
本文记录《ImageNet Classification with Deep Convolutional Neural Networks》论文阅读及AlexNet复现。汇总了top-1/top-5错误率、卷积运算、ReLU、局部响应归一化等知识点,并用PaddlePaddle复现该网络,其含5个卷积层和3个全连接层,还介绍了网络结构与参数情况。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AlexNet-经典神经网络论文阅读记录及复现
一、论文中涉及的“小知识点”汇总:
1、top-1 and top-5 error rates.
top-1 and top-5 error rates 是ImageNet图像分类大赛的两个评价标准。 首先介绍一下top-1 error rates。神经网络模型应用于图像分类中,最后的softmax层对应的相应类别会输出不同的概率,我们取最大的概率为模型输出的分类结果,即为该模型预测的分类类别。先看top-1 error rates的公式:Top-1 = (正确标记与模型输出的标记不同的样本) / 总样本。 #换句话说,就是:预测错误的样本 / 总样本(也就是预测错误率)。这里也就体现了“error”的意义。对于Top-5:Top-5 = (正确标记不在模型输出的前五个最佳标记中的样本) / 总样本。#详细的解释:对于一张图片,输入AlexNet网络模型中,该网络设计的最后一层softmax有一千个输出(即一千个类别),所以有一千个概率输出。将这一千个概率从大到小进行排序,取前五个概率,如果输入的图片类别属于这前五个类别中的一个,则不计入Top-5公式的分子当中。
2、2D convolution and computation.
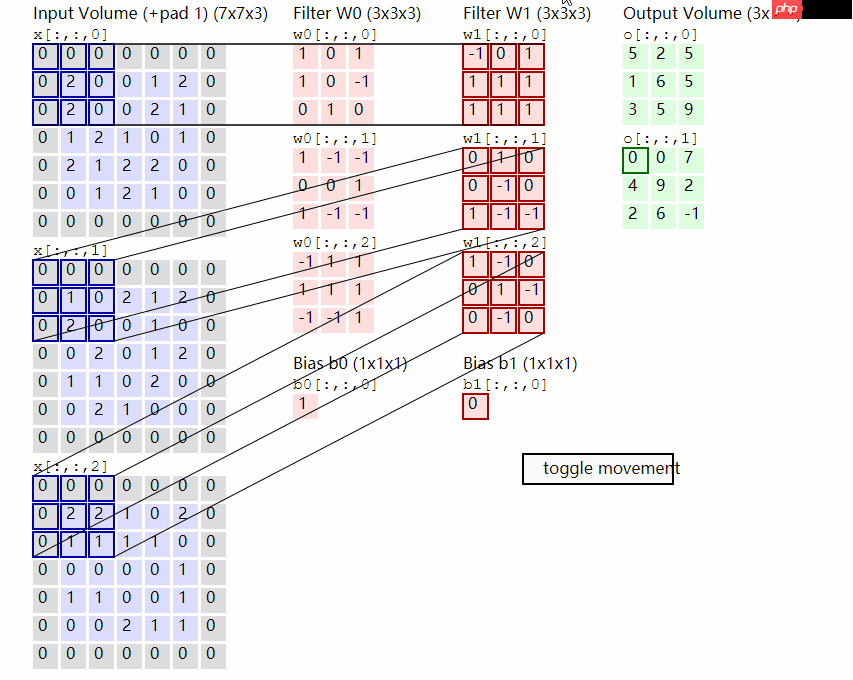
卷积运算,一种特征提取方法。通过卷积运算,可以将图像的特征进行抽象,它提高了特征提取的能力。所以,如果从一种直观感觉这一角度去理解卷积神经网络为什么会在图像领域收到一个很好的效果,相比于只有全连接层的神经网络。我觉得正是卷积层的加入,使得这一网络具有“高层语义”的表达能力。
3、神经网络的“神秘性”
我在这里写的“神秘性”的意思是,主要是我个人的理解(也可以认为我在瞎扯淡)。 在这篇论文Introduction部分的第四段中有这样一句话:Our final network contains five convolutional and three fully-connected layers, and this depth seems to be important: we found that removing any convolutional layer(each of which contains no more than 1% of the model's parameters)resulted in inferior performance.它的意思是说,在AlexNet网络中,如果去除掉任意一个卷积层(尽管每个卷积层所含的参数量还不到整个网络参数量的百分之一)都会是整个网络的表现下降。我觉得这是一件很有意思的事情,因为你无法知道为什么会这样,就像在论文Visualizing and Understanding Convolutional Networks中提到的那样:There is no clear understanding of why they perform so well, or how they might be improved. 似乎并没有严格的数学证明来证明它,我觉得这使得它同时兼具理性和感性的魅力。这也是神经网络最吸引我的地方。
4、ReLU Nonlinearity.
类似于生物的神经元的激活,人工神经网络的神经元的激活也是一样的道理,只有当这一刺激达到一定程度,我们的神经元才会做出一定的反应,不然,它是不会做出任何反应的。为了模拟这一生物过程,相应的,我们需要一定的方法,引入一定的概念,才能对这一过程进行模拟。于是激活函数这一概念便被引入进来,用相应的数学方法来完成对这一过程的模拟。另外,如果不使用激活函数,就相当于激活函数是fx = x,也就是说上一层与下一层之间是线性关系,那么再多层的这种线性关系就相当于是一层的线性关系。那么这样,网络的逼近能力也就非常的有限了。
下面是各种不同的激活函数:
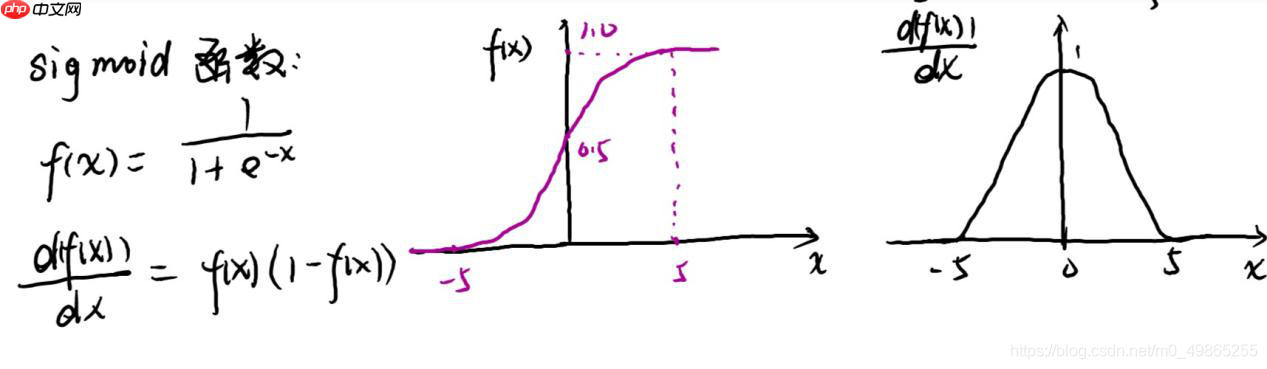
sigmoid:
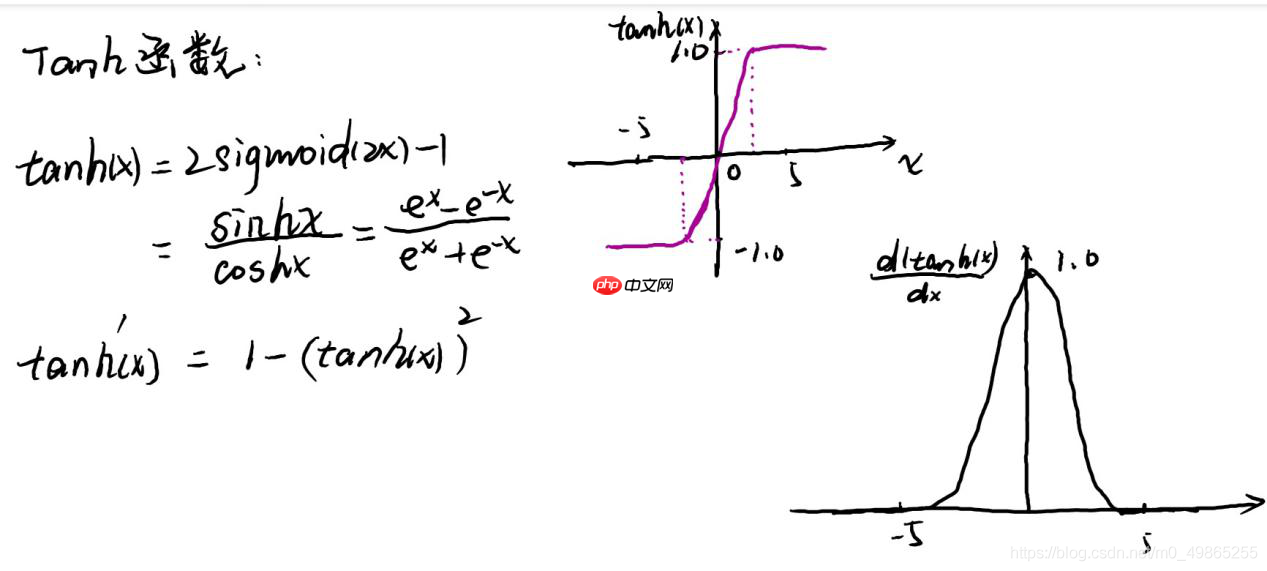
tanh:
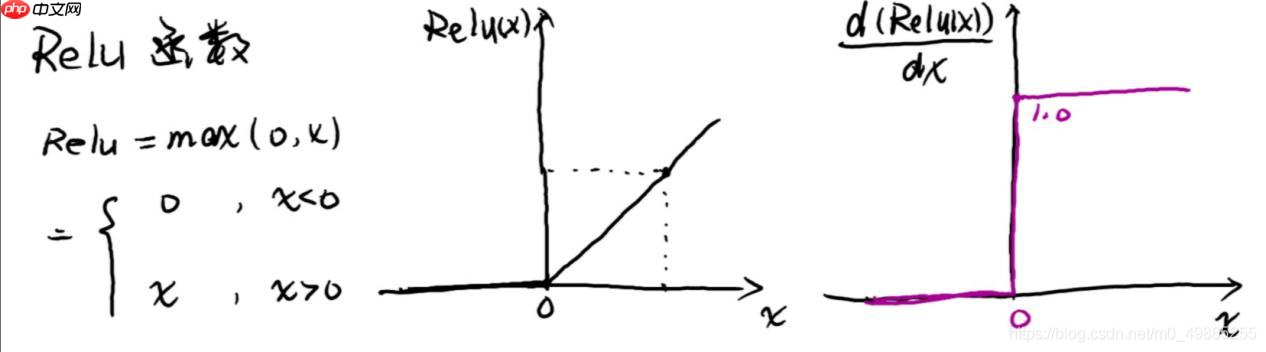
ReLU:
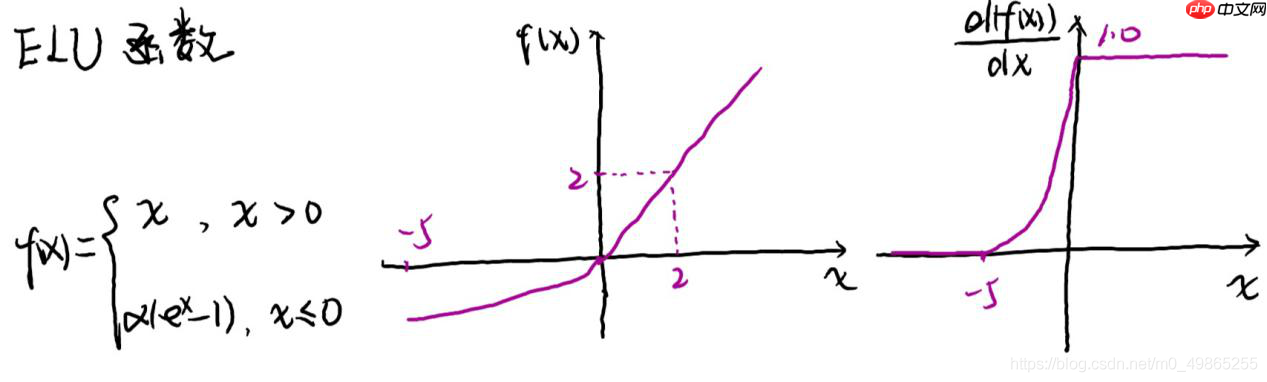
ELU:
softmax:
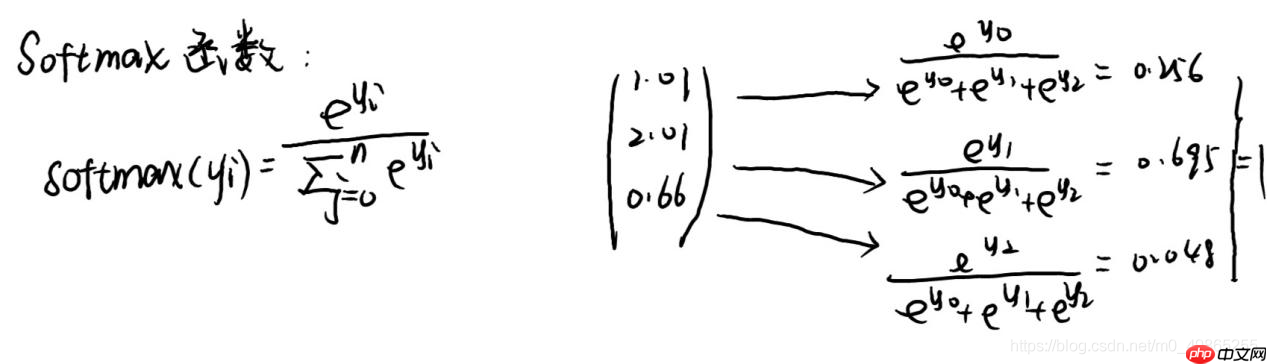
5、Back-propagation:
反向传播和误差反向传播有着相同的思想:将“关系”从末端传递到头部。只是通过不同的“关系”表达的而已。
反向传播算法: 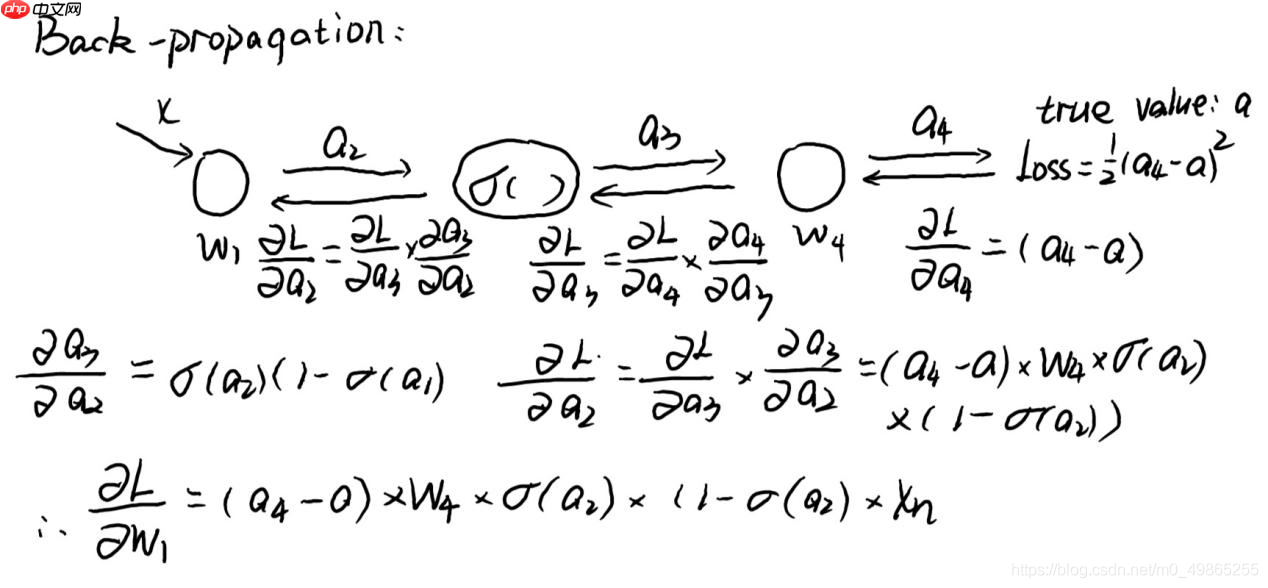
误差反向传播中,误差的定义:

误差反向传播算法:
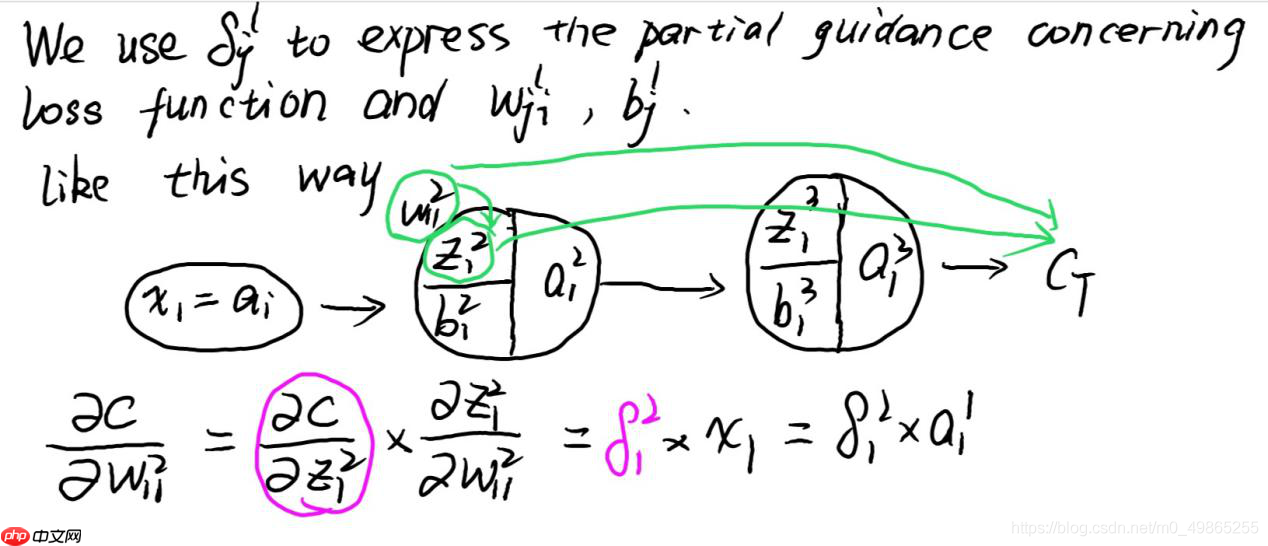
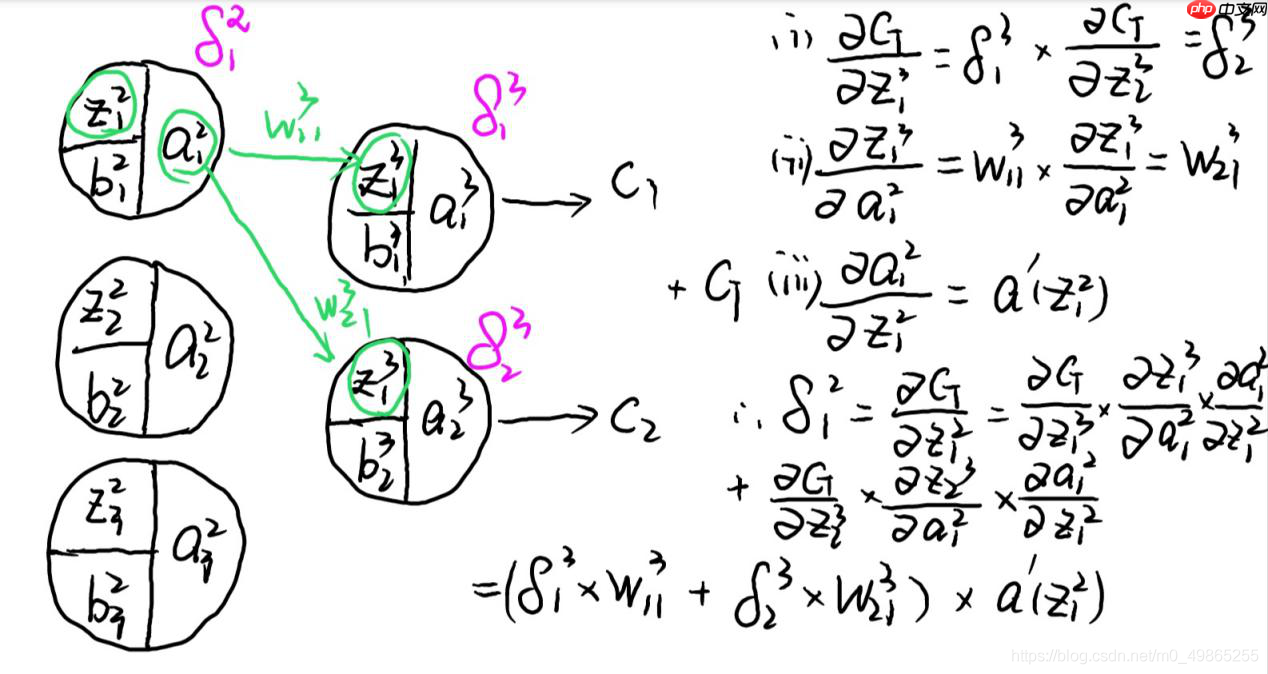

6、Multiple GPUs training:
将卷积神经网络中的运算平均拆分到两个GPU上。
7、Local Response Normalization.(局部响应归一化)
局部响应归一化(LRN)是一种竞争机制,对局部神经元活动创建的竞争机制。通过局部响应归一化,使其中响应较大的神经元活动更剧烈,并抑制其它反馈较小的神经元,增强了模型的泛化能力。
8、Overlapping pooling.
所谓的“重叠池化”,简而言之,就是filter size > strides。
9、Reducing Overfitting.(with Data Augmentation and Dropout )
该篇论文中减小过拟合的两个方法就是数据增强和“Dropout”方法。 论文中介绍了两种数据增强的方法,这里稍微记录一下第二种:(PCA主成分分析方法,一种使用广泛的数据降维方法。)
In [ ]
#首先,设置环境:import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.io import Dataset, BatchSampler, DataLoaderfrom paddle.vision.transforms import ToTensorimport numpy as np#使用paddlepaddle搭建搭建AlexNet:in_channels = 3#conv_filter_numsfilter_nums1 = 96filter_nums2 = 256filter_nums3 = 384#convcsize1 = 11csize2 = 5csize3 = 3cstride1 = 4cstride2 = 1#Maxpooling pstride = 2psize = 3 #this is what was called overlapping pooling.#MaxPool3D(kernel_size, stride=None, padding=0)#Conv3D(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros')class AlexNet(paddle.nn.Layer): def __init__(self, num_classes): super(AlexNet, self).__init__() self.conv1 = nn.Conv2D(in_channels, filter_nums1, (csize1, csize1), cstride1, padding = 1) self.pool1 = nn.MaxPool2D(psize, pstride, padding = 2) self.conv2 = nn.Conv2D(filter_nums1, filter_nums2, (csize2, csize2), cstride2, padding = 2) self.pool2 = nn.MaxPool2D(psize, pstride, padding = 0) self.conv3 = nn.Conv2D(filter_nums2, filter_nums3, (csize3, csize3), cstride2, padding = 1) self.conv4 = nn.Conv2D(filter_nums3, filter_nums3, (csize3, csize3), cstride2, padding = 1) self.conv5= nn.Conv2D(filter_nums3, filter_nums2, (csize3, csize3), cstride2, padding = 1) self.pool5 = nn.MaxPool2D(psize, pstride, padding = 0) self.flatten = nn.Flatten() self.fclayer1 = nn.Linear(9216, 4096) self.fclayer2 = nn.Linear(4096, 4096) self.fclayer3 = nn.Linear(4096, num_classes) self.lrn = nn.LocalResponseNorm(size=96) #tatal channels? what is that mean? self.relu = nn.ReLU() self.dropout = nn.Dropout(p = 0.5) self.softmax = nn.Softmax() def forward(self, in_data): out_data = self.conv1(in_data) out_data1 = self.lrn(out_data) out_data1 = self.relu(out_data1) out_data1 = self.pool1(out_data1) out_data1 = self.conv2(out_data1) out_data1 = self.relu(out_data1) out_data1 = self.pool2(out_data1) out_data1 = self.conv3(out_data1) out_data1 = self.relu(out_data1) out_data1 = self.conv4(out_data1) out_data1 = self.relu(out_data1) out_data1 = self.conv5(out_data1) out_data1 = self.relu(out_data1) out_data1 = self.pool5(out_data1) out_data1 = self.flatten(out_data1) out_data1 = self.dropout(out_data1) out_data1 = self.fclayer1(out_data1) out_data1 = self.dropout(out_data1) out_data1 = self.fclayer2(out_data1) out_data1 = self.fclayer3(out_data1) out_data1 = self.softmax(out_data1) return out_data1model = paddle.Model(AlexNet(1000))model.summary((64, 3, 224, 224))
------------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =============================================================================== Conv2D-6 [[64, 3, 224, 224]] [64, 96, 54, 54] 34,944 LocalResponseNorm-2 [[64, 96, 54, 54]] [64, 96, 54, 54] 0 ReLU-2 [[64, 256, 13, 13]] [64, 256, 13, 13] 0 MaxPool2D-4 [[64, 96, 54, 54]] [64, 96, 28, 28] 0 Conv2D-7 [[64, 96, 28, 28]] [64, 256, 28, 28] 614,656 MaxPool2D-5 [[64, 256, 28, 28]] [64, 256, 13, 13] 0 Conv2D-8 [[64, 256, 13, 13]] [64, 384, 13, 13] 885,120 Conv2D-9 [[64, 384, 13, 13]] [64, 384, 13, 13] 1,327,488 Conv2D-10 [[64, 384, 13, 13]] [64, 256, 13, 13] 884,992 MaxPool2D-6 [[64, 256, 13, 13]] [64, 256, 6, 6] 0 Flatten-3 [[64, 256, 6, 6]] [64, 9216] 0 Dropout-2 [[64, 4096]] [64, 4096] 0 Linear-4 [[64, 9216]] [64, 4096] 37,752,832 Linear-5 [[64, 4096]] [64, 4096] 16,781,312 Linear-6 [[64, 4096]] [64, 1000] 4,097,000 Softmax-2 [[64, 1000]] [64, 1000] 0 ===============================================================================Total params: 62,378,344Trainable params: 62,378,344Non-trainable params: 0-------------------------------------------------------------------------------Input size (MB): 36.75Forward/backward pass size (MB): 550.85Params size (MB): 237.95Estimated Total Size (MB): 825.56-------------------------------------------------------------------------------
{'total_params': 62378344, 'trainable_params': 62378344}
以上就是AlexNet-经典神经网络论文阅读记录及复现1的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/45872.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























