
本文聚焦语义多模态图像合成(SMIS)任务,旨在通过特定类控制器调整对应区域生成图像,且不影响其他部分。针对现有方法局限,提出GroupDNet,利用组卷积并逐步减少解码器组数,提升可控性与生成质量。实验表明其优越性,还能支持多种合成应用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文分享
PS:哪里觉得不理解大家可以一起探讨
论文题目:Semantically Multi-modal Image Synthesis
题目翻译:多模态语义信息图像合成
论文地址:https://arxiv.org/abs/2003.12697
论文代码地址: https://github.com/Seanseattle/SMIS
相信看到这个题目大家有点懵逼,于是我打算让大家看看论文开始的摘要。
1. Abstract
在本文中,我们着重于语义多模态图像合成(SMIS)任务,即在语义层次上生成多模态图像。以前的工作试图使用多个特定于类的生成器,限制其在具有少量类的数据集中的使用。相反,我们提出了一种新的群减少网络(GroupDNet),它利用生成器中的组卷积,并逐步减少解码器中卷积的组数。因此,GroupDNet在将语义标签转换为自然图像方面具有更多的可控性,并且对于具有许多类的数据集具有合理的高质量产量。在几个具有挑战性的数据集上进行的实验证明了GroupDNet在执行SMIS任务方面的优越性。我们还表明,GroupDNet能够执行广泛的有趣的合成应用程序。 在本文中,我们着重于语义多模态图像合成(SMIS)任务,即在语义层次上生成多模态图像。以前的工作试图使用多个特定于类的生成器,限制其在具有少量类的数据集中的使用。相反,我们提出了一种新的群减少网络(GroupDNet),它利用生成器中的组卷积,并逐步减少解码器中卷积的组数。因此,GroupDNet在将语义标签转换为自然图像方面具有更多的可控性,并且对于具有许多类的数据集具有合理的高质量产量。在几个具有挑战性的数据集上进行的实验证明了GroupDNet在执行SMIS任务方面的优越性。我们还表明,GroupDNet能够执行广泛的有趣的合成应用程序。
这个时候大家会发现关键词就出现了,SMIS。这篇论文就提出了一种模型架构更好的实现这个任务。因此接下来我带着大家继续阅读什么叫做SMIS任务。
2. SMIS任务解释
只是想象一下一个来自人类解析映射的内容创建场景。在语义到图像的转换模型的帮助下,解析映射(就是语义分割信息)可以转换为每个真实的图片。一般来说看起来不错,但生成的衣服上身不适合你的口味。然后问题就出现了,要么这些模型不支持多模态合成,要么当这些模型改变了上身时,其他部分也会随之变化。这些都不能满足你的意图。总之,这个用户可控的内容创建场景可以被解释为执行一个任务,在语义级别上产生多模态结果,而其他语义部分没有被触及。 我们将这个任务总结为:语义多模态图像合成(SMIS)。对于每个语义,我们都有它特定的控制器。通过调整特定类的控制器,只有相应的区域被相应地改变。 这里论文举了一个小小的例子,见figure 1。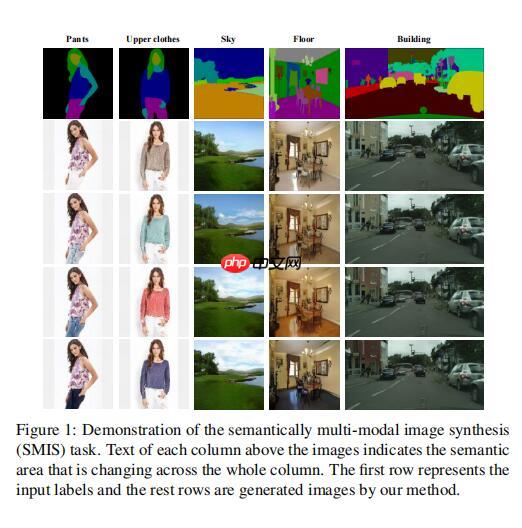
对于SMIS挑战详细阐述
设M表示一个语义分割掩码。假设在数据集中有C个语义类。H和W分别表示图像的高度和宽度。作为一个非常明了的方式去引导label-to-image模型变换。 生成器G需要M作为条件输入来生成图像。然而,为了支持多模态生成,我们需要另一个输入源来控制生成的多样性。通常,我们使用一个编码器来提取一个潜在代码Z作为控制器。在接收到这两个输入后,可以通过O=G(Z,M)产生图像输出O。然而,在语义多模态图像合成(SMIS)任务中,我们的目标是通过干扰特定类的潜在代码来产生语义不同的图像,该代码独立地控制相应类的多样性。
对于SMIS任务的挑战,关键是将潜在代码划分为一系列特定于类的潜在代码,每个潜在代码只控制一个特定的语义类的生成。传统的卷积编码器并不是一个最优的选择,因为所有类的特征表示都是内部纠缠在潜在的代码中。即使我们有特定于类的潜在代码,如何使用这些代码仍然存在问题。正如我们将在实验部分所说明的,简单地用特定于类的代码替换spade[38]中的原始潜在代码,处理SMIS任务的能力有限。这一现象促使我们需要在编码器和解码器中进行一些架构修改,以更有效地完成任务。
好了,此刻我已经把任务给描述清楚了,那么这个时候面对这个任务,我们的解决思路是什么,首先是剖析这个问题,SMIS和一般的语义生成任务有什么不同?它要求更细腻的语义控制。我认为有特征解耦的那个味道,像素级特征控制(那个英特尔的editgan,论文地址为(https://arxiv.org/pdf/2111.03186.pdf).
3. 面对问题思考
1. 首先第一种思路是基于每个语义类标签创建一个子网络,这样每一个语义都由一个模型控制,其潜在的思想是独立地处理每个类,然后融合不同子网的结果。为简单起见,我们将这种网络称为多重网络(MulNet)。这个想法很直接,但是不由自主的会出现问题:
1. 如果这个语义生成具体任务有100类那就需要100个子网络,就是这个子网络数量会随着类别数量增加而增加,参数增加的很快,相应训练方面也会有很多问题,训练时长,资源等,这种类型的方法很快就会面临性能的下降,训练时间的增加和计算资源消耗的线性增加。2. 各个语义信息部分的互动性较差。
2. 使用语义生成的SPADE,但是这个语义生成的SPADE原始框架很难进行控制单个语义。(这个SPADE就是这篇论文的backbone,然后论文就是基于spade进行修改)
3. 另一个有类似想法的替代方法是在整个网络中使用group convolutions。用group convolutions替换encoder和decoder中的所有卷积,并将组数设置为 class number,我们把这种网络称作为GroupNet。如果每一Group的通道数等于单个MulNet子网络中对应的通道数,则在理论上等价于MulNet。这里提到一个叫做GroupNet,卷积组数和标签类别相同.试图通过这样实现单个语义分开控制,就是nn.conv2d(groups = num_class)。
4. 然后呢,本文使用的是叫GroupDNet,这个和GroupNet的主要区别是decoder中groups数的单调减少。
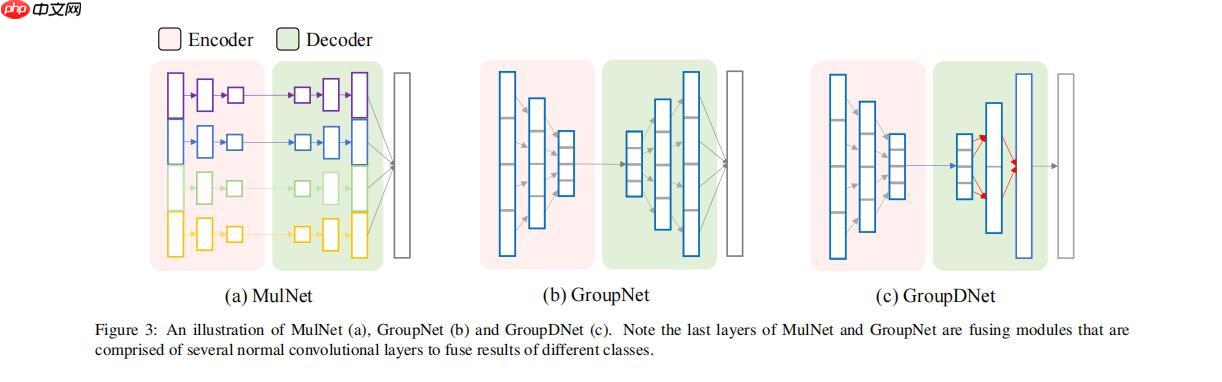
这个时候吧,或许会有同学会问这个groupdnet改变思路如此简单会好用吗?
于是作者说了这个朴实操作背后的几层深意。
class balance。值得注意的是,不同的类有不同数量的实例[32,5,55],并且需要不同的网络容量来建模这些类。MulNet and GroupNet需要找到一个合适的网络设计来平衡所有的类。更重要的是,并非所有的类都出现在一个图像中。在这种情况下,MulNet and GroupNet不可避免地浪费了大量的计算资源,因为它们必须在训练或测试期间激活所有类的所有子网络或子组。然而,在GroupDNet中,不平衡类与其邻居类共享参数,极大地缓解了类不平衡的问题。
类相关性。在自然世界中,语义类通常与其他类有关系,例如草的颜色和树叶的颜色相似,建筑物影响附近道路上的阳光等。为了产生合理的结果,MulNet和GroupNet都有一个融合模块(几个规则卷积).在decoder的末尾,将不同类的特征合并为一个图像输出。一般来说,融合模块大致考虑了不同类之间的相关性。然而,我们认为这是不够的,因为不同类别之间的相关性太复杂了,不能通过使用这样一个具有有限的接受域的简单成分来充分探索。另一种选择是使用一些网络模块,如自注意块来捕获图像的长期依赖关系,但它的计算阻碍了它在这类场景中的使用(就是qkv计算需要太多的内存空间)。然而,GroupDNet在整个解码器中雕刻了这些关系;因此,它更准确和彻底地利用了相关性。因此,GroupDNet生成的图像比其他两种方法生成的图像更好、更真实。
GPU memory. 为了保证MulNet的每一个网络或分组网中每个类的分组参数有足够的容量,信道总数将随着类数的增加而显著增加。达到一定限度,显卡的最大GPU内存将不再能够容纳一个样本。正如我们对ADE20K数据集[55]的粗略估计那样,即使将批量大小设置为1,一个特斯拉V100显卡也不能容纳有足够容量的模型。但是,GroupDNet中的问题不那么严重,因为不同的类共享参数,因此没有必要为每个类设置如此多的通道。
4. 模型具体架构
此刻相信大家已经初具想法了,就是在SPADE基础上结合groupdnet的思路,用group conv替代普通的conv,好,放图,这就是这篇论文的主要架构。
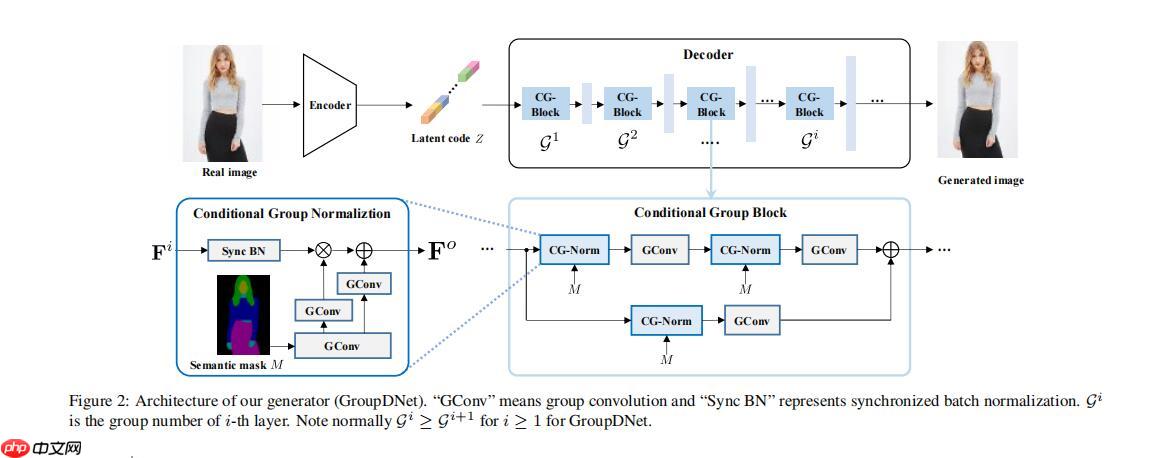
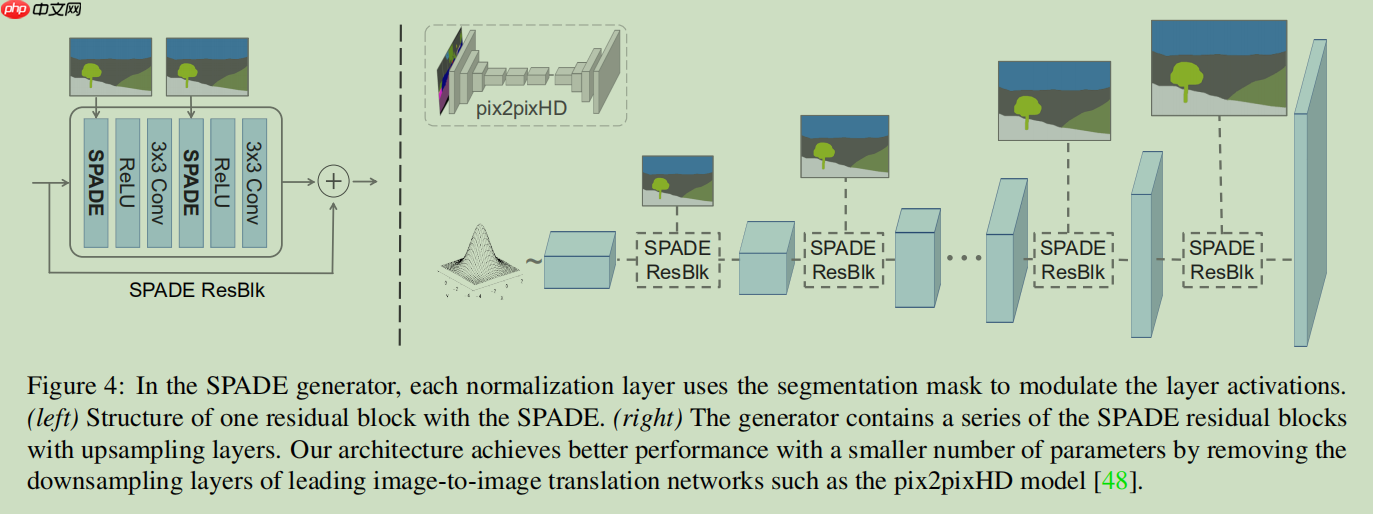
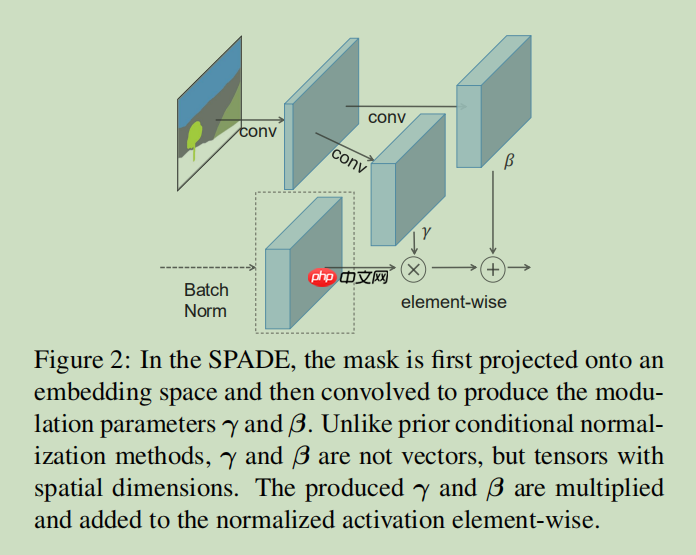
给大家对照解释一下,CG-Normal就是SPADE,CG-Block就是Spade-resblock. 给大家回顾一下SPADE模型图。
详细说明模型架构流程
从本论文架构图可以看出,GroupDNet包含一个编码器和一个解码器。受VAE[26]和spade[38]思想的启发,编码器E产生了一个潜在的编码Z,该编码在训练过程中应该遵循一个高斯分布N(0,1)。在测试时,编码器E被丢弃。从高斯分布中随机抽样的编码代替z。为了实现这一点,我们使用重新参数化技巧[26]在训练过程中启用可微损失函数。具体来说,编码器通过两个全连接的层来预测一个平均向量和一个方差向量来表示编码的分布。编码z分布和高斯分布之间的差距可以通过施加kl-散度损失来最小化。
Encoder详解
Encoder:原文是这样的:

我在这里给大家总结几个点:
这个输入的数据是比较奇特的Xc,我给大家简单介绍一下这个操作X是原图[b,3,h,w],Mc是 segmantation mask[b,class_num,h,w],接下来给大家看下我写的具体伪代码,这就是具体的操作:
images = Nonefor i in range(b): image = None for j in range(class_num): one = X[i] * Mc[i][j] #[3,h,w] one = one.unsqueeze([0])#[1,3,h,w] if image ==None: image =one else: image = concat([image,one],axis = 1) #image.shape = [1,3*class_num,h,w] if images ==None: images =image else: images = concat([images,image],axis = 0) # images.shape = [b,3*class_num,h,w]
好了这个就是输入encoder的input,这样处理数据的核心含义是什么呢?作者是这么解释的:
该操作减少了Encoder处理特征解纠缠的一部分压力,节省了对特征进行精确编码的容量。
Encoder中的Groups 为class_num从输入和架构方面,Encoder解耦不同的class,使其彼此独立。因此,所编码的潜在代码Z由所有类的特定于类的潜在代码Zc(Z的一个离散部分)组成。在即将到来的解码阶段,Zc作为c类的控制器。说白了就是Encoder就是专心解耦,争取把特征解耦编码的Zc也可以明白具体控制哪个类。与产生两个向量作为高斯分布的均值和方差预测的一般方案不同,我们的编码器通过卷积层生成一个均值映射和一个方差映射,以在潜在代码Z中大规模保留结构信息。这个点我需要强调一下啊,因为原论文Spade的Encoder经过几层卷积后就把这个特征图,给resize打平成一维向量,这个操作很大程度破坏了原图的特征位置结构信息,再并联两个全连接得到均值和logvar。但是本篇论文就直接舍弃了resize这个操作,用卷积操作代替全连接,这样这个得到的均值和logvar就可以保留图片的结构信息.
decoder详解




以上就是论文解读一篇关于语义生成论文(要求控制单独语义生成)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/42755.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 








![Go语言接口与切片:如何识别和操作[]interface{}](https://cdn.chuangxiangniao.com/www/2025/12/176369856569294-1.jpg?imageMogr2/crop/480x300/gravity/center)


















