译者需要改写的内容是:|需要改写的内容是:布加迪
审校需要改写的内容是:|需要改写的内容是:重楼
从文档和数据中提取洞察力对于您做出明智的决策至关重要。然而在处理敏感信息时,会出现隐私问题。结合使用LangChain与OpenAI需要改写的内容是:API,您就可以分析本地文档,无需上传到网上。
它们通过将数据保存在本地、使用嵌入和向量化进行分析以及在您的环境中执行进程来做到这一点。OpenAI不使用客户通过其API提交的数据来训练模型或改进服务。
搭建环境
创建一个新的Python虚拟环境,这将确保没有库版本冲突。然后运行以下终端命令来安装所需的库。
pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
下面详细说明您将如何使用每个库:
LangChain:您将用它来创建和管理用于文本处理和分析的语言链。它将提供用于文档加载、文本分割、嵌入和向量存储的模块。OpenAI:您将用它来运行查询,并从语言模型获取结果。tiktoken:您将用它来计算给定文本中token(文本单位)的数量。这是为了在与基于您使用的token数量收费的OpenAI需要改写的内容是:API交互时跟踪token计数。FAISS:您将用它来创建和管理向量存储,允许基于嵌入快速检索相似的向量。PyPDF:这个库从PDF提取文本。它有助于加载PDF文件并提取其文本,供进一步处理。
安装完所有库之后,您的环境现已准备就绪。
获得OpenAI需要改写的内容是:API密钥
当您向OpenAI需要改写的内容是:API发出请求时,需要添加API密钥作为请求的一部分。该密钥允许API提供者验证请求是否来自合法来源,以及您是否拥有访问其功能所需的权限。
为了获得OpenAI需要改写的内容是:API密钥,进入到OpenAI平台。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
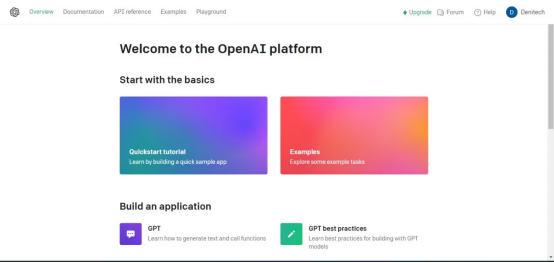
然后在右上方的帐户个人资料下,点击“查看API密钥”,将出现API密钥页面。
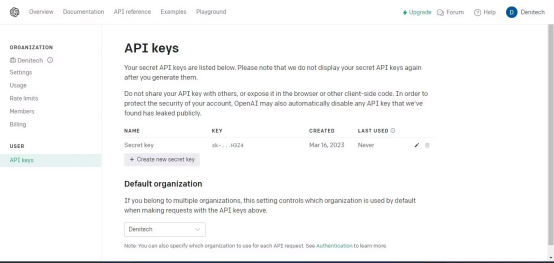
点击“创建新的密钥”按钮。为密钥命名,点击“创建新密钥”。OpenAI将生成API密钥,您应该复制并保存在安全的地方。出于安全原因,您将无法通过OpenAI帐户再次查看它。如果丢失了该密钥,需要生成新的密钥。
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")
加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
 巧文书
巧文书
巧文书是一款AI写标书、AI写方案的产品。通过自研的先进AI大模型,精准解析招标文件,智能生成投标内容。
 61 查看详情
61 查看详情 
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):n")
嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:”__main__”构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
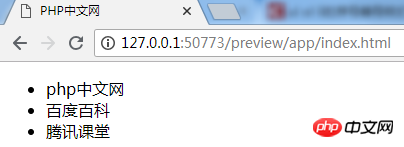
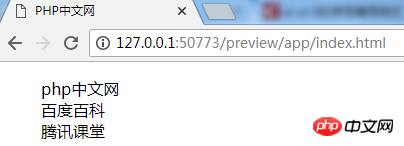
以下截图展示了对PDF进行分析的结果
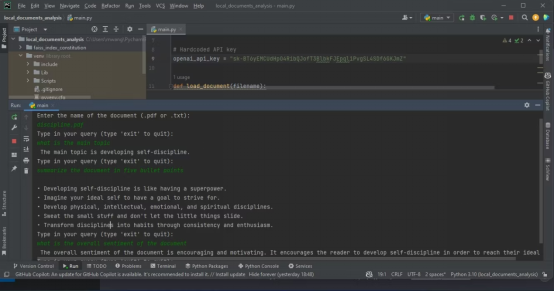
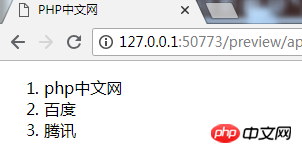
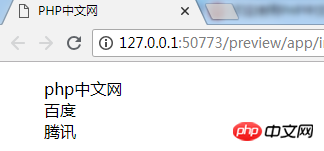
下面的输出显示了分析含有源代码的文本文件的结果。
确保所要分析的文件是PDF或文本格式。如果您的文档采用其他格式,可以使用在线工具将它们转换成PDF格式。
可以在GitHub代码库中获取完整的源代码:https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
原文标题:How需要改写的内容是:to需要改写的内容是:Analyze需要改写的内容是:Documents需要改写的内容是:With需要改写的内容是:LangChain需要改写的内容是:and需要改写的内容是:the需要改写的内容是:OpenAI需要改写的内容是:API,作者:Denis需要改写的内容是:Kuria
需要改写的内容是:
以上就是使用LangChain和OpenAI API进行文档分析的方法的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/459690.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫