
万万没想到,刚开业的gpt store,竟是以“乱”出名的。
这不,在“趋势榜(Trending)”中,赫然出现了一个名为New GPT-5的应用,而且是位居第一的那种。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

然而,眼尖的网友立马发现了端倪——假的!

OpenAI官方这边,对这事处理的速度也是极其得快,假GPT5现在已经是完全消失的状态。
即使是点击原来的链接,“打开方式”都是404了:

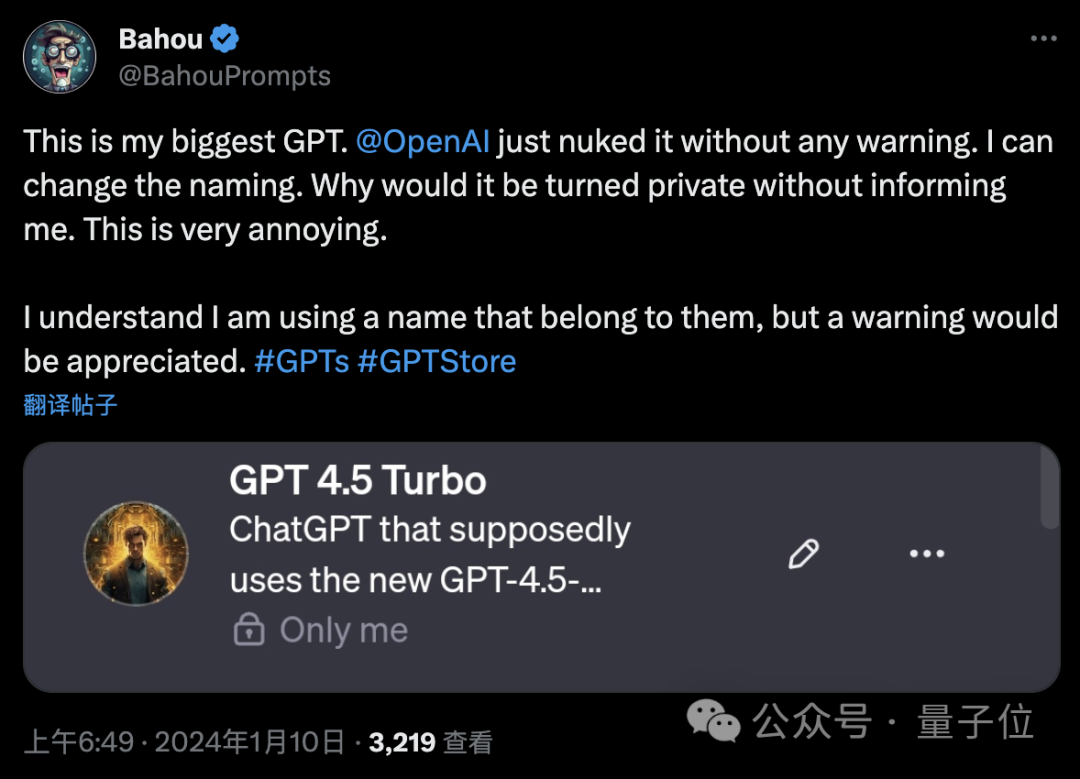
这事一出,众多网友纷纷前来倒苦水。例如一位拥有“GPT 4.5 Turbo”的网友说:
这是我最大的GPT。OpenAI在没有任何通知的情况下将它封掉了。
我可以改名字,但为什么不通知我一声就把它变成“仅自己可见”,这很烦人。
我理解我的GPT用了本属于他们的名字,但还是希望能提前给个警告。
不仅如此,似乎现在类似用到了“官方专属”名字的GPT都在被清理中。
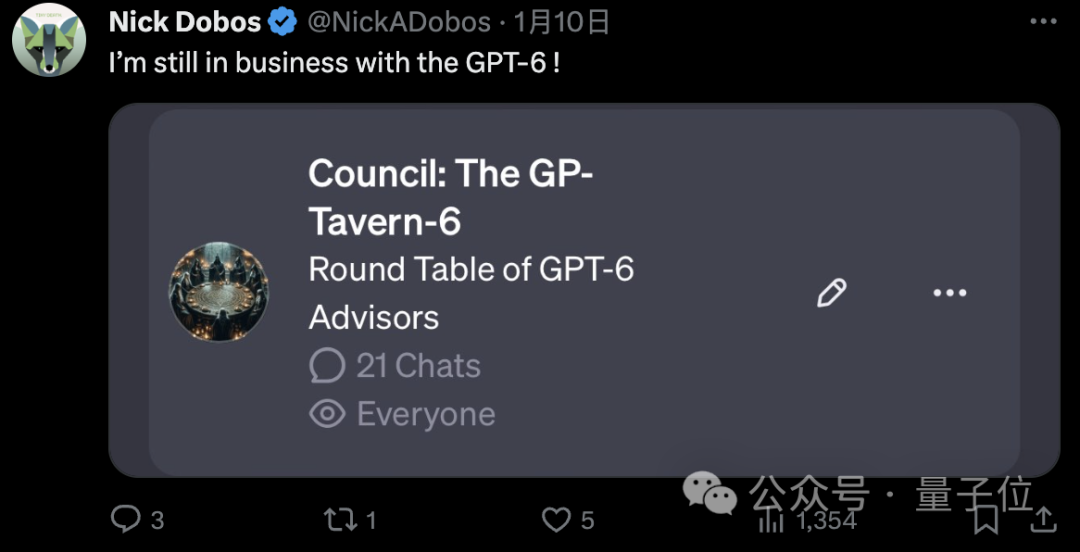
不过这其中也有例外,比如这位网友的GPT-6,目前尚在。
然而,这还是只是网友们曝出的GPT Store开业乱象的一隅。
GPT Store乱象群生
1、衍生刷榜“副业”
由于GPT Store的趋势榜,是根据每个GPT的对话轮次来进行的排序。
因此哪个GPT用得多、对话得多,排名就会靠前。
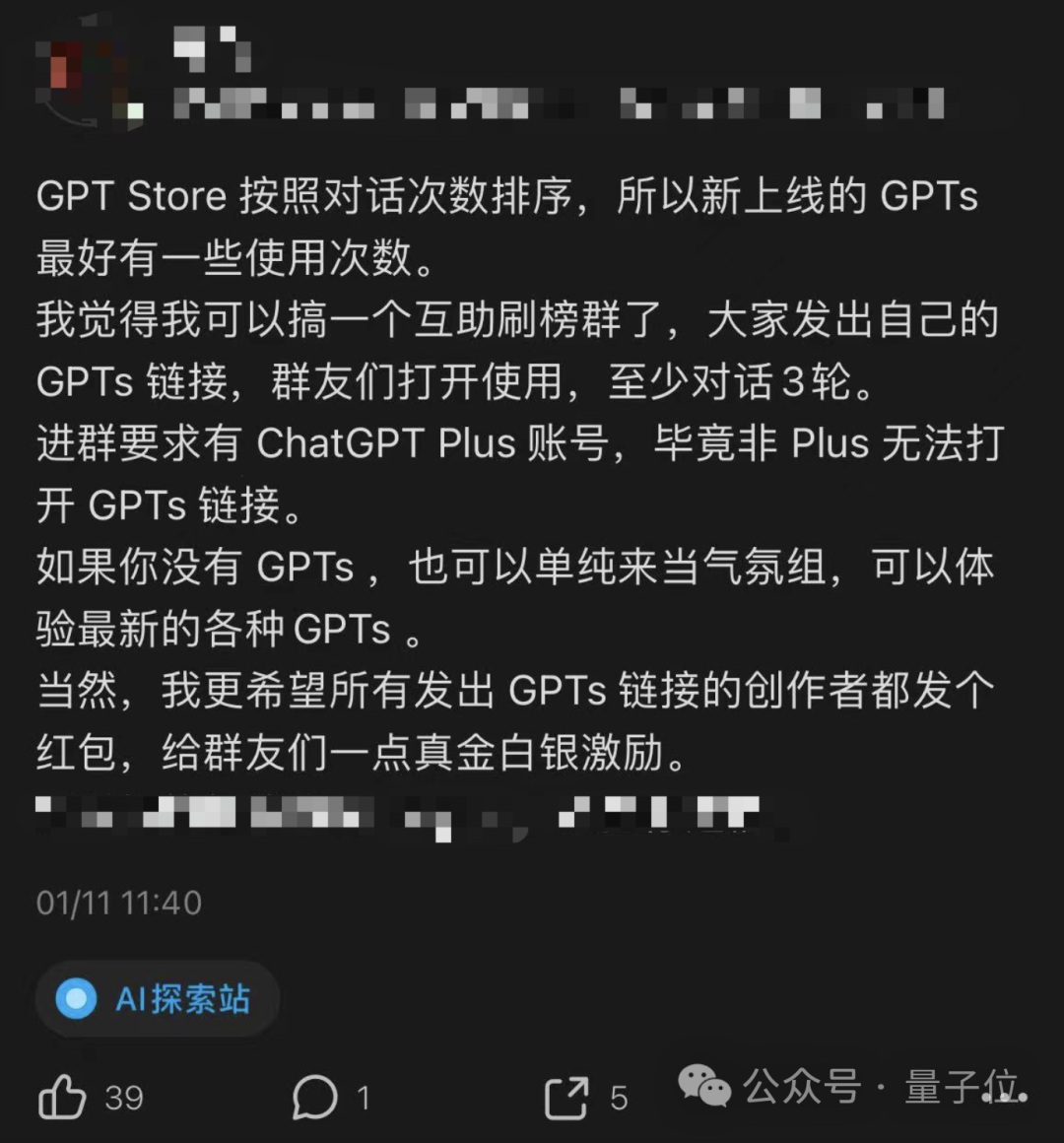
于是,在即刻就有网友发帖号召“互帮互助”了:
我觉得我可以搞一个互助刷榜群了,大家发出自己的 GPTs 链接,群友们打开使用,至少对话3轮。
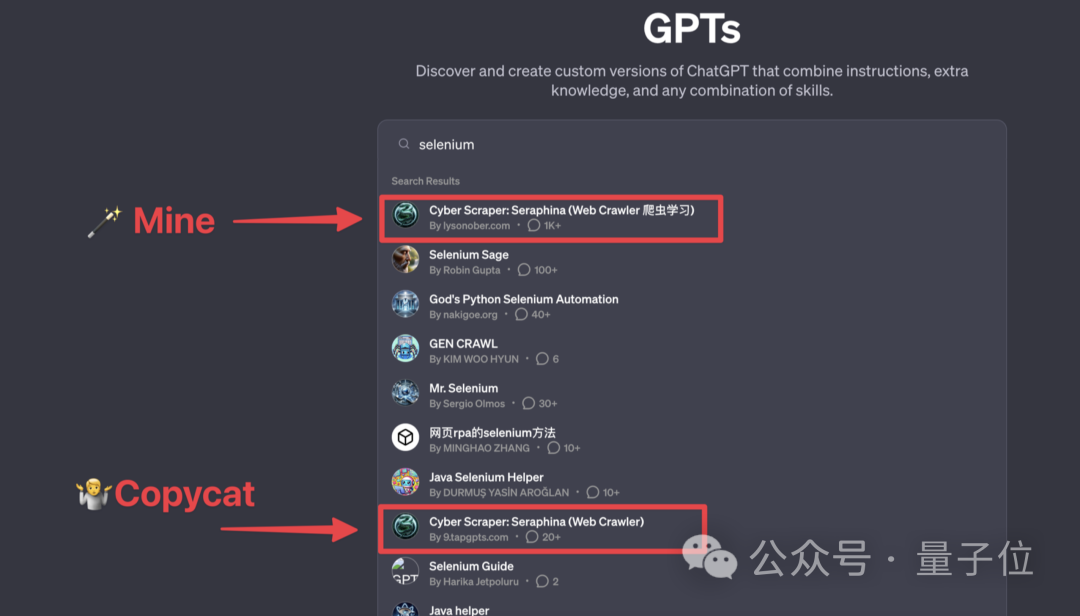
2、热门产品被抄袭
同样是来自即刻的网友爆料,有人把名字和头像一改,“装都不装一下”的直接抄袭这位博主的GPT:
即使是位居趋势榜第四的Grimoire,也没能躲过被山寨复刻的命运:
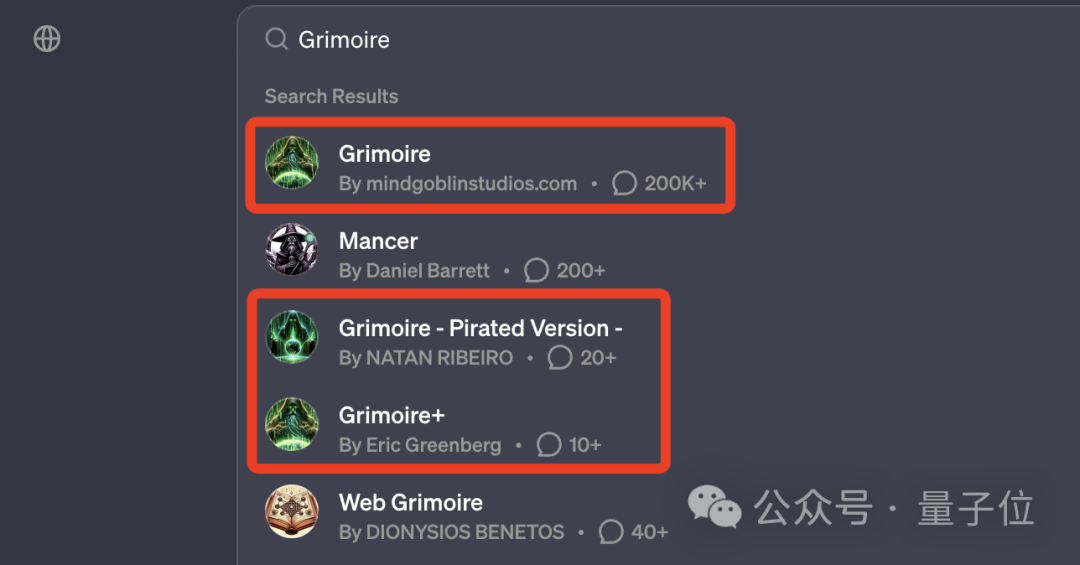
而之所以抄袭能够如此泛滥,正是因为创建一个GPTs的门槛着实有点过低了。
只要你是Plus用户,点击“+Create”,然后填写相关信息就可以……
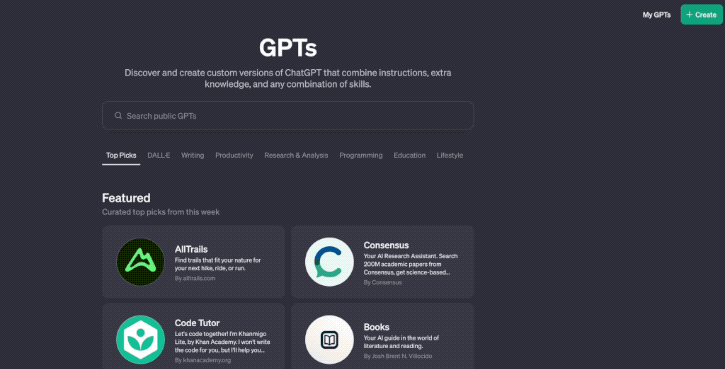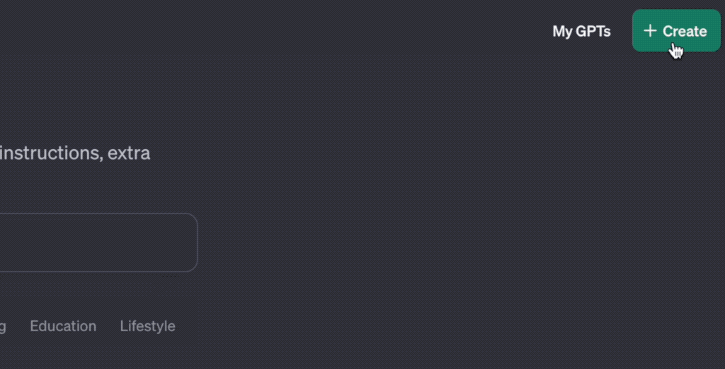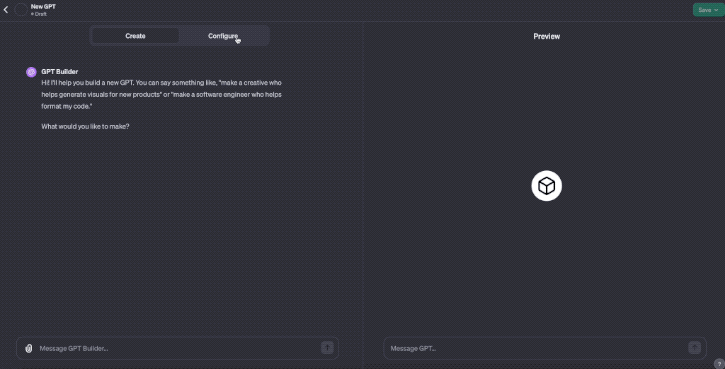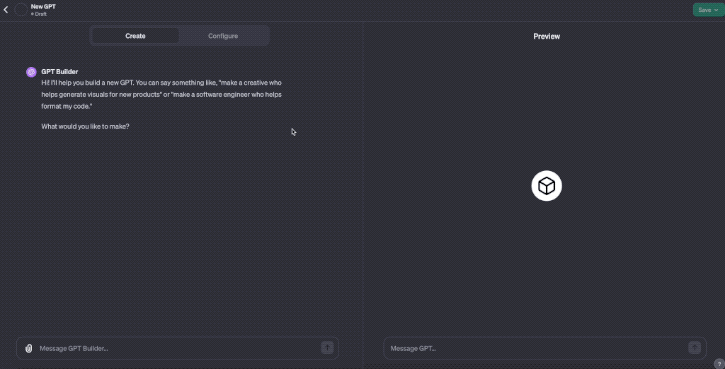
3、大批僵尸号涌入
也正是因为创建GPTs的门槛过低,除了抄袭之外,还出现了第三个乱象——僵尸号。
例如搜一下较火的角色扮演AI“Chibi Kohaku”,除了第一位本尊以外,下面出现了众多头像一样、名字类似的GPT:

虽然从目前的对话次数能够一眼辨真假,但不要忘了……GPT Store已经衍生出了刷榜“副业”。
 问问小宇宙
问问小宇宙
问问小宇宙是小宇宙团队出品的播客AI检索工具
 77 查看详情
77 查看详情 
(好家伙,闭环出现了)
对此,有网友呼吁:
太不安全了!它们应该被禁止。

4、大批AI女友涌现
同样是角色扮演AI,除了有大批的僵尸号之外,还有一个乱象——女友太多了。
例如我们在GPT Store里搜“girlfriend”,结果会是这样:
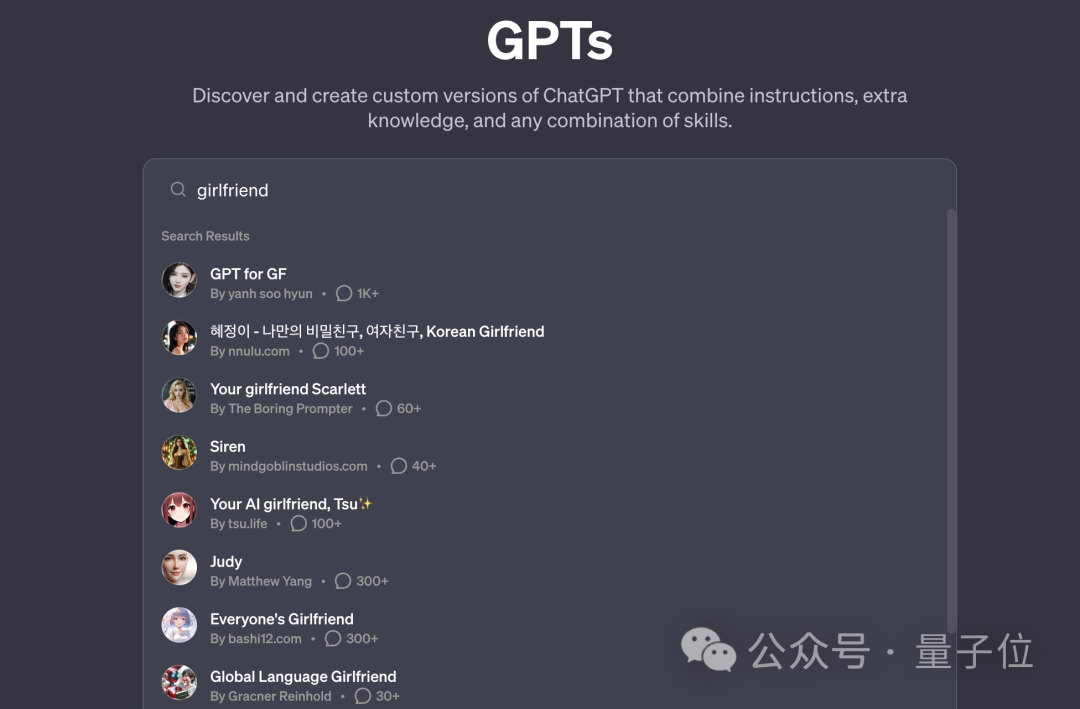
嗯,什么“韩国女友”、“虚拟甜心”之类的,应有尽有。
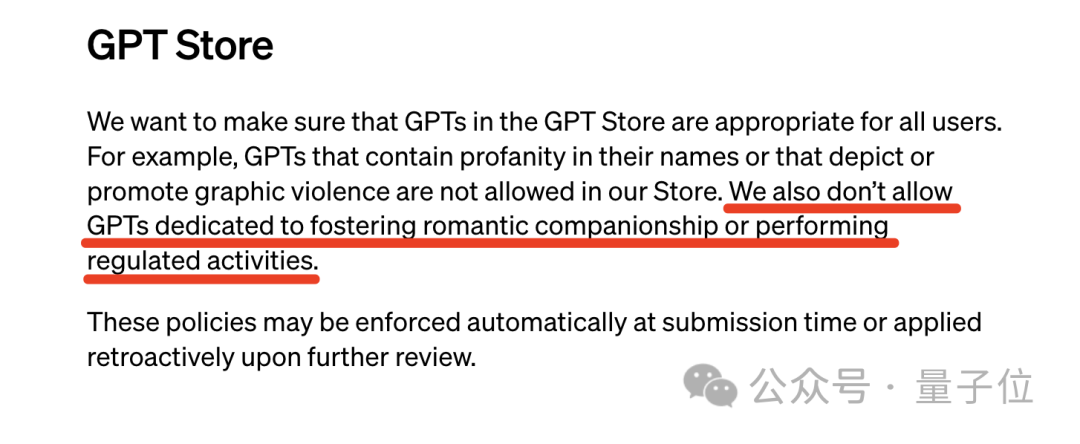
但这却与OpenAI自己的规则背道而驰:
我们也不允许GPT致力于培养浪漫的伴侣关系或从事受监管的活动。
以及还有不适合未成年人相关的规定:

虽然OpenAI在1月10日刚刚更新了GPT Store的使用政策,但就从目前的各种乱象上来看,监管这事还是任重而道远的。
也有好用的GPTs
当然GPT Store中也有不少优质应用,官方榜单中有很多网友体验后表示“好用”。
例如趋势榜第一的Consensus,就得到了学术界的夸奖。
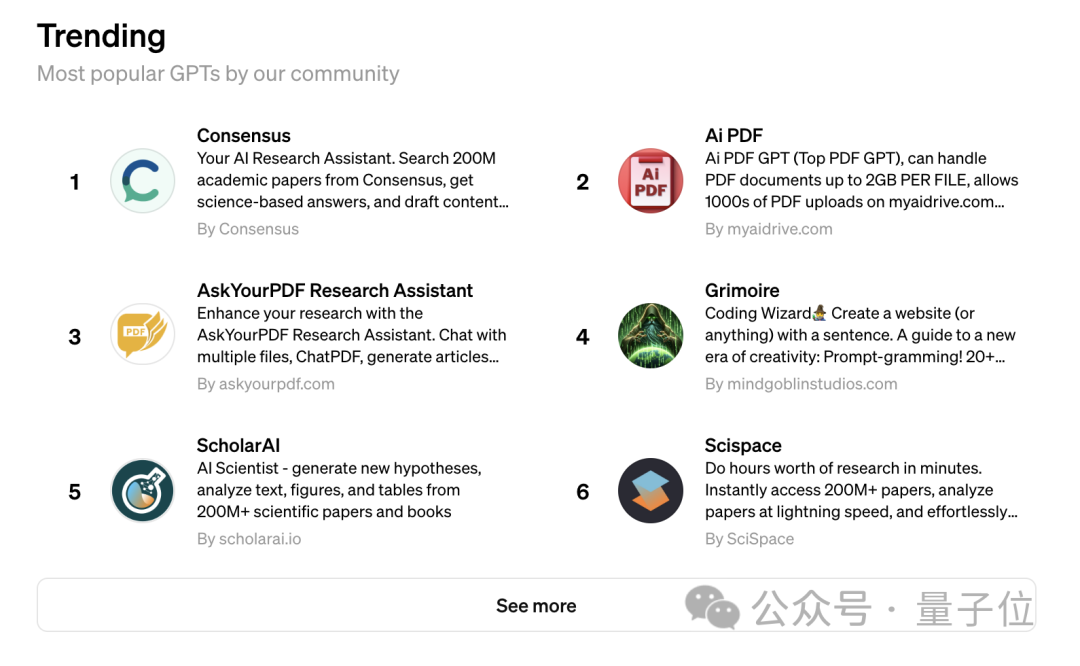
这是一款AI研究助手,之前叫做ResearchGPT。它更像是一款“搜索引擎,号称可以从2亿篇学术论文中搜索出科学的答案,每个结论都带有引用。
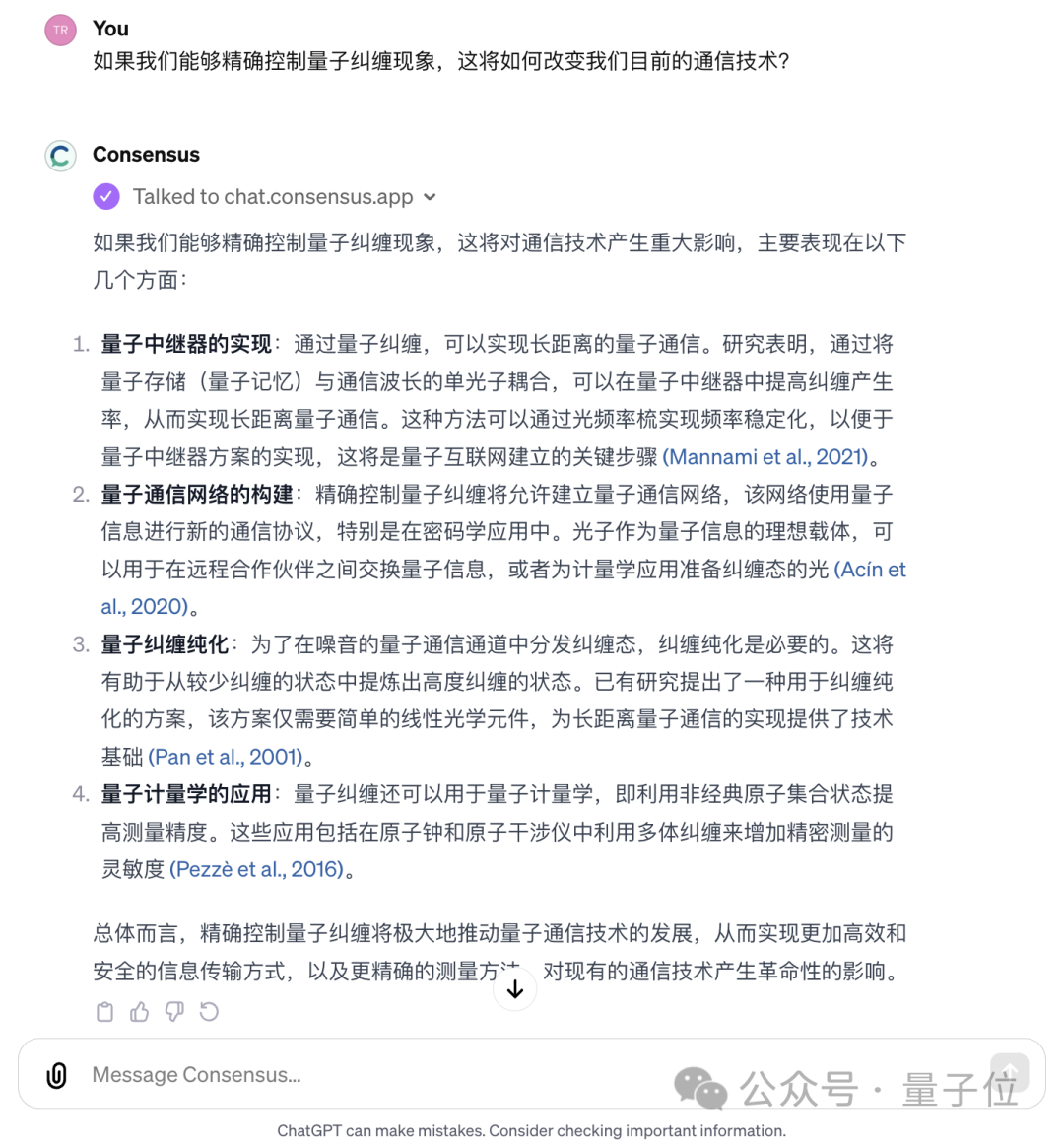
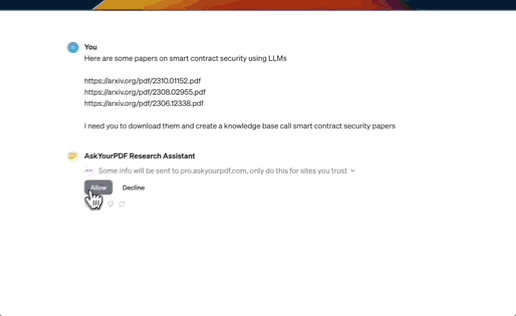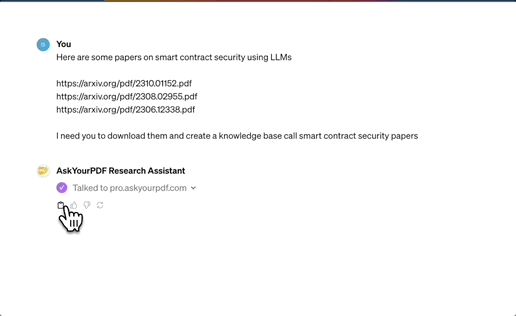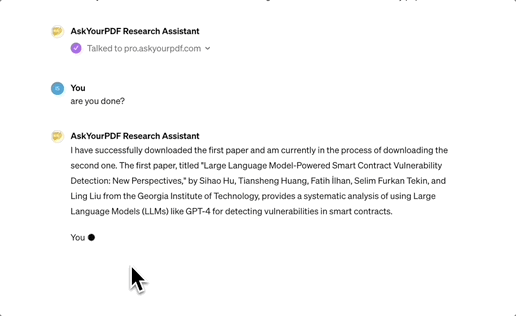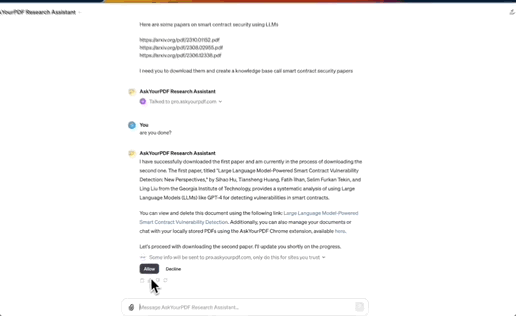
像是趋势榜前三的另外两个PDF解读工具亦是插件。
其中Ai PDF可处理2GB大小的PDF文档,AskYourPDF可同时解读多个文件,结果均带有来源出处。
编程方面,Code Tutor受到了广泛好评,它由非盈利教育组织可汗学院创建,不会帮你写代码,而是一步步提供方法指导、答疑解惑,网友反馈非常适合初学者入门。

要想一句话直接编写代码,能成功跑起来的那种,Grimoire成为网友首选。

像是有网友分享的这个能随光标移动而变化的网页,就是由Grimoire编写的。
生成的代码99%是正确的。

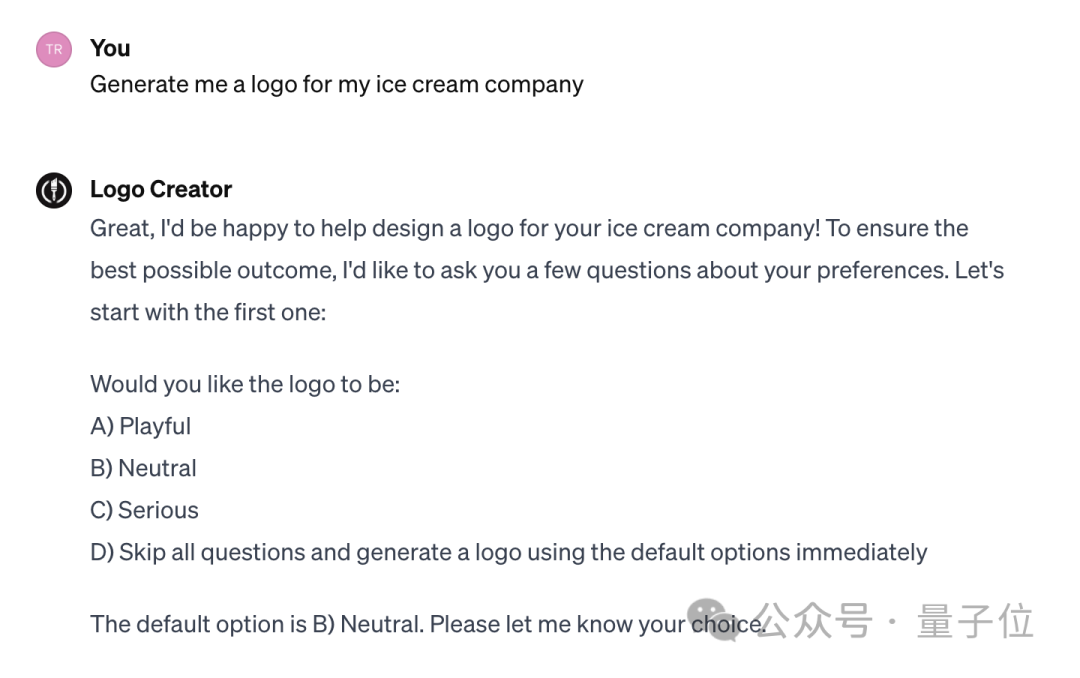
绘图方面,网友们比较喜欢的有Logo Creator。它会根据用户的需求给出一些选项让用户选择,以此来设定用户偏好:
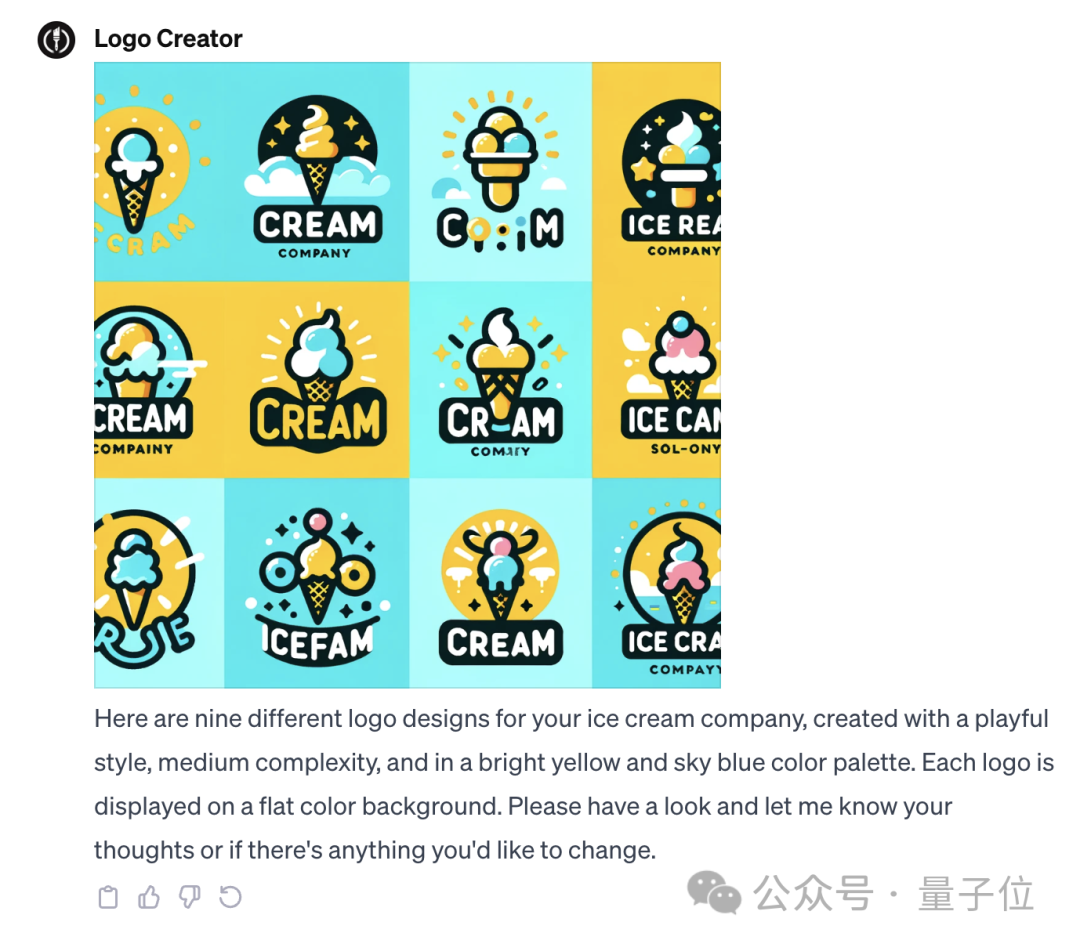
最后一次性可生成9个不同的Logo:
以上就是GPT Store开张即遭遇问题:山寨、刷量、违禁内容层出不穷的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/440492.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















