实话实说,技术的更新速度确实非常快,这也导致了学术界中一些旧有的方法逐渐被新的方法所取代。最近,浙江大学的研究团队提出了一种名为gaussians的新方法,引起了广泛的关注。这种方法在解决问题上有着独特的优势,并且已经在工作中得到了成功的应用。尽管nerf在学术界逐渐失去了一些影
为了帮助尚未通过关卡的玩家们,我们来一起了解一下游戏解谜的具体方法吧。
要帮助还没有过关的玩家们,我们可以一起了解具体的解谜方法。为此,我找到了一篇关于解谜的论文,链接在这里:https://arxiv.org/pdf/2401.01339.pdf。大家可以通过阅读这篇论文来了解更多解谜的技巧。希望这对于玩家们能够有所帮助!
本文旨在解决从单目视频中建模动态城市街道场景的问题。最近的方法扩展了NeRF,将跟踪车辆姿态纳入animate vehicles,实现了动态城市街道场景的照片逼真视图合成。然而,它们的显著局限性在于训练和渲染速度慢,再加上跟踪车辆姿态对高精度的迫切需求。这篇论文介绍了Street Gaussians,一种新的明确的场景表示,它解决了所有这些限制。具体地说,动态城市街道被表示为一组点云,这些点云配备有语义logits和3D Gaussians,每一个都与前景车辆或背景相关联。
为了对前景对象车辆的动力学进行建模,可以使用可优化的跟踪姿态以及动态外观的动态球面谐波模型对每个对象点云进行优化。这种显式表示方法允许简单地合成目标车辆和背景,并且在半小时的训练内以133 FPS(1066×1600分辨率)进行场景编辑操作和渲染。研究人员对这种方法进行了多个具有挑战性的基准评估,其中包括KITTI和Waymo Open数据集。
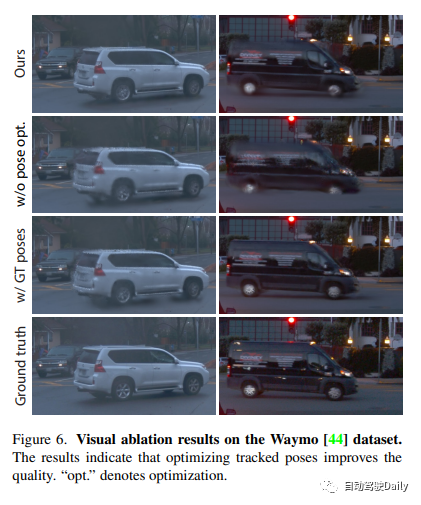
实验结果表明,我们提出的方法在所有数据集上始终优于现有技术。尽管我们仅仅依赖于现成跟踪器的姿态信息,但是我们的表示方法提供的性能与使用真实姿态信息所实现的性能相当。
为了帮助还没有过关的玩家们,我给大家提供了一个链接:https://zju3dv.github.io/streetgaussians/,这里可以找到具体的解谜方法。大家可以点击链接参考一下,希望能帮到你们。
Street Gaussians方法介绍
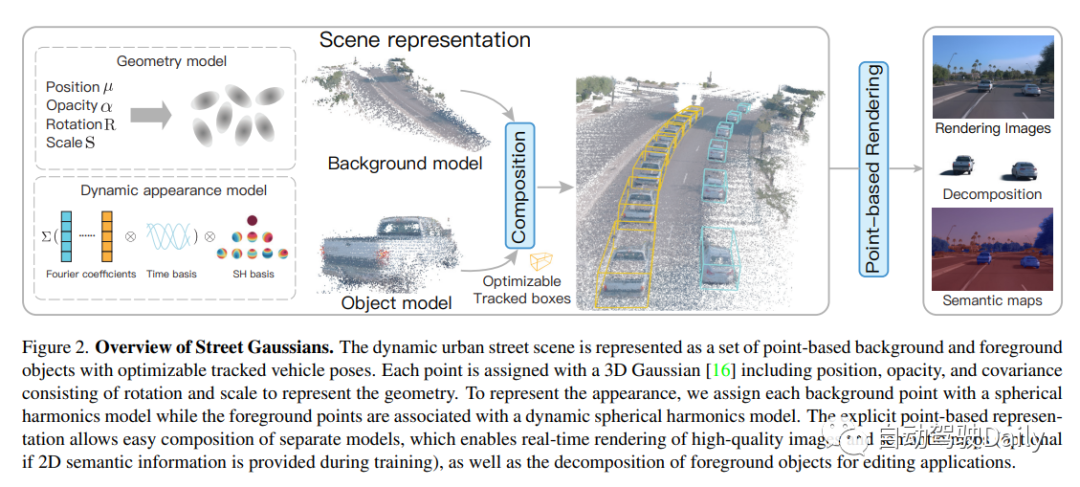
给定从城市街道场景中的移动车辆捕获的一系列图像,本文的目标是开发一个能够为任何给定的输入时间步长和任何视点生成真实感图像的模型。为了实现这一目标,提出了一种新的场景表示,命名为Street Gaussians,专门用于表示动态街道场景。如图2所示,将动态城市街道场景表示为一组点云,每个点云对应于静态背景或移动车辆。显式基于点的表示允许简单地合成单独的模型,从而实现实时渲染以及编辑应用程序的前景对象分解。仅使用RGB图像以及现成跟踪器的跟踪车辆姿态,就可以有效地训练所提出的场景表示,通过我们的tracked车辆姿态优化策略进行了增强。
Street Gaussians概览如下所示,动态城市街道场景表示为一组具有可优化tracked车辆姿态的基于点的背景和前景目标。每个点都分配有3D高斯,包括位置、不透明度和由旋转和比例组成的协方差,以表示几何体。为了表示apperence,为每个背景点分配一个球面谐波模型,而前景点与一个动态球面谐波模型相关联。显式的基于点的表示允许简单地组合单独的模型,这使得能够实时渲染高质量的图像和语义图(如果在训练期间提供2D语义信息,则是可选的),以及分解前景目标以编辑应用程序
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 ViiTor实时翻译
ViiTor实时翻译
AI实时多语言翻译专家!强大的语音识别、AR翻译功能。
 116 查看详情
116 查看详情 
实验结果对比
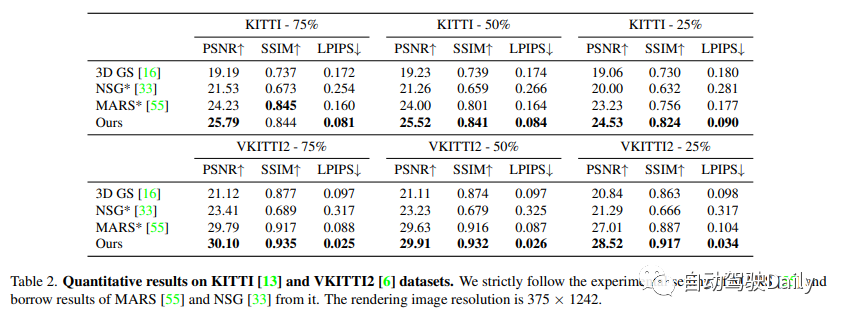
我们在Waymo开放数据集和KITTI基准上进行了实验。在Waymo开放数据集上,选择了6个记录序列,其中包含大量移动物体、显著的ego运动和复杂的照明条件。所有序列的长度约为100帧,选择序列中的每10张图像作为测试帧,并使用剩余的图像进行训练。当发现我们的基线方法在使用高分辨率图像进行训练时存在较高的内存成本时,将输入图像缩小到1066×1600。在KITTI和Vitural KITTI 2上,遵循MARS的设置,并使用不同的训练/测试分割设置来评估。在Waymo数据集上使用检测器和跟踪器生成的边界框,并使用KITTI官方提供的目标轨迹。

将本文的方法与最近的三种方法进行比较。
(1) NSG将背景表示为多平面图像,并使用每个目标学习的潜在代码和共享解码器来对运动目标进行建模。
(2) MARS基于Nerfstudio构建场景图。
(3) 3D高斯使用一组各向异性高斯对场景进行建模。
NSG和MARS都是使用GT框进行训练和评估的,这里尝试了它们实现的不同版本,并报告了每个序列的最佳结果。我们还将3D高斯图中的SfM点云替换为与我们的方法相同的输入,以进行公平比较。详见补充资料。



原文链接:https://mp.weixin.qq.com/s/oikZWcR47otm7xfU90JH4g
以上就是逼真实时渲染:基于Street Gaussians的动态城市场景建模的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/445843.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫