针对java web中的表格查询进行的sql优化,背景是多个机台将数据发送到服务器,服务器将数据存储在mysql数据库中,并通过java web程序展示给用户。以下是对原文章的伪原创处理:
背景
本次SQL优化是针对Java Web应用中表格查询功能进行的。多个机台将业务数据传输到服务器端,服务器程序将这些数据存储到MySQL数据库中。接着,Java Web应用通过读取数据库中的数据,将其展示在网页上供用户查看。
部分网络架构图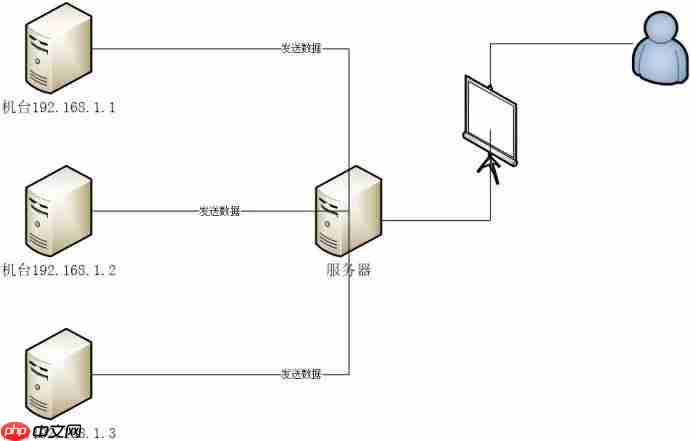
业务简介
多个机台将业务数据发送到服务器,服务器程序将这些数据存储到MySQL数据库中。Java Web程序从数据库中读取数据并在网页上展示给用户。
原数据库设计
数据库采用Windows单机主从分离的架构,已进行分表分库处理,按年份分库,按天分表。每张表大约包含20万条数据。原查询效率为3天数据查询需70-80秒。
目标
优化目标是将3天数据查询时间缩短至3-5秒。
业务缺陷
由于业务限制,无法使用SQL分页,只能通过Java进行分页处理。
问题排查
为了确定是前端还是后端导致查询慢,如果配置了Druid,可以在其页面直接查看SQL执行时间和URI请求时间。也可以在后台代码中使用System.currentTimeMillis计算时间差。结论是后台执行慢,且SQL查询速度慢。
SQL问题分析
原SQL语句拼接过长,达到3000行甚至8000行,大部分是通过UNION ALL操作连接的,并且存在不必要的嵌套查询和查询了不必要的字段。使用EXPLAIN查看执行计划,发现除了时间条件外,WHERE条件中只有一个字段使用了索引。备注:由于优化后无法找到原SQL,这里只能进行假设分析。
查询优化
去除不必要的字段:效果不明显。去除不必要的嵌套查询:效果不明显。分解SQL:将UNION ALL操作分解为多个SQL语句执行,最后汇总数据。这种方法使查询速度提高了约20秒。
例如,将如下SQL分解:
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where .. union allselect aa from bb_2018_10_02 left join ... on .. left join .. on .. where .. union allselect aa from bb_2018_10_03 left join ... on .. left join .. on .. where .. union allselect aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
分解为:
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
异步执行分解的SQL:使用Java的异步编程功能,将分解后的SQL语句异步执行并最终汇总数据。这里使用了CountDownLatch和ExecutorService,示例代码如下:
// 获取时间段所有天数List days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());// 天数长度int length = days.size();// 初始化合并集合,并指定大小,防止数组越界List list = Lists.newArrayListWithCapacity(length);// 初始化线程池ExecutorService pool = Executors.newFixedThreadPool(length);// 初始化计数器CountDownLatch latch = new CountDownLatch(length);// 查询每天的时间并合并for (String day : days) { Map param = Maps.newHashMap(); // param 组装查询条件 pool.submit(new Runnable() { @Override public void run() { try { // mybatis查询sql // 将结果汇总 list.addAll(查询结果); } catch (Exception e) { logger.error("getTime异常", e); } finally { latch.countDown(); } } });}try { // 等待所有查询结束 latch.await();} catch (InterruptedException e) { e.printStackTrace();}// list为汇总集合// 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了
这种方法使查询速度再次提高了20-30秒。
优化MySQL配置
以下是优化MySQL配置的示例。添加了skip-name-resolve配置后,查询速度提高了4-5秒。其它配置可根据具体情况进行调整。
[client]port=3306[mysql]no-beepdefault-character-set=utf8
[mysqld]server-id=2relay-log-index=slave-relay-bin.indexrelay-log=slave-relay-binslave-skip-errors=all #跳过所有错误skip-name-resolveport=3306datadir="D:/mysql-slave/data"character-set-server=utf8default-storage-engine=INNODBsql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"log-output=FILEgeneral-log=0general_log_file="WINDOWS-8E8V2OD.log"slow-query-log=1slow_query_log_file="WINDOWS-8E8V2OD-slow.log"long_query_time=10
Binary Logging.
log-bin
Error Logging.
log-error="WINDOWS-8E8V2OD.err"
整个数据库最大连接(用户)数
max_connections=1000
每个客户端连接最大的错误允许数量
max_connect_errors=100
表描述符缓存大小,可减少文件打开/关闭次数
table_open_cache=2000
服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要)
每个连接独立的大小.大小动态增加
max_allowed_packet=64M
在排序发生时由每个线程分配
sort_buffer_size=8M
当全联合发生时,在每个线程中分配
join_buffer_size=8M
cache中保留多少线程用于重用
thread_cache_size=128
此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量.
thread_concurrency=64
查询缓存
query_cache_size=128M
只有小于此设定值的结果才会被缓冲
此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖
query_cache_limit=2M
InnoDB使用一个缓冲池来保存索引和原始数据
这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
innodb_buffer_pool_size=1G
用来同步IO操作的IO线程的数量
此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好.
innodb_read_io_threads=16innodb_write_io_threads=16
在InnoDb核心内的允许线程数量.
最优值依赖于应用程序,硬件以及操作系统的调度方式.
过高的值可能导致线程的互斥颠簸.
innodb_thread_concurrency=9
0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘.
1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上
2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上
innodb_flush_log_at_trx_commit=2
用来缓冲日志数据的缓冲区的大小.
innodb_log_buffer_size=16M
在日志组中每个日志文件的大小.
innodb_log_file_size=48M
在日志组中的文件总数.
innodb_log_files_in_group=3
在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久.
InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务.
如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎
那么一个死锁可能发生而InnoDB无法注意到.
这种情况下这个timeout值对于解决这种问题就非常有帮助.
innodb_lock_wait_timeout=30
开启定时
event_scheduler=ON



根据业务需求,添加筛选条件后,查询速度又提高了4-5秒。
索引优化
建立联合索引:将WHERE条件中除时间条件外的字段建立联合索引,效果不明显。使用INNER JOIN:将WHERE条件中的索引条件使用INNER JOIN方式进行关联。原SQL中b为索引字段:
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'
修改为:
select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join(select 'xxx1' as b2union allselect 'xxx2' as b2union allselect 'xxx3' as b2union allselect 'xxx3' as b2) t on b = t.b2
这种方法使查询速度提高了3-4秒。
性能瓶颈
经过上述优化,3天数据查询效率已经达到约8秒,但无法进一步提升。检查MySQL的CPU使用率和内存使用率均不高,3天数据最多60万条,关联的都是一些字典表,不应如此慢。尝试各种网上提供的方法,基本无效。
环境对比
由于SQL优化已完成,考虑可能是磁盘读写问题。将优化后的程序部署在不同的现场环境中,其中一个环境使用SSD,另一个使用普通机械硬盘。发现查询效率差异显著。使用软件检测发现SSD的读写速度为700-800M/s,而普通机械硬盘的读写速度为70-80M/s。
优化结果及结论
优化结果:达到了预期目标。
优化结论:SQL优化不仅仅是对SQL本身的优化,还取决于硬件条件、其他应用的影响以及自身代码的优化。
小结
优化的过程是一个自我提升和挑战的机会,珍惜这样的机会,不要只做写业务代码的程序员。希望以上内容能对你的思考有所帮助,欢迎指出不足之处。
以上就是MySQL 之 SQL 优化实战记录的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/436039.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫