
前言
最近疫情宅在家里,人的思绪就有点飘散。
回想这么多年的经历,算法啊、框架啊、前端啊、面试啊,一阵唏嘘跟感慨。那些年遇到的面试里,某大厂大佬问过我一个问题,“说到缓存,你了解LRU算法么,能实现一下吗?”
具体的问题大概是这样的:
请你设计并实现一个满足LRU(最近最少使用)缓存约束的数据结构。
实现有如下函数的LRUCache类:
LRUCache(int capacity):以正整数作为容量capacity初始化LRU缓存get(int key):如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1set(int key, int value):如果key已经存在,则变更其value;如果不存在,则向缓存中插入该组key-value键值对。如果插入操作导致关键字数量超过capacity,则应该删除最久未使用的key以及其对应的value。
函数get和set必须以O(1)的时间复杂度运行。
当时也没有时间跟精力好好总结,今天就姑且拿出来说一说吧。
什么是LRU?
确实,在我们日常开发过程中,经常会遇到缓存。离我们比较近的像浏览器会缓存已经加载的网页,vue的computed会缓存计算结果,keep-alive也基于缓存,等等等等。缓存可以提高我们app的响应速度,带来更好的用户体验。
但是我们知道缓存的大小通常是有限制的。当缓存满了,我们就需要删除部分数据来腾出空间,问题在于我们基于什么标准来删除数据。有很多缓存算法来帮助我们处理这个场景,比如最常见的淘汰策略有FIFO(先进先出)、LFU(最少使用)、LRU(最近最少使用)等等,我们今天的主角当然是其中的LRU。
LRU的核心思想简单来说就是如果数据最近被访问过,那么将来被访问的几率也更高,为了给新数据腾出空间,从缓存中把最老的数据删除掉,留下最近被使用过的数据。
举个例子?
光从概念看,很抽象,我们来看一个例子。我们先再有一个容量为4的缓存,我们要在里面存入1~4这几个数字,在访问所有这四个数字之后,基于LRU的策略,它们在缓存里的状态应该是这样的:
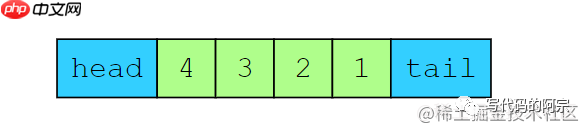
缓存状态
我们通过head跟tail来指示目前的排序,头部head这里是最近最多使用(most recently used)的元素,然后尾部tail这里就是最近最少使用(least recently used)的元素。
假设我们现在缓存另一个元素5,那么对于我们的LRU缓存,我们需要删掉最近最少使用的元素,也就是处于缓存tail处的1,这时候我们的缓存变成了这样:
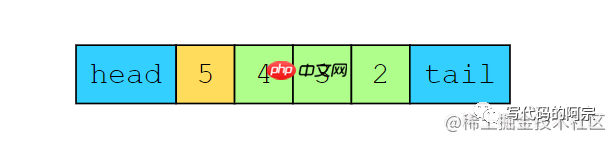
缓存状态
再把1移除之后,2变成了最近最少使用的元素,如果我们这个时候访问2呢?就会变成这样:
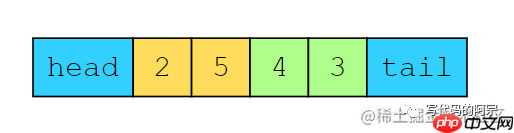
缓存状态
2被移到缓存的head处,而3这个时候变成了在需要时会被删掉的元素。
对于输入:
代码语言:javascript代码运行次数:0运行复制
get(10), set(10, 100), get(10), set(15, 150), get(10), set(30, 300), get(15), get(30)结果:
代码语言:javascript代码运行次数:0运行复制
-1, 100, 100, -1, 300这下我们能理解LRU的功能了吧~
如何设计LRU?
关联上面的例子,以及固定容量保存某些数据,我们天然地会想到数组。我们可以初始化一个指定大小的数组,用于保存缓存的数据。至于如何找到谁才是最近最少使用的元素,我们可以每次访问一个元素时更新它的时间戳,然后根据时间戳进行排序,最近最多使用(most recently used)的元素放在数组的前面,最近最少使用(least recently used)的元素放在数组的末尾。不过这样我们每次get和set时都要排序,时间复杂度肯定达不到O(1)。有没有办法让数据放进来的时候就排好序?
每次我们通过get访问一个缓存的元素,只要它存在于缓存中,那它肯定就变成最近最多使用(most recently used)的元素了,要被提取到数组的最前面。而我们调用set时更不必说,也要做一样的处理,其它元素维持之前的排序就好了。但是数组并不适用频繁插入删除的场景,插入一个元素到数组的最前面,会因为大量的复制带来开销,从数组中删除一个元素也会带来大量的开销。我们知道链表倒是很擅长处理频繁插入删除的场景。
如果借助链表来保存缓存的元素:
 存了个图
存了个图
视频图片解析/字幕/剪辑,视频高清保存/图片源图提取
 17 查看详情
17 查看详情  当我们进行
当我们进行set操作的时候,会出现以下几种情况:如果要set(key,value)已经存在于链表之中了(根据key来判断),那么我们需要把链表中旧的数据节点删除,然后把新的数据插入到链表的头部。、如果要set(key,value)的数据没有存在于链表之后,我们我们需要判断下缓存区是否已满,如果满的话,则把链表尾部的节点删除,之后把新的数据插入到链表头部。如果没有满的话,直接把数据插入链表头部即可。对于 get 操作,则会出现以下情况如果要get(key)的数据存在于链表中,则把value返回,并且把该节点删除,删除之后把它插入到链表的头部。如果要get(key)的数据不存在于链表之后,则直接返回-1即可。
这样我们的缓存列表肯定是有序的,我们知道要加元素时往哪里加,要删元素时从哪里删。
但是我们也知道链表的特性,读取时得按顺序读取,如果我们判断一个key在不在缓存中需要通过遍历整个列表,那我们把数组换成链表就没有意义了。要说拿到一个key就能判断它存不存在,就得说到哈希表,可以以O(1)的时间复杂度读取元素。如果我们用哈希表来记录链表中已经存在的节点,我们就可以快速判断当前这个key有没有数据被保存在链表中了。如果一个元素已经在链表中缓存了,那要把它提前到链表的头部head位置,我们还得把这个元素所在节点前后两个节点连接起来。对于单链表,找到它后面的节点很方便,要找到它前面的节点就得再次遍历链表了,这个时间复杂度太大了,所以我们使用一个额外的字段来记录它前一个节点,也就是双链表。
还用上面的例子来说明,我这边用双链表来记录最近被访问的元素,维护删除节点的先后顺序,链表的head是最近最多使用的元素,而tail则是最近最少使用的元素,实际上反过来也没什么问题,大家自己实现时按自己喜好来就好。那我们这边所有新增的元素就会被插入到链表的head处,所有被读取到的元素也会被移动到链表的head处。
还看上面四个数字的case,一开始我们还是按顺序访问1~4四个元素:
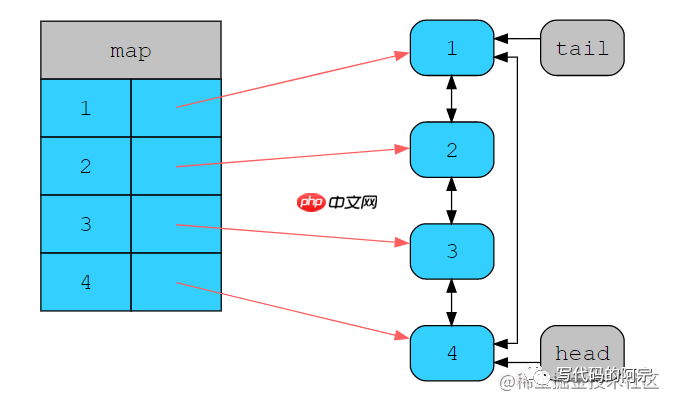
缓存状态
这是我们的初始状态,如果我们这个时候要访问5,这个时候哈希表里是不存在的,而且哈希表也满了,我们需要删除LRU元素,既然现在链表尾部tail指向1,那就删了它:
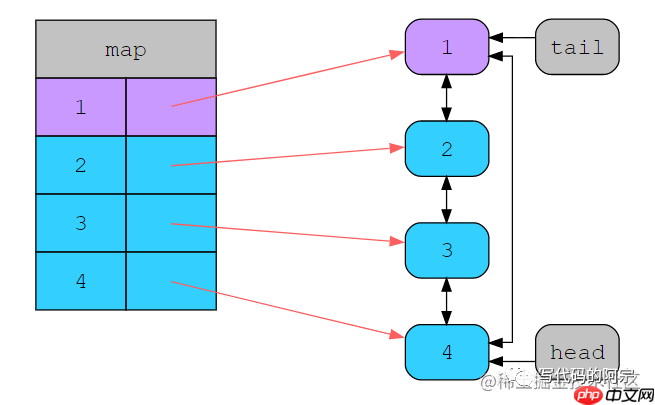
缓存状态
之后再把5加入进来:
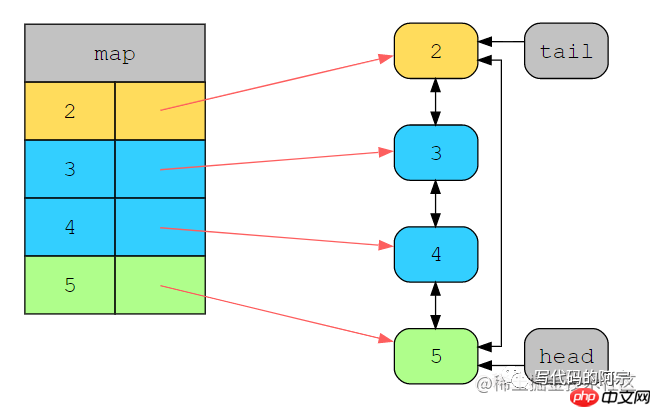
缓存状态
这样5被加入到哈希表以及链表的head处,而2变成了新的LRU元素。现在我们来访问2:
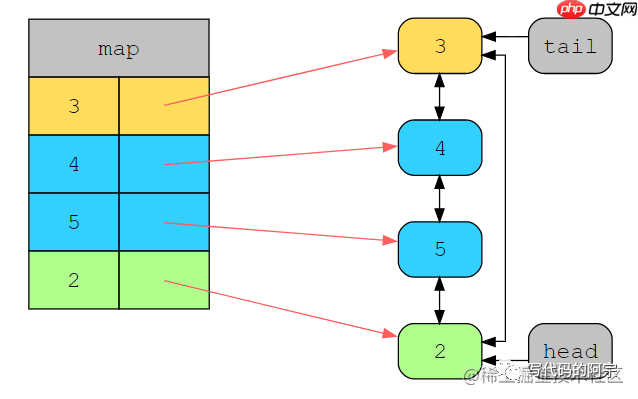
缓存状态
2这个时候就变成了最近最多使用的元素了,移到到链表的head处,此时3变成了LRU元素。这个时候我们再访问5:
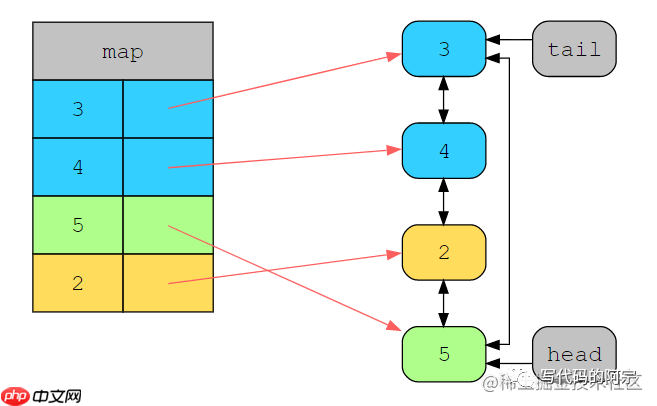
缓存状态
5又被移动到了链表的head处,而3还是我们的LRU元素。
如何实现LRU?
这个时候我们肯定已经对整个流程烂熟于心了,直接来手撕代码。首先我们需要一个键值对的类,它的用处我们后面会讲:
代码语言:javascript代码运行次数:0运行复制
public class Pair { public K key; public V value; public Pair(K key, V value) { this.key = key; this.value = value; }}public class IntPair extends Pair{ public IntPair(Integer key, Integer value) { super(key, value); }}接下来我们需要链表的节点:
代码语言:javascript代码运行次数:0运行复制
public class Node { public T data; public Node next; public Node prev; public Node(T dataVal) { this.data = dataVal; this.next = null; this.prev = null; }}有了节点之后我们就可以着手实现我们的链表了:
代码语言:javascript代码运行次数:0运行复制
public class LinkedList { private Node head; private Node tail; private int length; public LinkedList() { this.head = null; this.tail = null; } public int size() { return this.length; } public void insertAtHead(T data) { Node newNode = new Node(data); addFirst(newNode); } public void insertAtTail(T data) { Node newNode = new Node(data); addLast(newNode); } public void addFirst(Node newNode) { if (this.head == null) { this.head = newNode; this.tail = newNode; } else { newNode.next = this.head; this.head.prev = newNode; this.head = newNode; } this.length++; } public void addLast(Node newNode) { if (this.head == null) { this.head = newNode; this.tail = newNode; } else { this.tail.next = newNode; newNode.prev = this.tail; this.tail = newNode; } this.length++; } public void remove(T data) { Node tmp = this.head; while (tmp != null) { if (tmp.data == data) { this.remove(tmp); return; } tmp = tmp.next; } } public void remove(Node node) { if (node == null) return; if (node.prev != null) node.prev.next = node.next; if (node.next != null) node.next.prev = node.prev; if (node == this.head) this.head = this.head.next; if (node == this.tail) { this.tail = this.tail.prev; if (this.tail != null) this.tail.next = null; } this.length--; node = null; } public void removeFirst() { this.remove(this.head); } public void removeLast() { this.remove(this.tail); } public Node getFirst() { return this.head; } public Node getLast() { return this.tail; }}public class IntPairList extends LinkedList {};这里面我们增加了一些工具方法,方便插入删除节点。之后我们可以实现我们的缓存类了:
代码语言:javascript代码运行次数:0运行复制
import java.util.HashMap;public class LRUCache { private final int capacity; // 哈希表用来保存访问的key以及key对应的在链表上的节点 HashMap<Integer, Node> cacheMap = new HashMap(); // 双链表,用来维护元素被访问的顺序 IntPairList cacheList = new IntPairList(); public LRUCache(int size) { this.capacity = size; } int get(int key) { // 判断要访问的key是否已在缓存中 if (!cacheMap.containsKey(key)) { // 不存在返回-1 return -1; } else { Node foundIter = cacheMap.get(key); // 把当前节点移动到head的位置 cacheList.remove(foundIter); cacheList.addFirst(foundIter); return foundIter.data.value; } } void set(int key, int value) { // 判断要访问的key是否已在缓存中 if (cacheMap.containsKey(key)) { Node foundIter = cacheMap.get(key); // 把当前节点移动到缓存head的位置 cacheList.remove(foundIter); cacheList.addFirst(foundIter); // 更新节点的值 foundIter.data.value = value; return; } // 如果key不在缓存中且缓存满了 if (cacheMap.size() == capacity) { // 拿到LRU元素也就是缓存中tail的key int keyTmp = cacheList.getLast().data.key; // 这也是为什么我们要在缓存中保存key-value,只有value的话我们不知道它对应哈希表中的哪一个 cacheMap.remove(keyTmp); // 移除LRU元素 cacheList.removeLast(); } // 在缓存head处插入新元素 cacheList.insertAtHead(new IntPair(key, value)); // 更新哈希表,记录目前已有的缓存 if (cacheMap.containsKey(key)) { cacheMap.replace(key, cacheList.getFirst()); } else { cacheMap.put(key, cacheList.getFirst()); } } // 打印缓存当前的状态 public void printCacheState() { System.out.print("Cache current size: " + cacheList.size() + ", "); System.out.print("Cache contents: {"); Node iter = cacheList.getFirst(); while (iter != null) { IntPair pair = iter.data; System.out.print("{" + pair.key + ": " + pair.value + "}"); iter = iter.next; if (iter != null) { System.out.print(", "); } } System.out.print("}"); System.out.print( "n----------------------------------------------------------------------------------------------------n"); }}这边我们可以明白为啥要创建键值对的类了,拿到一个节点时,我们可以快速从哈希表中移除元素,否则我们得遍历整个哈希表来匹配了。此外除了必须要的构造函数跟get、set函数,我还增加了一个printCacheState函数用于打印当前缓存的状态,方便后面做测试。
最后就是我们的test case啦:
代码语言:javascript代码运行次数:0运行复制
public class Test { public static void main(String[] args) { // 创建一个大小为2的缓存 int cacheCapacity = 2; LRUCache cache = new LRUCache(cacheCapacity); System.out.println("Initial state of cache"); System.out.println("Cache capacity: " + cacheCapacity); cache.printCacheState(); int[] keys = {10, 10, 15, 20, 15, 25, 5}; String[] values = {"20", "get", "25", "40", "get", "85", "5"}; for (int i = 0; i < keys.length; i++) { if (values[i].equals("get")) { System.out.println("Getting by Key: " + keys[i]); System.out.println("Cached value returned: " + (cache.get(keys[i]))); } else { System.out.println("Setting cache: Key: " + keys[i] + ", Value: " + values[i]); cache.set(keys[i], Integer.parseInt(values[i])); } cache.printCacheState(); } }}每做一次操作我们都将当前缓存的状态打印出来来验证我们思路跟实现的准确与否。
写在最后
这次我们讨论的东西有点不一样,通过已有的数据结构去实现另一个数据结构。通过结合哈希表跟双链表,最后空间复杂度是O(n),而set跟get函数的时间复杂度都是O(1)。所有的思路跟细节也跟大家详细地说清楚了,在这之后,相信大家面对实现LRU缓存这种问题都能游刃有余,不慌不忙~
关于哈希表神奇的O(1)读取速度,我们后面可以单独拉出来讲讲吗,这都是后话啦~ Happy Coding~
以上就是关于优雅地实现LRU缓存这件事,一次性说清楚的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/461727.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















