
投毒攻击指攻击者通过篡改或添加恶意训练数据影响模型训练,降低其预测准确性。文中通过两个实验说明:一是用PaddleHub构造对抗样本(调整图像亮度),使ResNet模型对动物图像的预测准确率从99%降至85%;二是用Paddle实现感知机,添加5个恶意数据后,模型训练受影响,预测准确性下降,体现了投毒攻击的危害。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

投毒攻击
如果机器学习模型是根据潜在不可信来源的数据(例如Yelp、Twitter等)进行训练的话,攻击者很容易通过将精心制作的样本插入训练集中来操纵训练数据分布,以达到改变模型行为和降低模型性能的目的。这种类型的攻击被称为“数据投毒”(Data Poisoning)攻击,它不仅在学术界受到广泛关注,在工业界也带来了严重危害。例如微软Tay:一个旨在与Twitter用户交谈的聊天机器人,仅在16个小时后被关闭,只因为它在受到投毒攻击后开始提出种族主义相关的评论。这种攻击令我们不得不重新思考机器学习模型的安全。
一句话来概括投毒攻击,即攻击者通过篡改训练数据或添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性。
实验一:使用paddhub预测动物图像,通过构造对抗样本降低模型预测效果
(一)ResNet 残差网络的详细解释
随着网络深度增加,会出现一种退化问题,也就是当网络变得越来越深的时候,训练的准确率会趋于平缓,但是训练误差会变大,这明显不是过拟合造成的,因为过拟合是指网络的训练误差会不断变小,但是测试误差会变大。为了解决这种退化现象,ResNet被提出。我们不再用多个堆叠的层直接拟合期望的特征映射,而是显式的用它们拟合一个残差映射。假设期望的特征映射为H(x),那么堆叠的非线性层拟合的是另一个映射,也就是F(x)=H(x)-x。假设最优化残差映射比最优化期望的映射更容易,也就是F(x)=H(x)-x比F(x)=H(x)更容易优化,则极端情况下,期望的映射要拟合的是恒等映射,此时残差网络的任务是拟合F(x)=0,普通网络要拟合的是F(x)=x,明显前者更容易优化。
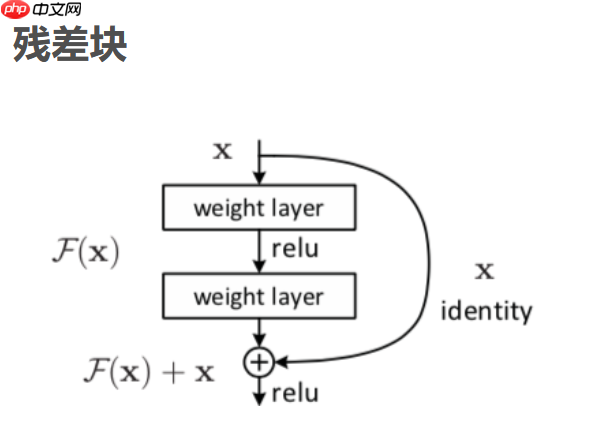
定义一个残差块的形式为y=F(x,Wi)+x,其中x和y分别为残差块的输入和输出向量,F(x,Wi)是要学习的残差映射,在上图中有2层,F=W2σ(W1X),σ是Relu激活函数,在这个表达式中为了方便起见,省略了偏置,这里的shortcut connections是恒等映射,之所以用恒等映射是因为这样没有引进额外的参数和计算复杂度。残差函数F的形式是灵活的,残差块也可以有3层,但是如果残差块只有一层,则y=W1x+x,它只是一个线性层,3层的残差块如下如所示。
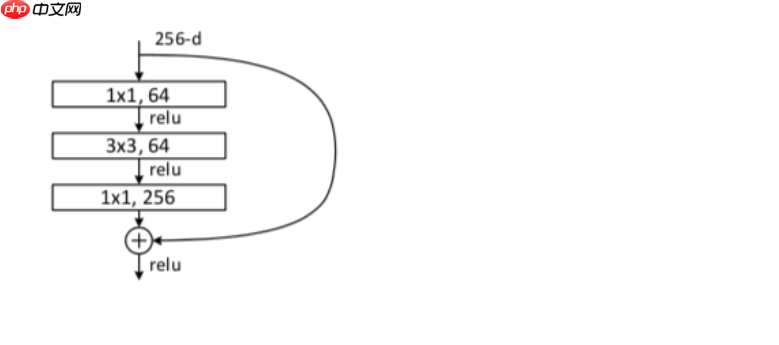
一般的我们称上图这种3层残差块为’bottleneck block’,这里1×1的卷积起到了降维的作用,并且引入了更多的非线性变换,明显的增加了残差块的深度,能提高残差网络的表示能力。
In [ ]
!pip install -U paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
In [16]
# 待预测图片test_img_path = ["./7.jpg"]import matplotlib.pyplot as plt import matplotlib.image as mpimg # 展示孟加拉虎图片img1 = mpimg.imread(test_img_path[0]) plt.figure(figsize=(10,10))plt.imshow(img1) plt.axis('off') plt.show()
(二)加载预训练模型
PaddleHub提供了动物识别模型:
resnet50_vd_animals: ResNet-vd 其实就是 ResNet-D,是ResNet 原始结构的变种,可用于图像分类和特征提取。该 PaddleHub Module 采用百度自建动物数据集训练得到,支持7978种动物的分类识别。In [ ]
import paddlehub as hubmodule = hub.Module(name="resnet50_vd_animals")
(三)预测
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。
In [4]
import cv2np_images =[cv2.imread(image_path) for image_path in test_img_path]results = module.classification(images=np_images)for result in results: print(result)
{'孟加拉虎': 0.9903932213783264}
我们可以发现预测值还是高达 99%
(四)图片投毒——制作对抗样本
通过改变图片亮度,使之与原图产生微小的差别
In [5]
import cv2import matplotlib.pyplot as plt import numpy as npfilename = '7.jpg'## [Load an image from a file]img = cv2.imread(filename)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)class Brightness: def __init__(self,brightness_factor): self.brightness_factor=brightness_factor def __call__(self, img): # 此处插入代码 rows, cols, x = img.shape c = 1 blank = np.zeros([rows, cols, x], img.dtype) return cv2.addWeighted(img, c, blank, 1-c, self.brightness_factor * 100)brightness=Brightness(0.6)img2=brightness(img)plt.imshow(img2)cv2.imwrite("6.jpg", img2)test_img_path = ["./7.jpg","./6.jpg"]
In [6]
import cv2np_images =[cv2.imread(image_path) for image_path in test_img_path]results = module.classification(images=np_images)for result in results: print(result)
{'孟加拉虎': 0.9903932213783264}{'孟加拉虎': 0.8554697632789612}
可以发现构造的样本使模型的预测结果下降到了 85%
实验二:通过Paddle实现一个感知机,篡改训练数据或添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性。
(一)数据样本生成
这里我们生成的数据集包含200个样本,2个特征 我们将使用前100个样本来训练模型,后100个样本用于进行可视化表述模型是否训练得足够好
In [7]
from sklearn.datasets import make_classificationX,y=make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0, weights=[.5,.5], random_state=17)
(二)使用Paddle进行数据预处理
In [8]
import paddletrain_data_x = Xtrain_data_y = yx_data = paddle.to_tensor(train_data_x.astype('float32'))y_data = paddle.to_tensor(train_data_y.astype('float32'))
(三)使用Paddle实现初始化感知机
我们的任务是拟合 y = w 1 w_1 w1 x 1 x_1 x1 + w 2 w_2 w2 x 2 x_2 x2+b
w 1 w_1 w1, w 2 w_2 w2,b 为学习的参数。
In [9]
linear = paddle.nn.Linear(in_features=2, out_features=1)mse_loss = paddle.nn.MSELoss()sgd_optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters = linear.parameters())
(四)开始训练
In [ ]
total_epoch = 50000for i in range(total_epoch): y_predict = linear(x_data) #print(y_predict) loss = mse_loss(y_predict, y_data) loss.backward() sgd_optimizer.step() sgd_optimizer.clear_grad() w1_after_opt = linear.weight.numpy()[0].item() w2_after_opt = linear.weight.numpy()[1].item() b_after_opt = linear.bias.numpy().item() if i%1000 == 0: print("epoch {} loss {}".format(i, loss.numpy())) print("w1 after optimize: {}".format(w1_after_opt)) print("w2 after optimize: {}".format(w2_after_opt)) print("b after optimize: {}".format(b_after_opt))print("finished training, loss {}".format(loss.numpy()))
输出:finished training, loss [0.249975]
loss处于正常范围
(五)数据投毒
接下来就进行数据投毒,即添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性。我们生成5个点,相当于占训练集的5%
In [11]
num_chaff=5chaff_X=np.array([np.linspace(-2,-1,num_chaff),np.linspace(0.1,0.1,num_chaff)]).Tchaff_y=np.ones(num_chaff)
In [12]
x_data2 = paddle.to_tensor(chaff_X.astype('float32'))y_data2 = paddle.to_tensor(chaff_y.astype('float32'))
In [ ]
total_epoch = 50000for i in range(total_epoch): y_predict = linear(x_data2) #print(y_predict) loss = mse_loss(y_predict, y_data2) loss.backward() sgd_optimizer.step() sgd_optimizer.clear_grad() w1_after_opt = linear.weight.numpy()[0].item() w2_after_opt = linear.weight.numpy()[1].item() b_after_opt = linear.bias.numpy().item() if i%1000 == 0: print("epoch {} loss {}".format(i, loss.numpy())) print("w1 after optimize: {}".format(w1_after_opt)) print("w2 after optimize: {}".format(w2_after_opt)) print("b after optimize: {}".format(b_after_opt))print("finished training, loss {}".format(loss.numpy()))
输出:finished training, loss [4.4527653e-09]
loss值开始变大
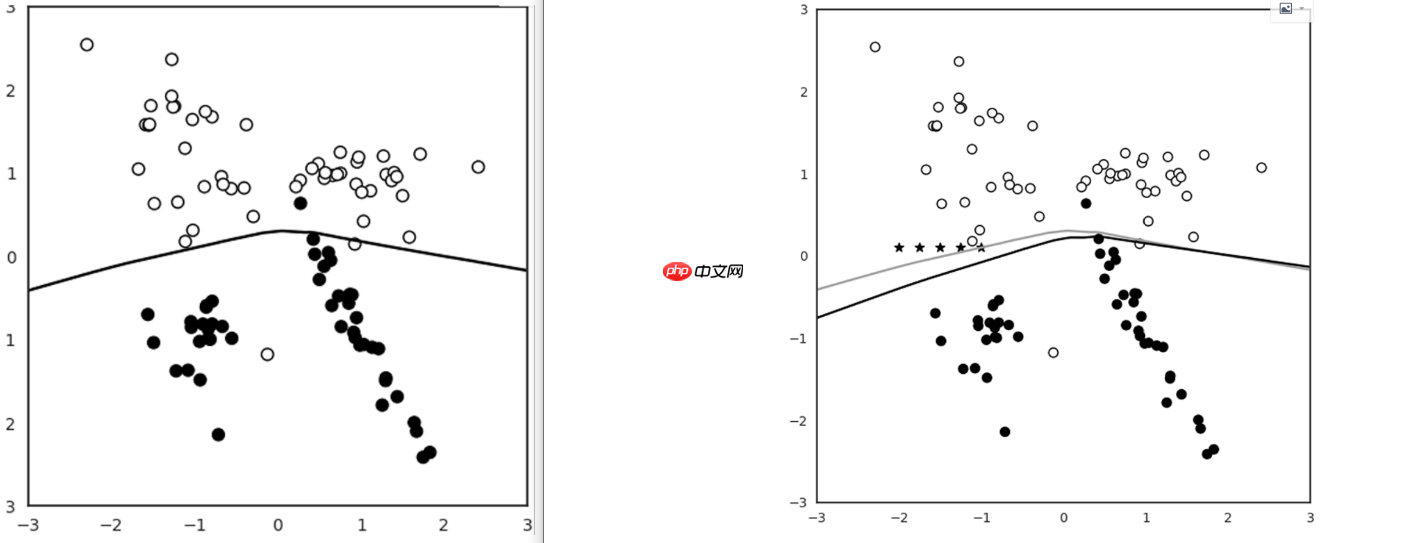
我们可以发现多了一条灰色的线,这就是新的决策边界,我们注意到此时已经有偏移了,可以看到随着迭代地重复使用,新的边界偏移地越来越多
以上就是基于Paddle实现对机器学习模型投毒攻击的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/45955.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























