查点或卸载策略。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/abs/2403.03507
论文标题:GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
 盘古大模型
盘古大模型
华为云推出的一系列高性能人工智能大模型
 35 查看详情
35 查看详情 
接下来我们看看文章主要内容。
当前,大型语言模型(LLM)在多个领域展现出卓越的潜力,但我们也必须正视一个现实问题,那就是预训练和微调LLM不仅需要大量的计算资源,还需要大量的内存支持。
LLM 对内存的需求不仅包括以亿计算的参数,还包括梯度和 Optimizer States(例如 Adam 中的梯度动量和方差),这些参数可能大于存储本身。举例来说,使用单个批大小且从头开始预训练的 LLaMA 7B ,需要至少 58 GB 内存(14 GB 用于可训练参数,42 GB 用于 Adam Optimizer States 和权重梯度,2 GB 用于激活)。这使得训练 LLM 在消费级 GPU(例如具有 24GB 内存的 NVIDIA RTX 4090)上变得不可行。
为了解决上述问题,研究人员不断开发各种优化技术,以减少预训练和微调期间的内存使用。
该方法在 Optimizer States 下将内存使用量减少了 65.5%,同时还能保持在 LLaMA 1B 和 7B 架构上使用最多 19.7B token 的 C4 数据集进行预训练的效率和性能,以及在 GLUE 任务上微调 RoBERTa 的效率和性能。与 BF16 基准相比,8-bit GaLore 进一步减少了优化器内存达 82.5%,总训练内存减少了 63.3%。
看到这项研究后,网友表示:「是时候忘记云、忘记 HPC 了,有了 GaLore,所有的 AI4Science 都将在 2000 美元的消费级 GPU 上完成。」
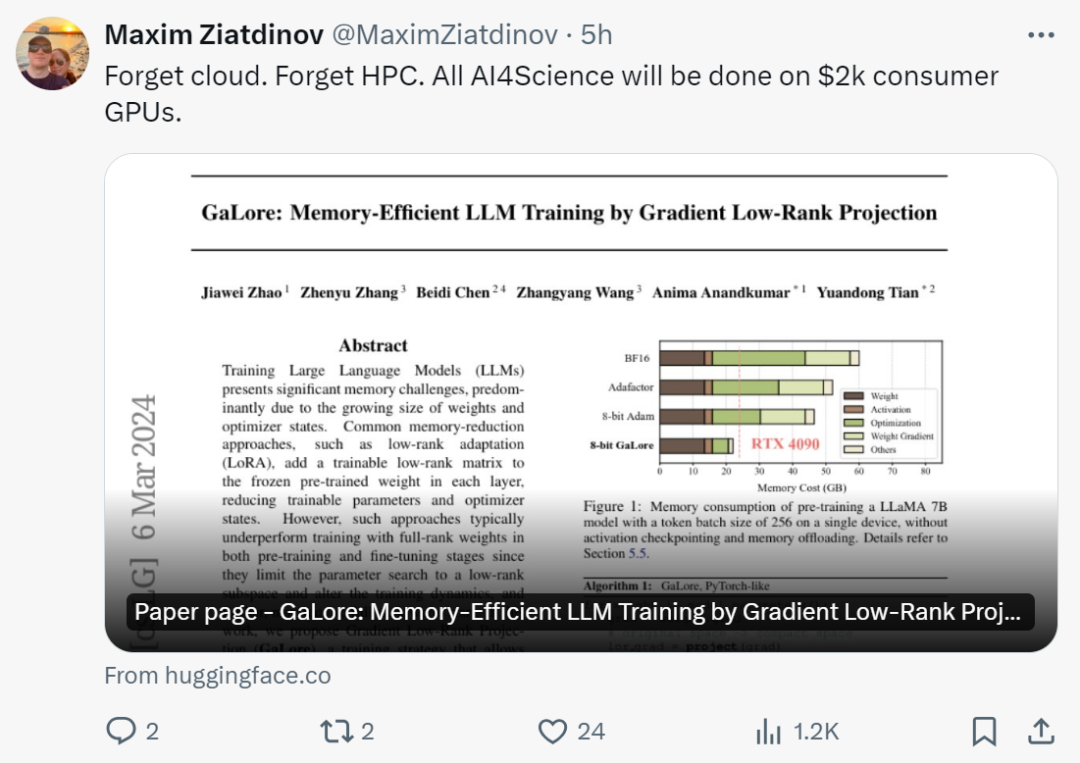
田渊栋表示:「有了 GaLore,现在可以在具有 24G 内存的 NVidia RTX 4090s 中预训练 7B 模型了。
我们没有像 LoRA 那样假设低秩权重结构,而是证明权重梯度自然是低秩的,因此可以投影到(变化的)低维空间中。因此,我们同时节省了梯度、Adam 动量和方差的内存。
因此,与 LoRA 不同,GaLore 不会改变训练动态,可用于从头开始预训练 7B 模型,无需任何内存消耗的预热。GaLore 也可用于进行微调,产生与 LoRA 相当的结果」。
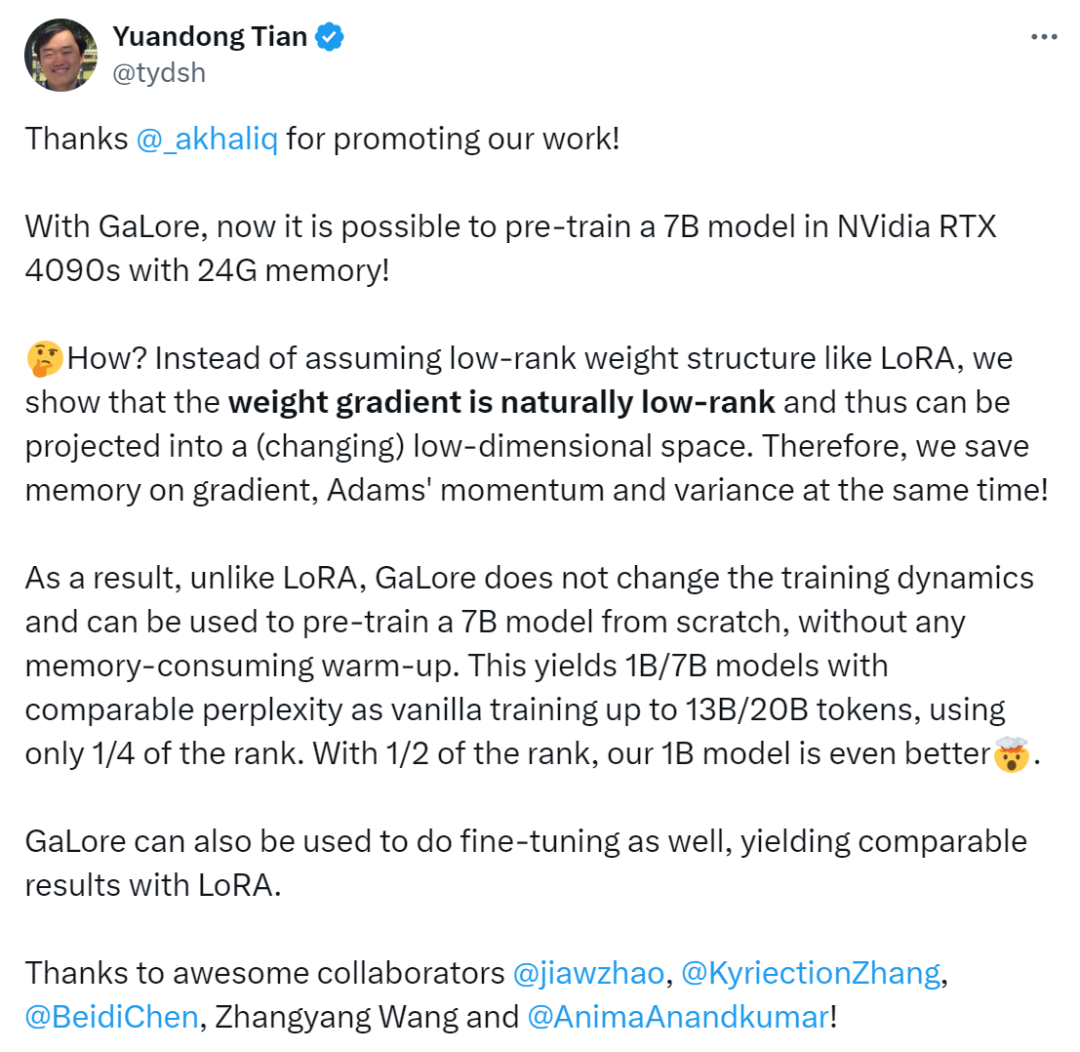
方法介绍
前面已经提到,GaLore 是一种允许全参数学习的训练策略,但比常见的低秩自适应方法(例如 LoRA)更节省内存。GaLore 关键思想是利用权重矩阵 W 的梯度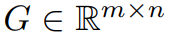 缓慢变化的低秩结构,而不是试图将权重矩阵直接近似为低秩形式。
缓慢变化的低秩结构,而不是试图将权重矩阵直接近似为低秩形式。
本文首先从理论上证明了梯度矩阵 G 在训练过程中会变成低秩,在理论的基础上,本文用 GaLore 来计算两个投影矩阵 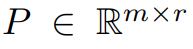 和
和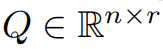 将梯度矩阵 G 投影成低秩形式 P^⊤GQ。在这种情况下,依赖于组件梯度统计的 Optimizer States 的内存成本可以大大减少。如表 1 所示,GaLore 的内存效率比 LoRA 更高。实际上,与 LoRA 相比,在预训练期间,这可减少高达 30% 的内存。
将梯度矩阵 G 投影成低秩形式 P^⊤GQ。在这种情况下,依赖于组件梯度统计的 Optimizer States 的内存成本可以大大减少。如表 1 所示,GaLore 的内存效率比 LoRA 更高。实际上,与 LoRA 相比,在预训练期间,这可减少高达 30% 的内存。

本文证明了 GaLore 在预训练和微调方面表现良好。当在 C4 数据集上预训练 LLaMA 7B 时,8-bit GaLore 结合了 8-bit 优化器和逐层权重更新技术,实现了与全秩相当的性能,并且 optimizer state 的内存成本不到 10%。
值得注意的是,对于预训练,GaLore 在整个训练过程中保持低内存,而不需要像 ReLoRA 那样进行全秩训练。得益于 GaLore 的内存效率,这是首次可以在具有 24GB 内存的单个 GPU(例如,在 NVIDIA RTX 4090 上)上从头开始训练 LLaMA 7B,而无需任何昂贵的内存卸载技术(图 1)。
作为一种梯度投影方法,GaLore 与优化器的选择无关,只需两行代码即可轻松插入现有优化器,如算法 1 所示。

下图为将 GaLore 应用于 Adam 的算法:

实验及结果
研究者对 GaLore 的预训练和 LLM 的微调进行了评估。所有实验均在英伟达 A100 GPU 上进行。
为了评估其性能,研究者应用 GaLore 在 C4 数据集上训练基于 LLaMA 的大型语言模型。C4 数据集是 Common Crawl 网络抓取语料库的一个巨大的净化版本,主要用于预训练语言模型和单词表征。为了最好地模拟实际的预训练场景,研究者在不重复数据的情况下,对足够大的数据量进行训练,模型大小范围可达 70 亿个参数。
本文沿用了 Lialin 等人的实验设置,采用了基于 LLaMA3 的架构,带有 RMSNorm 和 SwiGLU 激活。对于每种模型大小,除了学习率之外,他们使用了相同的超参数集,并以 BF16 格式运行所有实验,以减少内存使用,同时在计算预算相同的情况下调整每种方法的学习率,并报告最佳性能。
此外,研究者使用 GLUE 任务作为 GaLore 与 LoRA 进行内存高效微调的基准。GLUE 是评估 NLP 模型在各种任务中性能的基准,包括情感分析、问题解答和文本关联。
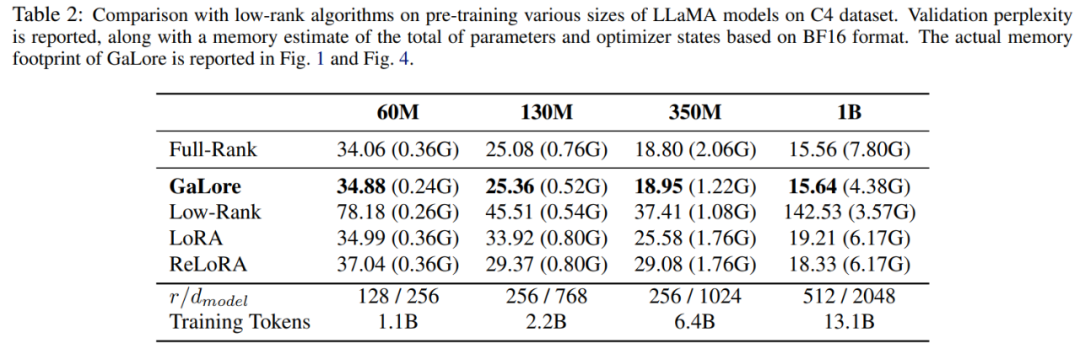
本文首先使用 Adam 优化器将 GaLore 与现有的低秩方法进行了比较,结果如表 2 所示。
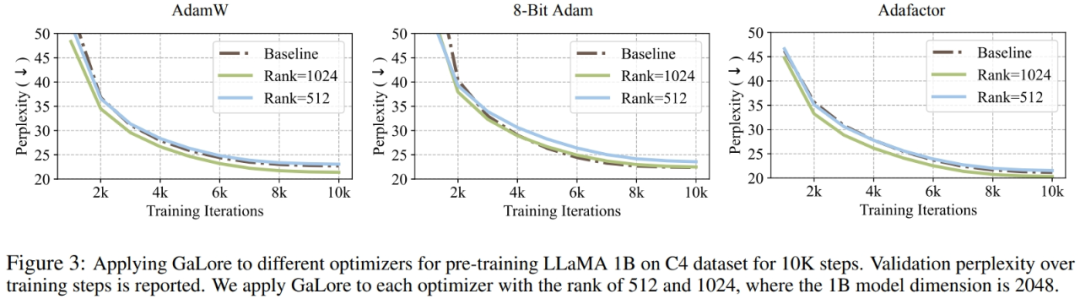
研究者证明,GaLore 可以应用于各种学习算法,尤其是内存高效的优化器,以进一步减少内存占用。研究者将 GaLore 应用于 AdamW、8 bit Adam 和 Adafactor 优化器。他们采用一阶统计的 Adafactor,以避免性能下降。
实验在具有 10K 训练步数的 LLaMA 1B 架构上对它们进行了评估,调整了每种设置的学习率,并报告了最佳性能。如图 3 所示,下图表明,GaLore 可适用于流行的优化器,例如 AdamW、8-bit Adam 和 Adafactor。此外,引入极少数超参数不会影响 GaLore 的性能。
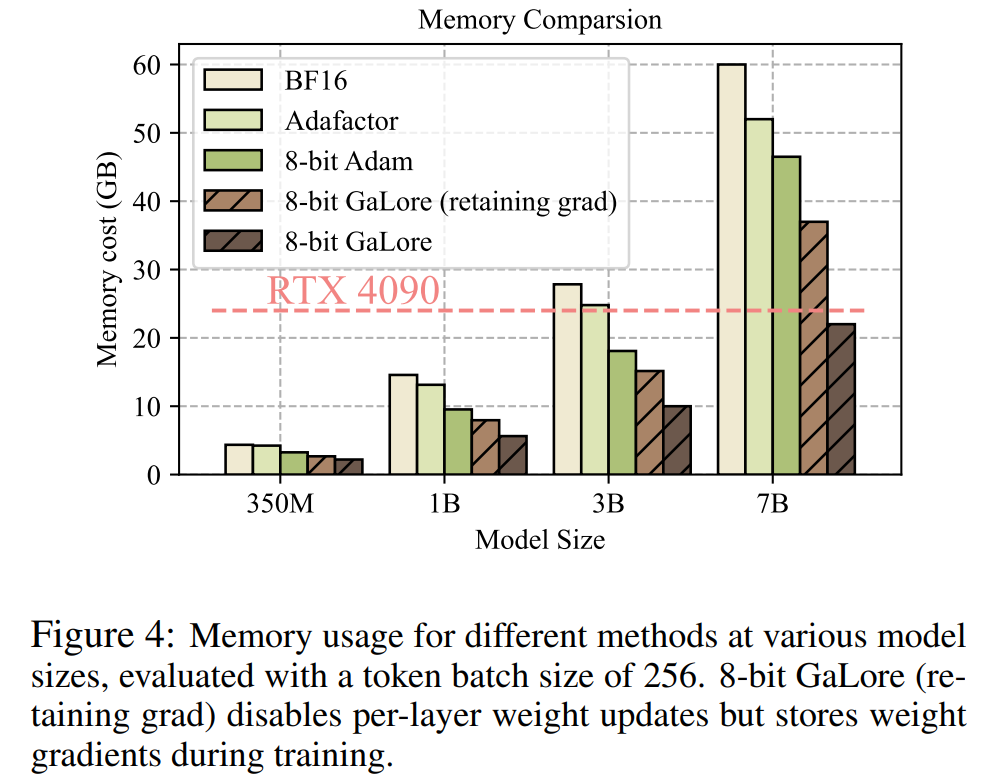
如表 4 所示,在大多数任务中,GaLore 都能以更少的内存占用获得比 LoRA 更高的性能。这表明,GaLore 可以作为一种全栈内存高效训练策略,用于 LLM 预训练和微调。
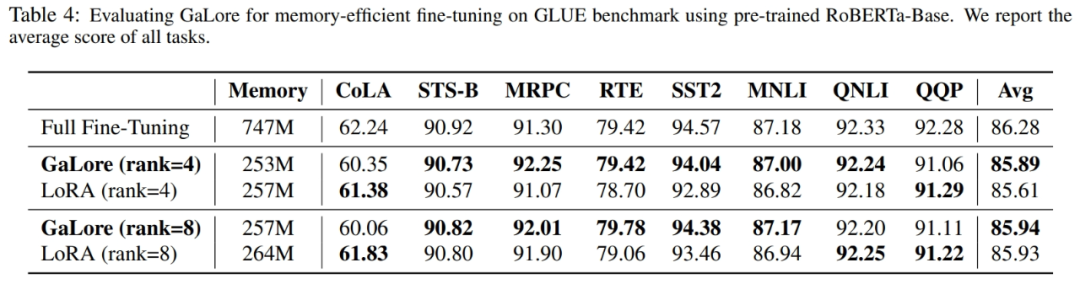
如图 4 所示,与 BF16 基准和 8 bit Adam 相比,8 bit GaLore 所需的内存要少得多,在预训练 LLaMA 7B 时仅需 22.0G 内存,且每个 GPU 的 token 批量较小(最多 500 个 token)。
更多技术细节,请阅读论文原文。
以上就是田渊栋等人新作:突破内存瓶颈,让一块4090预训练7B大模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/425770.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






























