
在前两篇文章中,我们对spring batch这个批处理框架进行了初步的学习和了解。你可以从中了解到spring batch的基本概念、应用场景、如何编写一个spring batch的demo,以及其架构设计和核心组件的简介。
今天我们将深入分析Spring Batch中一个常用的类:JdbcPagingItemReader。通过对其源码的分析,你将对Spring Batch有更深入的理解,从而更好地进行技术选型和场景化方案的落地。
1、JdbcPagingItemReader类的继承层次:
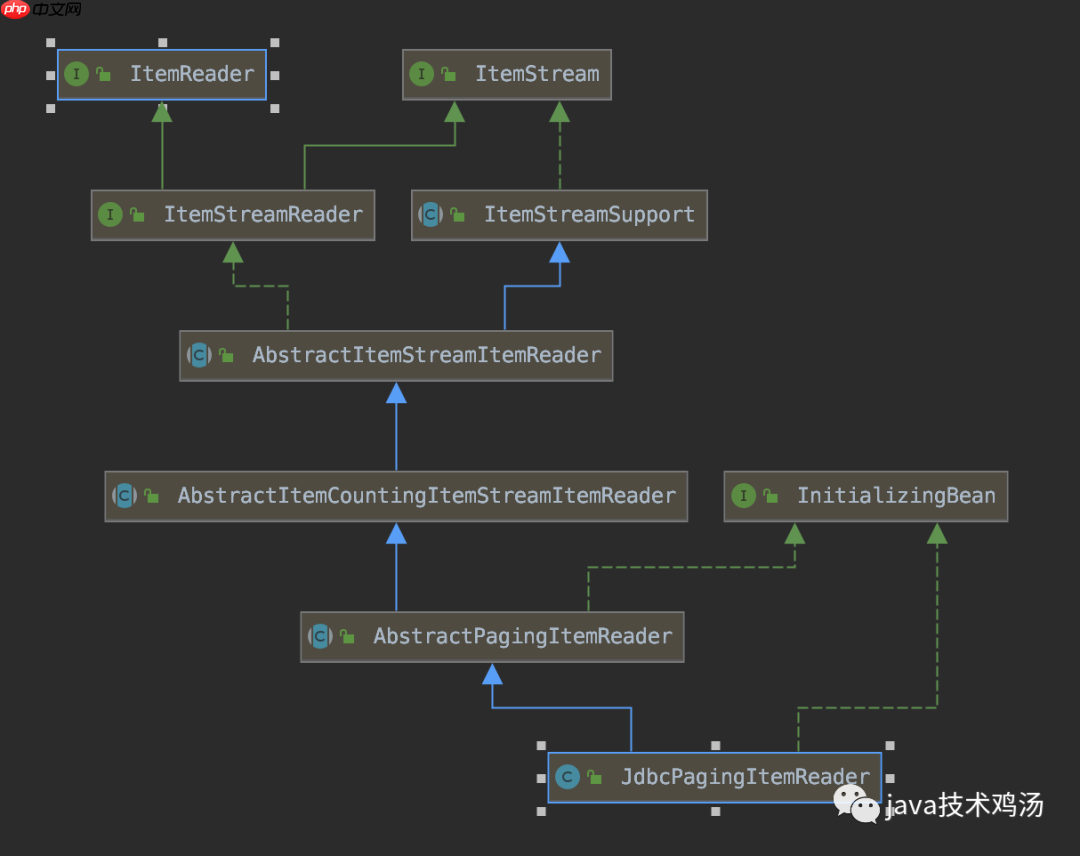 可以看到,该类继承自ItemReader和ItemStream接口。
可以看到,该类继承自ItemReader和ItemStream接口。
2、JdbcPagingItemReader的作用是什么?
JdbcPagingItemReader用于通过JDBC以分页方式从数据库中读取记录。它通过PagingQueryProvider构建的SQL来检索数据,并使用setPageSize(int)方法指定分页大小。通过调用read()方法请求其他页面,并返回与当前位置相对应的对象。在重新启动时,它会使用最后一个排序键值来定位要读取的第一页。排序键必须具有唯一的键约束,以确保在两次执行之间不会丢失任何数据。分页性能依赖于数据库的特定功能来限制返回的行数。设置较大的页面大小并使用与页面大小匹配的提交间隔可以提高性能。在两次调用open(ExecutionContext)之间,该实现是线程安全的,但在多线程环境中使用时,需要设置saveState=false(无重启功能)。
3、JdbcPagingItemReader的属性有哪些?
private static final String START_AFTER_VALUE = "start.after";public static final int VALUE_NOT_SET = -1;private DataSource dataSource;private PagingQueryProvider queryProvider;private Map parameterValues;private NamedParameterJdbcTemplate namedParameterJdbcTemplate;private RowMapper rowMapper;private String firstPageSql;private String remainingPagesSql;private Map startAfterValues;private Map previousStartAfterValues;private int fetchSize = VALUE_NOT_SET;
关于PagingQueryProvider接口,需要说明的是,Spring Batch根据不同的数据库类型封装了相应的实现类,如MySqlPagingQueryProvider、OraclePagingQueryProvider等,如下图所示:
 如果你熟悉阿里巴巴开源的DataX,那么你会发现其设计思想与Spring Batch有一定的相似性,都是通过Reader读取数据源,Writer写入数据源。DataX提供了更细粒度的控制和可插拔性,只需对需要的部分进行组装即可使用,而Spring Batch则提供了常用数据源的封装。
如果你熟悉阿里巴巴开源的DataX,那么你会发现其设计思想与Spring Batch有一定的相似性,都是通过Reader读取数据源,Writer写入数据源。DataX提供了更细粒度的控制和可插拔性,只需对需要的部分进行组装即可使用,而Spring Batch则提供了常用数据源的封装。
4、JdbcPagingItemReader也实现了InitializingBean接口的afterPropertiesSet方法:
public void afterPropertiesSet() throws Exception { super.afterPropertiesSet(); Assert.notNull(dataSource, "DataSource may not be null"); JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource); if (fetchSize != VALUE_NOT_SET) { jdbcTemplate.setFetchSize(fetchSize); } jdbcTemplate.setMaxRows(getPageSize()); namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(jdbcTemplate); Assert.notNull(queryProvider, "QueryProvider may not be null"); queryProvider.init(dataSource); this.firstPageSql = queryProvider.generateFirstPageQuery(getPageSize()); this.remainingPagesSql = queryProvider.generateRemainingPagesQuery(getPageSize());}
从这里可以看出,Spring Batch实际上是使用JdbcTemplate进行SQL查询的,默认的pageSize为10,然后queryProvider调用init方法,将DataSource作为参数传入。
 析稿Ai写作
析稿Ai写作
科研人的高效工具:AI论文自动生成,十分钟万字,无限大纲规划写作思路。
 97 查看详情
97 查看详情 
DataSource作为init参数传入后的代码逻辑如下:
public void init(DataSource dataSource) throws Exception { Assert.notNull(dataSource, "A DataSource is required"); Assert.hasLength(selectClause, "selectClause must be specified"); Assert.hasLength(fromClause, "fromClause must be specified"); Assert.notEmpty(sortKeys, "sortKey must be specified"); StringBuilder sql = new StringBuilder(64); sql.append("SELECT ").append(selectClause); sql.append(" FROM ").append(fromClause); if (whereClause != null) { sql.append(" WHERE ").append(whereClause); } if(groupClause != null) { sql.append(" GROUP BY ").append(groupClause); } List namedParameters = new ArrayList(); parameterCount = JdbcParameterUtils.countParameterPlaceholders(sql.toString(), namedParameters); if (namedParameters.size() > 0) { if (parameterCount != namedParameters.size()) { throw new InvalidDataAccessApiUsageException( "You can't use both named parameters and classic "?" placeholders: " + sql); } usingNamedParameters = true; }}
从这段代码可以看出几点:
DataSource必须指定,否则会抛出异常。select查询列必须明确,不能使用select *。fromClause必须有,否则不知道从哪个表查询数据,如果不传会抛出异常。sortKey是必须的,Spring Batch要求传一个sortKey,且该sortKey必须能确定数据的唯一性,否则在批处理时会遗漏数据(需要注意的是,分页查询必须指定sortKey,这对查询性能有一定影响。如果不想指定sortKey,直接会抛出异常;如果指定了唯一key作为sortKey,但select中没有sortKey,会报列名无效的异常,且该异常不会明确指出是哪个列无效,只能通过异常堆栈判断)。
此外,Spring Batch的PagingQueryProvider只支持单表查询,不支持join类型的查询。
5、SortedKey的结构是怎样的?
public void setSortKeys(Map sortKeys) { this.sortKeys = sortKeys;}
可以看出,SortedKey是一个Map对象,其中key是数据库表的唯一key字段名称,value是一个Order对象。Order对象只有两个属性:升序或降序,Order是一个枚举类型:
public enum Order { ASCENDING, DESCENDING}
今天主要分享了Spring Batch中从数据库数据源读取数据的方式PagingQueryProvider。对于开源工具,我们不评价其好坏,而是吸收其设计思想,发现其不足之处。如果有余力,可以自行研发。
如果你有数据库、消息类、文件类等数据源,可以选择Spring Batch。建议每个reader读取单表数据,然后在processor中处理多个结果集,最后将数据插入目标数据源。对于database类型,希望你在使用Spring Batch的Reader读取数据时能提高性能,如使用索引,避免全表扫描等。
当然,对于数据的抽取、清洗和转换,你也可以考虑其他技术方案,如kettle、DataX(商业版是DataWorks),以及大数据类型的解决方案。同时,你还需要考虑资源问题,如时间、人力等。
以上就是Spring Batch分析(一)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/433515.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















