
本项目旨在实现二次元头像的特征解耦,让B头像风格影响A头像主体且保持A大体不变。采用Konachan动漫头像数据集,基于SPADE架构,A为内容主体,B为风格。通过Encoder-Decoder提取特征,利用KLDLoss、VGG损失等训练,使生成图融合A主体与B风格,测试显示能体现特征影响差异。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

借二次元老婆们头像研究特征解耦
项目概述
情人节快到了,生成一个自己喜欢的二次元头像或许可以让大家开心一点,但是呢,我想试试不一样的,就是看看以A头像为主体,把B头像的风格去影响A头像,保持A头像大体不变,细节改变,这就是本项目做的最主要的事情。
任务详细介绍及其剖析理解
数据集介绍
我采用的是AI studio公开数据集Konachan动漫头像数据集,这里提供了大概4万多张256*256的动漫头像。 简单展示其中一张:

任务理解
首先我想做的事情很简单,就是用B去影响A,在这里B起到操作A特征的作用。如果是简单的做A和B图像简单的叠加融合其实是很简单的,如果我们采取Encoder-Decoder架构,只需要将训练好的生成器架构拿来,然后把A和B图像输入Encoder分别得到A和B的特征图,然后把A和B的特征图相加/2,这样把新的特征图输入Decoder就可以得到一张A和B叠加的效果图片。但这样不好,我试了一下,不好看,就相当于人脸眼睛的位置因为叠加出现了2双眼睛。
深入思索
这个时候有点感觉似乎有种风格迁移的感觉,B提供“风格”,A提供主体,那么谈到这个风格迁移,很自然,大家就想到了AdaIn,这个极为经典的风格迁移模型,我们很大程度认为一张图片的风格信息是包含在均值和标准差里面的。这个时候我主体架构依旧基于SPADE,不过,Encoder得到的均值和logvar是带有结构信息的,就是二维含有H和W的。这个时候就思路差不多明朗了,然后这里我的模型是基于SPADE论文主体架构,所以下面class的名字我也是没改,接下来我基于我的Model给大家讲解:
注意:std ,mu,logvar前面的c和s代表来自图像A和B,因为我把A当作内容主体,B当作风格,所以这样命名。
class Model(nn.Layer): def __init__(self,batch_size =4): super().__init__() self.batch_size =batch_size self.generator = SPADEGenerator() self.encoder = ConvEncoder() def reparameterize(self,mu, logvar): std = paddle.exp(0.5 * logvar) eps = paddle.randn([self.batch_size,64*8,8,8]) return paddle.multiply(eps,std) + mu,mu,std def forward(self,content_img,style_img): ''' content_img为A,style_img为B cmu,clogvar,z的shape都为[batch_size,64*8,8,8] 然后对于输入到decoder的特征主体是基于来自A cmu,clogvar构造的z,这样我们的主体图片特征信息就保存在z里面了。 然后这个style_img我们希望起到一个影响主体“风格”的作用,于是就保留smu(均值),sstd(标准差),于是这个B的风格信息就保存在style这个list中了. return:img_fake为生成的图片,cmu和clogvar后面算kldloss就是让reparameterize得到z逼近为标准正太分布。 ''' cmu, clogvar = self.encoder(content_img) z,_,_ = self.reparameterize(cmu, clogvar) smu, slogvar = self.encoder(style_img) _,smu,sstd = self.reparameterize(smu, slogvar) # z = paddle.randn([self.batch_size,64*8,8,8]) # z = img style = [smu,sstd] img_fake = self.generator(style,z) # return img_fake return img_fake,cmu,clogvar
Generator主体架构介绍:
这个就是基于SPADE generator,主体架构就是nn.upsample加SpadeResBlock, 结合代码介绍:
class SPADEGenerator(nn.Layer): def __init__(self): super().__init__() nf = 64 self.z_dim = 256 # self.sw, self.sh = self.compute_latent_vector_size(opt) self.sw = 8 self.sh = 8 self.num_upsampling_layers = " "#就是指输出的大小图片就是256*256,在8*8的基础上上采样5次。 self.use_vae = True self.noise_nc = 64 if self.use_vae: # In case of VAE, we will sample from random z vector self.fc = nn.Conv2D(self.noise_nc * 8, 16 * nf, kernel_size=3, padding=1, groups=8)#这个组数没在意,无心之举 else:#不用管else,这个反正没用过 self.fc = nn.Conv2D(self.noise_nc, 16 * nf, kernel_size=3, padding=1, groups=8) self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf,1) self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf,1) self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf,1) self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf,1) self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf,1) self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf,1) self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf,1) final_nc = nf if self.num_upsampling_layers == 'most': self.up_4 = SPADEResnetBlock(1 * nf, nf // 2,1) final_nc = nf // 2 # SpectralNorm = build_norm_layer('spectral') self.conv_img = nn.Conv2D(final_nc, 3, 3, padding=1 , weight_attr=spn_conv_init_weight, bias_attr=spn_conv_init_bias) self.up = nn.Upsample(scale_factor=2) def forward(self, style, z=None): if z is None: z = paddle.randn([style.shape[0],64 * 8, 8, 8], dtype=paddle.float32) # print("z.shape",z.shape) x = self.fc(z) x = x.reshape([-1, 16 * 64, self.sh, self.sw]) x = self.head_0(x, style) x = self.up(x)#1 x = self.G_middle_0(x,style) if self.num_upsampling_layers == 'more' or self.num_upsampling_layers == 'most': x = self.up(x)# x = self.G_middle_1(x, style) x = self.up(x)#2 x = self.up_0(x,style) x = self.up(x)#3 x = self.up_1(x,style) x = self.up(x)#4 x = self.up_2(x, style) x = self.up(x)#5 x = self.up_3(x, style) if self.num_upsampling_layers == 'most': x = self.up(x) x = self.up_4(x, style) x = self.conv_img(F.leaky_relu(x, 2e-1)) x = F.tanh(x) return x
所以generator就是通过这个SPADEResBlock把style融入主体特征图中
SPADEResBlock架构
class SPADEResnetBlock(nn.Layer): def __init__(self, fin, fout,group_num): ''' fin为input_channel,fout为output_channel ''' super().__init__() # Attributes self.learned_shortcut = (fin != fout) fmiddle = min(fin, fout) spectral =False noise_nc = 64*8 # create conv layers self.conv_0 = nn.Conv2D(fin, fmiddle, kernel_size=3, padding=1 ,groups = group_num , weight_attr=spn_conv_init_weight,bias_attr=spn_conv_init_bias) self.conv_1 = nn.Conv2D(fmiddle, fout, kernel_size=3, padding=1,groups = group_num , weight_attr=spn_conv_init_weight,bias_attr=spn_conv_init_bias) SpectralNorm = build_norm_layer('spectral') if self.learned_shortcut: self.conv_s = nn.Conv2D(fin, fout, kernel_size=1,groups = group_num) # apply spectral norm if specified if spectral ==True: self.conv_0 = SpectralNorm(self.conv_0) self.conv_1 = SpectralNorm(self.conv_1) if self.learned_shortcut: self.conv_s = SpectralNorm(self.conv_s) # define normalization layers self.norm_0 = SPADE(fin, noise_nc,group_num = group_num) self.norm_1 = SPADE(fmiddle, noise_nc,group_num = group_num) if self.learned_shortcut: self.norm_s = SPADE(fin, noise_nc,group_num =group_num) def forward(self, x, style): ''' x为特征图,style为[smu,sstd],smu.shape = sstd.shape = [b,64*8,8,8] ''' x_s = self.shortcut(x, style) dx = self.conv_0(self.actvn(self.norm_0(x,style))) dx = self.conv_1(self.actvn(self.norm_1(dx,style))) out = x_s + dx return out def shortcut(self, x, style): if self.learned_shortcut: x_s = self.conv_s(self.norm_s(x,style)) else: x_s = x return x_s def actvn(self, x): return F.leaky_relu(x, 2e-1)
所以接下来就是最核心的SPADE设计 在这里回忆一下AdaIn的公式:
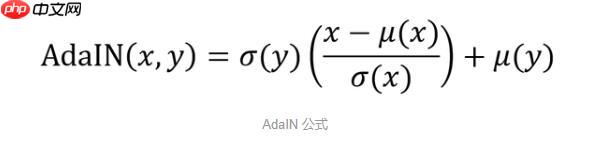
SPADE架构
class SPADE(nn.Layer): def __init__(self, norm_nc, style_nc,group_num): super().__init__() param_free_norm_type = "instance" if param_free_norm_type == 'instance': self.param_free_norm = nn.InstanceNorm2D(norm_nc, weight_attr=False, bias_attr=False) # The dimension of the intermediate embedding space. Yes, hardcoded. nhidden = 128 ks = 3 # SpectralNorm = build_norm_layer('spectral') pw = ks // 2 self.mlp_gamma = nn.Sequential( nn.Conv2D(style_nc, nhidden, kernel_size=ks, padding=pw ,weight_attr=spn_conv_init_weight, bias_attr=spn_conv_init_bias), nn.ReLU(), nn.Conv2D(nhidden, norm_nc, kernel_size=ks, padding=pw,groups = group_num) ) self.mlp_beta = nn.Sequential( nn.Conv2D(style_nc, nhidden, kernel_size=ks, padding=pw ,weight_attr=spn_conv_init_weight, bias_attr=spn_conv_init_bias), nn.ReLU(), nn.Conv2D(nhidden, norm_nc, kernel_size=ks, padding=pw,groups = group_num)) def forward(self, x, style): # Part 1. generate parameter-free normalized activations normalized = self.param_free_norm(x) mu = style[0] std = style[1] # Part 2. 把mu和std放缩成特征图大小,然后分别经过mlp_gamma和mlp_beta,构成gamma和beta mu = F.interpolate(style[0], size=x.shape[2:], mode='nearest') std= F.interpolate(style[1], size=x.shape[2:], mode='nearest') gamma = self.mlp_gamma(std) beta = self.mlp_beta(mu) # apply scale and bias out = normalized * gamma+ beta return out
好了,然后这里讲解一下我的loss设计:
判别器依旧采取MutiScaleDiscriminator,主要让生成器生成一个动漫头像,进行判断。风格层面:这里风格判断我采取的是animegan中的style loss,当然不太合适,因为这个用风格描述不太合适,应该B做的是特征上的风格。但是这里将就用一下,就是将img_fake和B算一个style loss.内容层面:img_fake和A算vggloss就是感知损失,还有在生成器预训练的时候我把img_fake和A直接算一个MSEloss然后我算img_fake和A的featloss,让他们在判别器上特征相近上面提过的kldloss.
训练介绍:
预训练时候生成器不需要对抗损失,只需要vggloss,mseloss,kldloss,styleloss正式训练加上ganloss和featloss
featloss可以更好帮你生成出的图片保持脸的样子。
效果可视化:
从左往右分别为img_fake,A,B

这个时候我进行了对比测试,更好的弄清楚cmu,cstd,smu,sstd的作用,我分别把他们变成paddle.randn([1,64*8,8,8])进行效果比对:
注:我是使用MODEL_test.py进行测试的
原图:

clogvar为randn:

cmu为randn:

sstd为randn:

smu为randn:

6.smu乘randn:

很明显,输入到generator的z是控制整体图像形状大概样子的。 style这个list里面的smu和slogvar是控制图像表面,比较浮于表面,最明显就是看smu为randn一个个格子的效果。格子效果产生原因应该来自于
mu = F.interpolate(style[0], size=x.shape[2:], mode=’nearest’)
std= F.interpolate(style[1], size=x.shape[2:], mode=’nearest’)
也就是说如果sstd和smu来自图像B而不是randn,那么这个sstd和smu就是保留人脸信息的可以和很好融入特征主体中。可以说这个sstd和smu相当于有人脸信息的噪声很合适。
更多效果展示:





其实当你图片来回切换,你会发现发型和脸其实是有区别的,只不过光看很难比较出来。
下面就是代码介绍了,最后一个代码块是测试的,可以直接单独运行。当然数据集还是要解压一下的。
In [1]
# 解压数据集,只需执行一次# import os# if not os.path.isdir("./data/d"):# os.mkdir("./data/d")# ! unzip data/data110820/faces.zip -d ./data/d
In [2]
#构造datasetIMG_EXTENSIONS = [ '.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',]import paddleimport cv2import osdef data_maker(dir): images = [] assert os.path.isdir(dir), '%s is not a valid directory' % dir for root, _, fnames in sorted(os.walk(dir)): for fname in fnames: if is_image_file(fname) and ("outfit" not in fname): path = os.path.join(root, fname) images.append(path) return sorted(images)def is_image_file(filename): return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)class AnimeDataset(paddle.io.Dataset): """ """ def __init__(self): super(AnimeDataset,self).__init__() self.anime_image_dirs =data_maker("data/d/faces") self.size = len(self.anime_image_dirs)//2 self.c_dirs = self.anime_image_dirs[:self.size] self.s_dirs = self.anime_image_dirs[self.size:2*self.size] # cv2.imread直接读取为GBR,把通道换成RGB @staticmethod def loader(path): return cv2.cvtColor(cv2.imread(path, flags=cv2.IMREAD_COLOR), cv2.COLOR_BGR2RGB) def __getitem__(self, index): c = AnimeDataset.loader(self.c_dirs[index]) s = AnimeDataset.loader(self.s_dirs[index]) return c,s def __len__(self): return self.size
In [3]
#构造dataloaderdataset = AnimeDataset()for i,j in dataset: print(i.shape) breakbatch_size = 4data_loader = paddle.io.DataLoader(dataset,batch_size=batch_size,shuffle =True)for c,s in data_loader: print(c.shape) break
(256, 256, 3)[4, 256, 256, 3]
In [4]
# !python -u SPADEResBlock.py
In [5]
# !python -u SPADE.py
In [6]
# !python -u Generator.py
In [7]
# !python -u MODEL.py
In [8]
import paddle.nn as nnclass KLDLoss(nn.Layer): def forward(self, mu, logvar): return -0.5 * paddle.sum(1 + logvar - mu.pow(2) - logvar.exp())KLD_Loss = KLDLoss()l1loss = nn.L1Loss()
In [9]
from VGG_Model import VGG19VGG = VGG19()
W0213 21:19:47.828871 19503 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0213 21:19:47.833061 19503 device_context.cc:465] device: 0, cuDNN Version: 7.6.
In [10]
import paddleimport cv2from tqdm import tqdmimport numpy as npimport osfrom visualdl import LogWriterfrom MODEL import Modelimport mathlog_writer = LogWriter("./log/gnet")mse_loss = paddle.nn.MSELoss()l1loss = paddle.nn.L1Loss()
In [11]
# !python -u Discriminator.py'''该代码块代表多尺度判别器示例'''from Discriminator import build_m_discriminatorimport numpy as npdiscriminator = build_m_discriminator()input_nc = 3x = np.random.uniform(-1, 1, [4, 3, 256, 256]).astype('float32')x = paddle.to_tensor(x)print("input tensor x.shape",x.shape)y = discriminator(x)for i in range(len(y)): for j in range(len(y[i])): print(i, j, y[i][j].shape) print('--------------------------------------')
input tensor x.shape [4, 3, 256, 256]0 0 [4, 64, 128, 128]0 1 [4, 128, 64, 64]0 2 [4, 256, 32, 32]0 3 [4, 512, 32, 32]0 4 [4, 1, 32, 32]--------------------------------------1 0 [4, 64, 64, 64]1 1 [4, 128, 32, 32]1 2 [4, 256, 16, 16]1 3 [4, 512, 16, 16]1 4 [4, 1, 16, 16]--------------------------------------
In [12]
model = Model()# # model和discriminator参数文件导入M_path ='model_params/Mmodel_state1.pdparams'layer_state_dictm = paddle.load(M_path)model.set_state_dict(layer_state_dictm)D_path ='discriminator_params/Dmodel_state1.pdparams'layer_state_dictD = paddle.load(D_path)discriminator.set_state_dict(layer_state_dictD)
In [13]
scheduler_G = paddle.optimizer.lr.StepDecay(learning_rate=1e-4, step_size=3, gamma=0.8, verbose=True)scheduler_D = paddle.optimizer.lr.StepDecay(learning_rate=4e-4, step_size=3, gamma=0.8, verbose=True)optimizer_G = paddle.optimizer.Adam(learning_rate=scheduler_G,parameters=model.parameters(),beta1=0.,beta2 =0.9)optimizer_D = paddle.optimizer.Adam(learning_rate=scheduler_D,parameters=discriminator.parameters(),beta1=0.,beta2 =0.9)
Epoch 0: StepDecay set learning rate to 0.0001.Epoch 0: StepDecay set learning rate to 0.0004.
In [14]
EPOCHEES = 30i = 0
In [15]
#四个设计保存参数文件的文件夹save_dir_generator = "generator_params"save_dir_encoder = "encoder_params"save_dir_model = "model_params"save_dir_Discriminator = "discriminator_params"
In [16]
class Train_OPT(): ''' opt格式 ''' def __init__(self): super(Train_OPT, self).__init__() self.no_vgg_loss = False self.batchSize = 4 self.lambda_feat = 10.0 self.lambda_vgg = 2opt = Train_OPT()
In [17]
#单纯当个指标,实际style_loss不参与反向传播def gram(x): b, c, h, w = x.shape x_tmp = x.reshape((b, c, (h * w))) gram = paddle.matmul(x_tmp, x_tmp, transpose_y=True) return gram / (c * h * w)def style_loss(style, fake): gram_loss = nn.L1Loss()(gram(style), gram(fake)) return gram_loss # return gram_loss
In [18]
from GANloss import GANLoss
In [ ]
# 训练代码step =0for epoch in range(EPOCHEES): # if(step >1000): # break for content,style in tqdm(data_loader): try: # if(step >1000): # break # print(input_img.shape,mask.shape) content =paddle.transpose(x=content.astype("float32")/127.5-1,perm=[0,3,1,2]) style =paddle.transpose(x=style.astype("float32")/127.5-1,perm=[0,3,1,2]) b,c,h,w = content.shape img_fake,_,_ = model(content,style) img_fake = img_fake.detach() # kld_loss = KLD_Loss(mu,logvar) # print(img_fake.shape) fake_and_real_data = paddle.concat((img_fake, content), 0).detach() pred = discriminator(fake_and_real_data) df_ganloss = 0. for i in range(len(pred)): pred_i = pred[i][-1][:opt.batchSize] # new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i1 new_loss = (300 * 1.2 *GANLoss()(pred_i, True))/4 dr_ganloss += new_loss dr_ganloss /= len(pred) dr_ganloss*=0.35 d_loss = df_ganloss + dr_ganloss d_loss.backward() optimizer_D.step() optimizer_D.clear_grad() discriminator.eval() # encoder.eval() # set_requires_grad(discriminator,False) # mu, logvar = encoder(input_img) # kld_loss = KLD_Loss(mu,logvar) # z = reparameterize(mu, logvar) # img_fake = generator(mask,z) # print(img_fake.shape) img_fake,mu,logvar = model(content,style) kldloss = KLD_Loss(mu,logvar)/20/50 g_vggloss = paddle.to_tensor(0.) g_styleloss= paddle.to_tensor(0.) if not opt.no_vgg_loss: rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0] # _, fake_features = VGG( paddle.multiply (img_fake,loss_mask)) # _, real_features = VGG(paddle.multiply (input_img,loss_mask)) _, fake_features = VGG(img_fake) _, content_features = VGG(content) _,style_features =VGG(style) for i in range(len(fake_features)): a,b = fake_features[i], content_features[i] # if i ==len(fake_features)-1: # a = paddle.multiply( a,F.interpolate(loss_mask,a.shape[-2:])) # b = paddle.multiply( b,F.interpolate(loss_mask,b.shape[-2:])) g_vggloss += rates[i] * l1loss(a,b) # print(a.shape,b.shape) # g_vggloss += paddle.mean(rates[i] *paddle.square(a-b)) if i ==len(fake_features)-1: style_a,style_b = fake_features[i], style_features[i] g_styleloss += rates[i] * style_loss(style_b,style_a) g_vggloss *= opt.lambda_vgg g_vggloss /=60 g_styleloss/=100 fake_and_real_data = paddle.concat((img_fake, content), 0) pred = discriminator(fake_and_real_data) # 关闭真图片 tensor 的梯度计算 for i in range(len(pred)): for j in range(len(pred[i])): pred[i][j][opt.batchSize:].stop_gradient = True g_ganloss = paddle.to_tensor(0.) for i in range(len(pred)): pred_i_f = pred[i][-1][:opt.batchSize] # pred_i_f = paddle.multiply(pred_i_f,loss_mask0) pred_i_r = pred[i][-1][opt.batchSize:].detach() # pred_i_r = paddle.multiply(pred_i_r,loss_mask0) _,c,h,w = pred_i_f.shape # new_loss = -1*pred_i_f.mean() # hinge loss new_loss = paddle.sum(paddle.square(pred_i_r -pred_i_f))/math.sqrt(c*h*w) g_ganloss += new_loss g_ganloss /= len(pred) # g_ganloss*=20 g_featloss = paddle.to_tensor(0.) for i in range(len(pred)): for j in range(len(pred[i]) - 1): # 除去最后一层的中间层featuremap pred_i_f = pred[i][j][:opt.batchSize] pred_i_r = pred[i][j][opt.batchSize:].detach() unweighted_loss = (pred_i_r -pred_i_f).abs().mean() # L1 loss g_featloss += unweighted_loss * opt.lambda_feat / len(pred) g_featloss*=3 mse = paddle.nn.MSELoss()(img_fake, content)*100 # g_loss = g_ganloss + g_vggloss +g_featloss +kldloss # g_loss = mse +g_vggloss+kldloss+g_ganloss +g_featloss g_loss =g_styleloss+g_vggloss+kldloss+g_ganloss +g_featloss g_loss.backward() optimizer_G.step() optimizer_G.clear_grad() # optimizer_E.step() # optimizer_E.clear_grad() discriminator.train() if step%2==0: log_writer.add_scalar(tag='train/d_real_loss', step=step, value=dr_ganloss.numpy()[0]) log_writer.add_scalar(tag='train/d_fake_loss', step=step, value=df_ganloss.numpy()[0]) log_writer.add_scalar(tag='train/d_all_loss', step=step, value=d_loss.numpy()[0]) log_writer.add_scalar(tag='train/g_ganloss', step=step, value=g_ganloss.numpy()[0]) log_writer.add_scalar(tag='train/g_featloss', step=step, value=g_featloss.numpy()[0]) log_writer.add_scalar(tag='train/g_vggloss', step=step, value=g_vggloss.numpy()[0]) log_writer.add_scalar(tag='train/g_loss', step=step, value=g_loss.numpy()[0]) log_writer.add_scalar(tag='train/g_styleloss', step=step, value=g_styleloss.numpy()[0]) log_writer.add_scalar(tag='train/kldloss', step=step, value=kldloss.numpy()[0]) log_writer.add_scalar(tag='train/mse', step=step, value=mse.numpy()[0]) step+=1 # print(i) if step%100 == 3: print(step,"g_ganloss",g_ganloss.numpy()[0],"g_featloss",g_featloss.numpy()[0],"g_vggloss",g_vggloss.numpy()[0],"mse",mse.numpy()[0],"g_styleloss",g_styleloss.numpy()[0],"kldloss",kldloss.numpy()[0],"g_loss",g_loss.numpy()[0]) print(step,"dreal_loss",dr_ganloss.numpy()[0],"dfake_loss",df_ganloss.numpy()[0],"d_all_loss",d_loss.numpy()[0]) g_output = paddle.concat([img_fake,content,style],axis = 3).detach().numpy() # tensor -> numpy g_output = g_output.transpose(0, 2, 3, 1)[0] # NCHW -> NHWC g_output = (g_output+1) *127.5 # 反归一化 g_output = g_output.astype(np.uint8) cv2.imwrite(os.path.join("./kl_result", 'epoch'+str(step).zfill(3)+'.png'),cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR)) # generator.train() if step%100 == 3: # save_param_path_g = os.path.join(save_dir_generator, 'Gmodel_state'+str(3)+'.pdparams') # paddle.save(model.generator.state_dict(), save_param_path_g) save_param_path_d = os.path.join(save_dir_Discriminator, 'Dmodel_state'+str(1)+'.pdparams') paddle.save(discriminator.state_dict(), save_param_path_d) # save_param_path_e = os.path.join(save_dir_encoder, 'Emodel_state'+str(1)+'.pdparams') # paddle.save(model.encoder.state_dict(), save_param_path_e) save_param_path_m = os.path.join(save_dir_model, 'Mmodel_state'+str(1)+'.pdparams') paddle.save(model.state_dict(), save_param_path_m) # break except: pass # break scheduler_G.step() scheduler_D.step()
0%| | 2/5596 [00:01<1:15:23, 1.24it/s]
3 g_ganloss 0.7048465 g_featloss 9.941195 g_vggloss 15.863348 mse 9.353435 g_styleloss 2.1046102 kldloss 2.3783047 g_loss 30.9923063 dreal_loss 1.017228 dfake_loss 0.823833 d_all_loss 1.841061
0%| | 8/5596 [00:08<1:25:32, 1.09it/s]
In [ ]
#测试代码 效果保存至test文件from MODEL import Modelimport paddleimport numpy as npimport cv2import osmodel = Model(1)M_path ='model_params/Mmodel_state1.pdparams'layer_state_dictm = paddle.load(M_path)model.set_state_dict(layer_state_dictm)z = paddle.randn([1,64*8,8,8])path2 ="data/d/faces/000005-01.jpg"img1 = cv2.cvtColor(cv2.imread(path2, flags=cv2.IMREAD_COLOR),cv2.COLOR_BGR2RGB)g_input1 = img1.astype('float32') / 127.5 - 1 # 归一化g_input1 = g_input1[np.newaxis, ...].transpose(0, 3, 1, 2) # NHWC -> NCHWg_input1 = paddle.to_tensor(g_input1) # numpy -> tensorprint(g_input1.shape)path2 ="data/d/faces/000000-01.jpg"img2 = cv2.cvtColor(cv2.imread(path2, flags=cv2.IMREAD_COLOR),cv2.COLOR_BGR2RGB)g_input2 = img2.astype('float32') / 127.5 - 1 # 归一化g_input2 = g_input2[np.newaxis, ...].transpose(0, 3, 1, 2) # NHWC -> NCHWg_input2 = paddle.to_tensor(g_input2) # numpy -> tensorprint(g_input2.shape)img_fake,_,_= model(g_input1,g_input2)print('img_fake',img_fake.shape)print(img_fake.shape)g_output = paddle.concat([img_fake,g_input1,g_input2],axis = 3).detach().numpy() # tensor -> numpyg_output = g_output.transpose(0, 2, 3, 1)[0] # NCHW -> NHWCg_output = (g_output+1) *127.5 # 反归一化g_output = g_output.astype(np.uint8)cv2.imwrite(os.path.join("./test", "原图1"+'.png'), cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR))
以上就是情人节:借助二次元老婆研究特征解耦的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/42798.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























