
该项目基于树莓派4B与Paddle-Lite实现手写数字识别,为Paddle-Lite基础教程。流程涵盖用Paddle Fluid动态图训练DNN/CNN模型,保存静态图后通过opt工具转化为Paddle-Lite模型,再以C++ API在树莓派部署,展现从模型训练到端侧部署的全流程,助力开发者熟悉相关开发。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于树莓派4B与Paddle-Lite实现的手写数字识别
本项目属于Paddle-Lite基础教程,通过本项目可以让开发者熟悉从Paddle Fluid训练模型到Paddle-Lite端侧部署的全部流程。
本项目重点倾向于armLinux平台Paddle-Lite入门开发。通过Paddle Fluid动态图机制-DyGraph训练模型,使用TracedLayer.trace接口保存为静态图模型,使用opt工具进行模型转化。
通过HelloWorld级项目:手写数字识别。了解手写数字识别的过的同时,也熟悉了Paddle Fluid动态图API。了解流程以后才能使用Paddle-Lite C++ API来开发自己的Paddle-Lite项目。
树莓派4B运行手写数字识别:
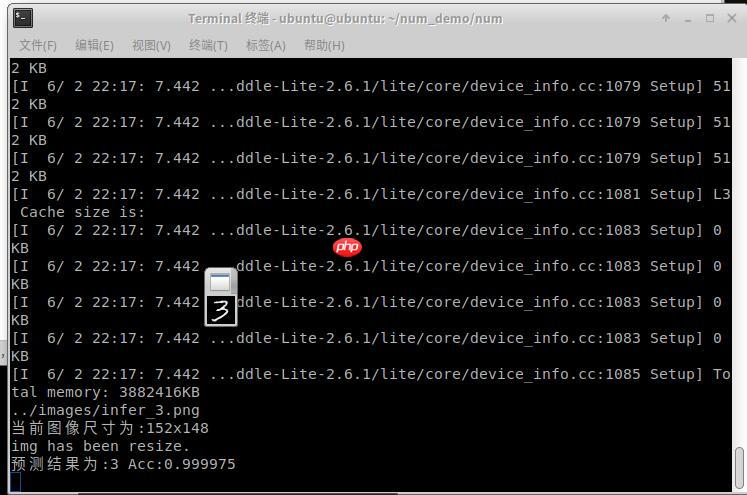
0.文档说明
本项目提供Paddle-Lite v2.6.1源码编译的opt工具。具体opt编译过程在本项目2.1节。
work文件夹下有Paddle-Lite v2.6.1源码包,以及训练时的模型备份。
data文件夹下的数据集data/data1910/infer_3.png和data/data38289/0~9.jpg。
infer_3.png虽然是黑底白字的,但是也是个3通道的图片。
0~9.jpg是从mnist测试集中导出的28×28的单通道的灰度图
下列代码显示图片通道数。
In [ ]
import matplotlib.pyplot as pltfrom PIL import Imageinfer_3='data/data1910/infer_3.png'#数字#显示图片通道数image3=Image.open(infer_3)print("infer_3.png通道数为:"+str(len(image3.split())))jpg_3='data/data38289/3.jpg'image3=Image.open(jpg_3)print("3.jpg通道数为:"+str(len(image3.split())))
infer_3.png通道数为:33.jpg通道数为:1
一、动态图机制-DyGraph
动态图机制不同于以往的静态图,无需构建整个图就可以立即执行结果。这使得我们在编写代码以及调试代码时更加直观、方便,我们无需编写静态图框架,这省去了我们大量的时间成本。利用动态图机制,我们能够更加快捷、直观地构建我们的深度学习网络。
这里使用动态图机制训练手写数字识别的模型。
In [ ]
# 清除之前训练及转化的模型# !rm num.nb# !rm mnist.pdparams# !rm -rf saved_infer_model/
1.1获取训练数据
(1)数据集介绍
MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字。

(2)train_reader和test_reader
paddle.dataset.mnist.train()和test()分别用于获取mnist训练集和测试集
paddle.batch()表示每BATCH_SIZE组成一个batch
(3)PaddlePaddle接口提供的数据已经经过了归一化、居中等处理。
In [ ]
import paddleimport paddle.fluid as fluidimport numpy as npBATCH_SIZE=128#获取训练数据train_set=paddle.dataset.mnist.train()train_reader=paddle.batch(train_set,batch_size=BATCH_SIZE)#获取测试数据test_set=paddle.dataset.mnist.test()test_reader=paddle.batch(test_set,batch_size=BATCH_SIZE)
1.2模型设计
这里设计了简单的DNN与CNN网络。

DNN网络使用的是多层感知器,一共有三层,两个大小为100的隐层和一个大小为10的输出层,因为MNIST数据集是手写0到9的灰度图像,类别有10个,所以最后的输出大小是10。最后输出层的激活函数是Softmax,所以最后的输出层相当于一个分类器。加上一个输入层的话,多层感知器的结构是:输入层–>>隐层–>>隐层–>>输出层。
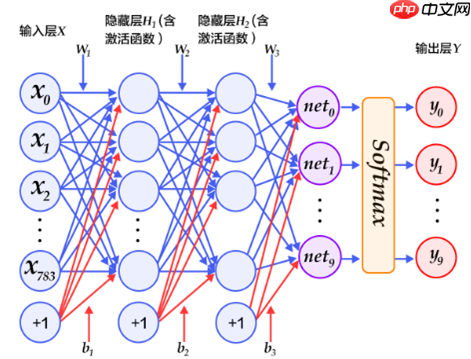
In [ ]
import paddle.fluid as fluidfrom paddle.fluid.dygraph import Linear#定义DNN网络class MyDNN(fluid.dygraph.Layer): def __init__(self): super(MyDNN,self).__init__() self.hidden1 = Linear(28*28,100, act='relu') self.hidden2 = Linear(100,100, act='relu') self.hidden3 = Linear(100,10, act='softmax') def forward(self,x): #[bs, 1, 28, 28] x = fluid.layers.reshape(x, [-1, x.shape[1]*x.shape[2]*x.shape[3]]) #x = fluid.layers.reshape(x, [x.shape[0], -1]) #此方式会在Lite预测中报维度不匹配 #[bs, 784] x = self.hidden1(x) #[bs, 100] x = self.hidden2(x) #[bs, 100] y = self.hidden3(x) #[bs, 10] return y
这里设计的CNN网络也比较简单,输入层–>>卷积–>>池化–>>卷积–>>池化–>>全连接–>>输出
项目使用DNN进行训练,如果想使用CNN网络,将model=MyDNN()改为model=MyCNN()即可。
In [ ]
import paddle.fluid as fluidfrom paddle.fluid.dygraph import Pool2D,Conv2Dfrom paddle.fluid.dygraph import Linear#定义CNN网络class MyCNN(fluid.dygraph.Layer): def __init__(self): super(MyCNN,self).__init__() self.hidden1_1 = Conv2D(num_filters=32, filter_size=3, num_channels=1) self.hidden1_2 = Pool2D(pool_size=2, pool_stride=1, pool_type='max') self.hidden2_1 = Conv2D(num_filters=64, filter_size=3,num_channels=32) self.hidden2_2 = Pool2D(pool_size=2, pool_stride=1, pool_type='max') self.hidden3 = Linear(30976,10, act='softmax') def forward(self,x): #[bs, 1, 28, 28] x = self.hidden1_1(x) #[bs, 32, 26, 26] x = self.hidden1_2(x) #[bs, 32, 25, 25] x = self.hidden2_1(x) #[bs, 64, 23, 23] x = self.hidden2_2(x) #[bs, 64, 22, 22] x = fluid.layers.reshape(x, [-1, x.shape[1]*x.shape[2]*x.shape[3]]) #[bs, 30976] y = self.hidden3(x) #[bs, 10] return y
1.3模型训练与保存
迭代次数设置为1,优化器选取Adam,学习率为0.001
在训练时会检测是否有已经训练过的模型,如果有则加载模型对其继续进行训练。
训练时只保存测试集Accuracy值最高时的模型。
In [ ]
from paddle.fluid.dygraph import Linear, to_variable, TracedLayerfrom pathlib import Pathmy_file = Path("mnist.pdparams")Batch=0best_acc=0Batchs=[]all_train_accs=[]all_train_loss=[]with fluid.dygraph.guard(): model=MyDNN()#模型实例化 if my_file.exists(): model_dict,_=fluid.load_dygraph('mnist') model.load_dict(model_dict)#加载模型参数 print("已经加载模型!") #模型评估 with fluid.dygraph.guard(): accs = [] model_dict, _ = fluid.load_dygraph('mnist') model = MyDNN() model.load_dict(model_dict) #加载模型参数 model.eval() #训练模式 for batch_id,data in enumerate(test_reader()):#测试集 images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32) labels=np.array([x[1] for x in data]).astype('int64').reshape(-1,1) image=fluid.dygraph.to_variable(images) label=fluid.dygraph.to_variable(labels) predict=model(image) acc=fluid.layers.accuracy(predict,label) accs.append(acc.numpy()[0]) avg_acc = np.mean(accs) print("当前模型Accuracy:"+ str(avg_acc)) best_acc=avg_acc model.train()#训练模式 opt=fluid.optimizer.AdamOptimizer(learning_rate=0.001, parameter_list=model.parameters())#优化器选用Adam,学习率为0.001. epochs_num=1 #迭代次数 for pass_num in range(epochs_num): for batch_id,data in enumerate(train_reader()):#训练集 # 输入的原始图像数据,大小为1*28*28 images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32) # 标签,名称为label,对应输入图片的类别标签 labels=np.array([x[1] for x in data]).astype('int64').reshape(-1,1) image=fluid.dygraph.to_variable(images) label=fluid.dygraph.to_variable(labels) predict=model(image)#预测 #使用交叉熵损失函数,描述真实样本标签和预测概率之间的差值 loss=fluid.layers.cross_entropy(predict,label) # 使用类交叉熵函数计算predict和label之间的损失函数 avg_loss=fluid.layers.mean(loss)#获取loss值 # 计算分类准确率 acc=fluid.layers.accuracy(predict,label)#计算精度 Batch = Batch + BATCH_SIZE Batchs.append(Batch) all_train_loss.append(avg_loss.numpy()[0]) all_train_accs.append(acc.numpy()[0]) if batch_id!=0 and batch_id%100==0: print("pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy())) avg_loss.backward() opt.minimize(avg_loss) model.clear_gradients() accs = [] for batch_id,data in enumerate(test_reader()):#测试集 images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32) labels=np.array([x[1] for x in data]).astype('int64').reshape(-1,1) image=fluid.dygraph.to_variable(images) label=fluid.dygraph.to_variable(labels) predict=model(image) loss=fluid.layers.cross_entropy(predict,label) avg_loss=fluid.layers.mean(loss) acc=fluid.layers.accuracy(predict,label) accs.append(acc.numpy()[0]) avg_acc = np.mean(accs) if batch_id!=0 and batch_id%10==0: print("pass:{},batch_id:{},test_loss:{},test_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy())) print("Accuracy:" + str(avg_acc)) if avg_acc > best_acc: best_acc = avg_acc # 保存动态图模型 fluid.save_dygraph(model.state_dict(),'mnist') # 保存静态图模型 out_dygraph, static_layer = TracedLayer.trace(model, inputs=[image]) static_layer.save_inference_model(dirname='./saved_infer_model') # 将静态图模型保存为预测模型 print("nn Saved nn")
已经加载模型!当前模型Accuracy:0.9596519pass:0,batch_id:100,train_loss:[0.0638935],train_acc:[0.984375]pass:0,batch_id:200,train_loss:[0.07048865],train_acc:[0.984375]pass:0,batch_id:300,train_loss:[0.08371429],train_acc:[0.984375]pass:0,batch_id:400,train_loss:[0.15308227],train_acc:[0.9453125]pass:0,batch_id:10,test_loss:[0.1633934],test_acc:[0.953125]pass:0,batch_id:20,test_loss:[0.26318473],test_acc:[0.9453125]pass:0,batch_id:30,test_loss:[0.1494982],test_acc:[0.953125]pass:0,batch_id:40,test_loss:[0.08685159],test_acc:[0.9765625]pass:0,batch_id:50,test_loss:[0.07866478],test_acc:[0.9609375]pass:0,batch_id:60,test_loss:[0.01389446],test_acc:[0.9921875]pass:0,batch_id:70,test_loss:[0.11957482],test_acc:[0.9609375]Accuracy:0.96261865 Saved
In [ ]
import matplotlib.pyplot as pltdef draw_train_acc(Batchs, train_accs): title="training accs" plt.title(title, fontsize=24) plt.xlabel("batch", fontsize=14) plt.ylabel("acc", fontsize=14) plt.plot(Batchs, train_accs, color='green', label='training accs') plt.legend() plt.grid() plt.show()def draw_train_loss(Batchs, train_loss): title="training loss" plt.title(title, fontsize=24) plt.xlabel("batch", fontsize=14) plt.ylabel("loss", fontsize=14) plt.plot(Batchs, train_loss, color='red', label='training loss') plt.legend() plt.grid() plt.show()draw_train_acc(Batchs,all_train_accs)draw_train_loss(Batchs,all_train_loss)
1.4模型预估与预测
预估模型并对待预测的图片进行预测
In [ ]
#模型评估with fluid.dygraph.guard(): accs = [] model_dict, _ = fluid.load_dygraph('mnist') model = MyDNN() model.load_dict(model_dict) #加载模型参数 model.eval() #训练模式 for batch_id,data in enumerate(test_reader()):#测试集 images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32) labels=np.array([x[1] for x in data]).astype('int64').reshape(-1,1) image=fluid.dygraph.to_variable(images) label=fluid.dygraph.to_variable(labels) predict=model(image) acc=fluid.layers.accuracy(predict,label) accs.append(acc.numpy()[0]) avg_acc = np.mean(accs) print(avg_acc)
0.96261865
In [ ]
import paddle.fluid as fluidfrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as npimport osimport timedef load_image(file): img=Image.open(file).convert('L')#以灰度图的方式读取待测图片 img=img.resize((28,28),Image.ANTIALIAS)#调整大小 img=np.array(img).reshape(1,1,28,28).astype('float32') img=img/255*2.0-1.0#归一化 print(img.shape) return imgfor i in range(10): infer_path='data/data38289/'+ str(i) + '.jpg'#数字 print(infer_path) #显示待预测的图片 image=Image.open(infer_path).convert('L') image=image.resize((100,100),Image.ANTIALIAS) plt.imshow(image) plt.show() #构建预测动态图过程 with fluid.dygraph.guard(): model=MyDNN()#模型实例化 model_dict,_=fluid.load_dygraph('mnist') model.load_dict(model_dict)#加载模型参数 model.eval()#评估模式 img=load_image(infer_path) img=fluid.dygraph.to_variable(img)#将np数组转换为dygraph动态图的variable result=model(img) print('预测的结果是:{}'.format(np.argmax(result.numpy()))) time.sleep(1.5)
data/data38289/0.jpg(1, 1, 28, 28)预测的结果是:0
data/data38289/1.jpg(1, 1, 28, 28)预测的结果是:1
data/data38289/2.jpg(1, 1, 28, 28)预测的结果是:2
data/data38289/3.jpg(1, 1, 28, 28)预测的结果是:3
data/data38289/4.jpg(1, 1, 28, 28)预测的结果是:4
data/data38289/5.jpg(1, 1, 28, 28)预测的结果是:5
data/data38289/6.jpg(1, 1, 28, 28)预测的结果是:6
data/data38289/7.jpg(1, 1, 28, 28)预测的结果是:7
data/data38289/8.jpg(1, 1, 28, 28)预测的结果是:8
data/data38289/9.jpg(1, 1, 28, 28)预测的结果是:9
二 、Paddle Fluid 到 Paddle-Lite 部署
2.1 Paddle-Lite模型转化
首先将saved_infer_model/下的静态图模型通过opt工具进行转化。
如果想自己动手编译opt工具,将下列代码取消注释运行即可。
In [32]
####编译Paddle-Lite V2.6.1 opt工具##### !unzip work/Paddle-Lite-2.6.1.zip# %cd Paddle-Lite-2.6.1# !rm -rf third-party # !./lite/tools/build.sh build_optimize_tool# !cp /home/aistudio/Paddle-Lite-2.6.1/build.opt/lite/api/opt ~# %cd ~
In [ ]
!chmod +x opt!./opt --model_dir=saved_infer_model --optimize_out_type=naive_buffer --optimize_out=num
[I 6/ 2 16:38:43.986 ...io/Paddle-Lite-2.6.1/lite/api/cxx_api.cc:251 Build] Load model from file.[I 6/ 2 16:38:43.988 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_quant_dequant_fuse_pass[I 6/ 2 16:38:43.988 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_quant_dequant_fuse_pass[I 6/ 2 16:38:43.988 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: weight_quantization_preprocess_pass[I 6/ 2 16:38:43.988 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: weight_quantization_preprocess_pass[I 6/ 2 16:38:43.988 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_conv_elementwise_fuse_pass[I 6/ 2 16:38:43.989 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_conv_elementwise_fuse_pass[I 6/ 2 16:38:43.989 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_conv_bn_fuse_pass[I 6/ 2 16:38:43.989 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_conv_bn_fuse_pass[I 6/ 2 16:38:43.989 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_conv_elementwise_fuse_pass[I 6/ 2 16:38:43.989 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_conv_elementwise_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_conv_activation_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_conv_activation_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_var_conv_2d_activation_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip lite_var_conv_2d_activation_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_fc_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_fc_fuse_pass[I 6/ 2 16:38:43.990 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_shuffle_channel_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_shuffle_channel_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_transpose_softmax_transpose_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_transpose_softmax_transpose_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_interpolate_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: lite_interpolate_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: identity_scale_eliminate_pass[I 6/ 2 16:38:43.991 ...e-2.6.1/lite/core/mir/pattern_matcher.cc:108 operator()] detected 1 subgraph[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: identity_scale_eliminate_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: elementwise_mul_constant_eliminate_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: elementwise_mul_constant_eliminate_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: lite_sequence_pool_concat_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip lite_sequence_pool_concat_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: __xpu__resnet_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip __xpu__resnet_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: __xpu__multi_encoder_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip __xpu__multi_encoder_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: __xpu__embedding_with_eltwise_add_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip __xpu__embedding_with_eltwise_add_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: __xpu__fc_fuse_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip __xpu__fc_fuse_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: identity_dropout_eliminate_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip identity_dropout_eliminate_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: quantized_op_attributes_inference_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip quantized_op_attributes_inference_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: npu_subgraph_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip npu_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: xpu_subgraph_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip xpu_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: bm_subgraph_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip bm_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: apu_subgraph_pass[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip apu_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43.991 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: rknpu_subgraph_pass[I 6/ 2 16:38:43.992 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip rknpu_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43.992 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: static_kernel_pick_pass[I 6/ 2 16:38:43.992 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: static_kernel_pick_pass[I 6/ 2 16:38:43.992 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: variable_place_inference_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: variable_place_inference_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: type_target_cast_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: type_target_cast_pass[I 6/ 2 16:38:43.994 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: variable_place_inference_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: variable_place_inference_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: io_copy_kernel_pick_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: io_copy_kernel_pick_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.995 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: variable_place_inference_pass[I 6/ 2 16:38:43.996 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: variable_place_inference_pass[I 6/ 2 16:38:43.996 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.996 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.996 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: type_precision_cast_pass[I 6/ 2 16:38:43.997 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: type_precision_cast_pass[I 6/ 2 16:38:43.997 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: variable_place_inference_pass[I 6/ 2 16:38:43.998 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: variable_place_inference_pass[I 6/ 2 16:38:43.998 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.998 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.998 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: type_layout_cast_pass[I 6/ 2 16:38:43.999 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: type_layout_cast_pass[I 6/ 2 16:38:43.999 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43.999 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43.999 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: variable_place_inference_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: variable_place_inference_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: mlu_subgraph_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip mlu_subgraph_pass because the target or kernel does not match.[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: runtime_context_assign_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: runtime_context_assign_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: argument_type_display_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: argument_type_display_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: mlu_postprocess_pass[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:215 RunPasses] - Skip mlu_postprocess_pass because the target or kernel does not match.[I 6/ 2 16:38:43. 0 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:202 RunPasses] == Running pass: memory_optimize_pass[I 6/ 2 16:38:43. 0 ....1/lite/core/mir/memory_optimize_pass.cc:160 CollectLifeCycleByDevice] There are 1 types device var.[I 6/ 2 16:38:43. 0 ....1/lite/core/mir/memory_optimize_pass.cc:209 MakeReusePlan] cluster: t_9[I 6/ 2 16:38:43. 0 ....1/lite/core/mir/memory_optimize_pass.cc:209 MakeReusePlan] cluster: t_6[I 6/ 2 16:38:44. 1 .../Paddle-Lite-2.6.1/lite/core/optimizer.h:219 RunPasses] == Finished running: memory_optimize_pass[I 6/ 2 16:38:44. 2 ....1/lite/core/mir/generate_program_pass.h:37 GenProgram] insts.size 12[I 6/ 2 16:38:44. 4 ...-2.6.1/lite/model_parser/model_parser.cc:588 SaveModelNaive] Save naive buffer model in 'num.nb' successfully
2.2 Paddle-Lite v2.6.1预测库编译
在进行Paddle-Lite编程之前,先需要编译Paddle-Lite预测库。
或者直接使用官方编译好的预测库 https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.6.1/inference_lite_lib.armlinux.armv8.tar.gz
得到了num.nb模型以后,我们就可以开始Lite的编程了。
下面介绍Paddle-Lite预测库编译方法
编程环境为armLinux ARMv8
首先我们需要编译Paddle-Lite v2.6.1预测库,由于目前AI Studio的Cmake版本是3.5,交叉编译Paddle-Lite armLinux ARMv8预测库需要3.10版本以上的Cmake。
因为直接从GitHub下载速度实在太慢,所以项目提供work/Paddle-Lite-2.6.1.zip的源码,方便用户使用。
编译预测库可以在x86 Linux环境下进行交叉编译,或者直接在树莓派4B上进行本地编译。
交叉编译
编译环境要求
gcc、g++、git、make、wget、python、scp cmake(建议使用3.10或以上版本) 具体步骤 安装软件部分以 Ubuntu 为例,其他 Linux 发行版类似。
#1. Install basic software
apt updateapt-get install -y --no-install-recommends gcc g++ git make wget python unzip
#2. Install arm gcc toolchains
apt-get install -y --no-install-recommends g++-arm-linux-gnueabi gcc-arm-linux-gnueabi g++-arm-linux-gnueabihf gcc-arm-linux-gnueabihf gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
#3. Install cmake 3.10 or above
wget -c https://mms-res.cdn.bcebos.com/cmake-3.10.3-Linux-x86_64.tar.gz && tar xzf cmake-3.10.3-Linux-x86_64.tar.gz && mv cmake-3.10.3-Linux-x86_64 /opt/cmake-3.10 && ln -s /opt/cmake-3.10/bin/cmake /usr/bin/cmake && ln -s /opt/cmake-3.10/bin/ccmake /usr/bin/ccmake
本地编译(直接在RK3399或树莓派上编译)
编译环境要求
gcc、g++、git、make、wget、python、pip、python-dev、patchelf cmake(建议使用3.10或以上版本) 具体步骤 安装软件部分以 Ubuntu 为例,其他 Linux 发行版本类似。
#1. Install basic software
apt updateapt-get install -y --no-install-recomends gcc g++ make wget python unzip patchelf python-dev
#2. install cmake 3.10 or above
wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gztar -zxvf cmake-3.10.3.tar.gzcd cmake-3.10.3./configuremakesudo make install
环境搭建好以后,不论是交叉编译还是本地编译, 只需cd Paddle-Lite-2.6.1执行 ./lite/tools/build_linux.sh
即可开始预测库编译,最后的编译生成结果在Paddle-Lite-2.6.1/build.lite.linux.armv8.gcc/inference_lite_lib.armlinux.armv8下
2.3 Paddle-Lite 手写数字识别项目详解
准备好了num.nb模型与Paddle-Lite预测库。万事俱备,现在可以开始我们的项目了!
编程使用语言为C++,这里是Paddle-Lite官方C++的API
项目目录风格使用Paddle-Lite官方Demo样式。
首先创建num_demo文件夹,在文件夹内新建两个文件夹num与Paddle-Lite。分别存放工程源码以及预测库。
Paddle-Lite文件夹下有include和libs,include用于存放Paddle-Lite头文件;libs下又分别有armv7hf与armv8,对应存放相应的库文件。
在num文件夹下,首先创建文件夹models,把num.nb模型存入其中;
创建文件夹images,把预测图片存入其中。
创建源码文件num.cc (.cc是在Linux环境下的C++文件,Win下为.cpp)
然后创建CMakeLists.txt
在CMakeLists.txt下,指定了Paddle-Lite预测库的路径与使用的架构armv8,以及OpenCV库的位置,源码文件num.cc。
其内容如下:
cmake_minimum_required(VERSION 3.10)set(CMAKE_SYSTEM_NAME Linux)set(TARGET_ARCH_ABI "armv8")set(PADDLE_LITE_DIR "../Paddle-Lite")if(TARGET_ARCH_ABI STREQUAL "armv8") set(CMAKE_SYSTEM_PROCESSOR aarch64) set(CMAKE_C_COMPILER "aarch64-linux-gnu-gcc") set(CMAKE_CXX_COMPILER "aarch64-linux-gnu-g++")elseif(TARGET_ARCH_ABI STREQUAL "armv7hf") set(CMAKE_SYSTEM_PROCESSOR arm) set(CMAKE_C_COMPILER "arm-linux-gnueabihf-gcc") set(CMAKE_CXX_COMPILER "arm-linux-gnueabihf-g++")else() message(FATAL_ERROR "Unknown arch abi ${TARGET_ARCH_ABI}, only support armv8 and armv7hf.") return()endif()project(num)message(STATUS "TARGET ARCH ABI: ${TARGET_ARCH_ABI}")message(STATUS "PADDLE LITE DIR: ${PADDLE_LITE_DIR}")include_directories(${PADDLE_LITE_DIR}/include)link_directories(${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI})set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")if(TARGET_ARCH_ABI STREQUAL "armv8") set(CMAKE_CXX_FLAGS "-march=armv8-a ${CMAKE_CXX_FLAGS}") set(CMAKE_C_FLAGS "-march=armv8-a ${CMAKE_C_FLAGS}")elseif(TARGET_ARCH_ABI STREQUAL "armv7hf") set(CMAKE_CXX_FLAGS "-march=armv7-a -mfloat-abi=hard -mfpu=neon-vfpv4 ${CMAKE_CXX_FLAGS}") set(CMAKE_C_FLAGS "-march=armv7-a -mfloat-abi=hard -mfpu=neon-vfpv4 ${CMAKE_C_FLAGS}" )endif()find_package(OpenMP REQUIRED)if(OpenMP_FOUND OR OpenMP_CXX_FOUND) set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}") set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}") message(STATUS "Found OpenMP ${OpenMP_VERSION} ${OpenMP_CXX_VERSION}") message(STATUS "OpenMP C flags: ${OpenMP_C_FLAGS}") message(STATUS "OpenMP CXX flags: ${OpenMP_CXX_FLAGS}") message(STATUS "OpenMP OpenMP_CXX_LIB_NAMES: ${OpenMP_CXX_LIB_NAMES}") message(STATUS "OpenMP OpenMP_CXX_LIBRARIES: ${OpenMP_CXX_LIBRARIES}")else() message(FATAL_ERROR "Could not found OpenMP!") return()endif()find_package(OpenCV REQUIRED)if(OpenCV_FOUND OR OpenCV_CXX_FOUND) include_directories(${OpenCV_INCLUDE_DIRS}) message(STATUS "OpenCV library status:") message(STATUS " version: ${OpenCV_VERSION}") message(STATUS " libraries: ${OpenCV_LIBS}") message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")else() message(FATAL_ERROR "Could not found OpenCV!") return()endif()add_executable(num num.cc)target_link_libraries(num paddle_light_api_shared ${OpenCV_LIBS})
准备完成后,开始编写num.cc代码。
首先导入头文件,将OpenCV与Paddle-Lite以及其他需要的头文件导入。
#include #include #include #include #include "opencv2/core.hpp"#include "opencv2/imgcodecs.hpp"#include "opencv2/imgproc.hpp"#include "paddle_api.h" // NOLINT
使用Paddle-Lite命名空间,设定均值、标准化值。如果是三通道,则需设置三个INPUT_MEAN和INPUT_STD
using namespace paddle::lite_api; // NOLINTconst std::vector INPUT_MEAN = {0.f};const std::vector INPUT_STD = {1.f};
函数ShapeProduction,用于获得output tensor size
int64_t ShapeProduction(const shape_t& shape) { int64_t res = 1; for (auto i : shape) res *= i; return res;}
函数 RunModel(photo,predictor)
参数
photo(cv::Mat &)-传入待识别图像的地址。predictor(std::shared_ptr &)-传入predictor预测器地址。
void RunModel(cv::Mat &photo,std::shared_ptr &predictor)
RunModel函数详解:
预处理
//Pre_process cv::cvtColor(photo, photo, CV_BGR2GRAY);//三通道 -> 灰度 if(photo.cols != 28 || photo.rows != 28) { std::cout << "当前图像尺寸为:" << photo.cols << "x" << photo.rows << std::endl; cv::resize(photo, photo, cv::Size(28, 28), 0.f, 0.f); std::cout << "img has been resize." << std::endl; } photo.convertTo(photo, CV_32FC1, 1.f / 255.f * 2.f , -1.f);//归一化// std::cout << photo << std::endl;//查看形状// cv::imshow("num", photo);// cv::waitKey(0);
在Paddle-Lite编程中,模型的输入要与在Paddle Fluid中一致。模型的输入为{batchsize,channel=1,height=28,weight=28},photo是cv::Mat类,cv::Mat类默认加载图像是BGR形式,即使输入的图像是单通道的灰度图,cv::Mat会自动对差值两个通道再组成BGR三通道形式,如下如:

所以需要使用cv::cvtColor对输入图片进行灰度处理。并且输入图像的高与宽都是28,所以判断如果输入图像不是28×28则进行reshape成28×28。
下图为cv::cvtColor(photo, photo, CV_BGR2GRAY);后的图像与在Paddle Fluid中图像值: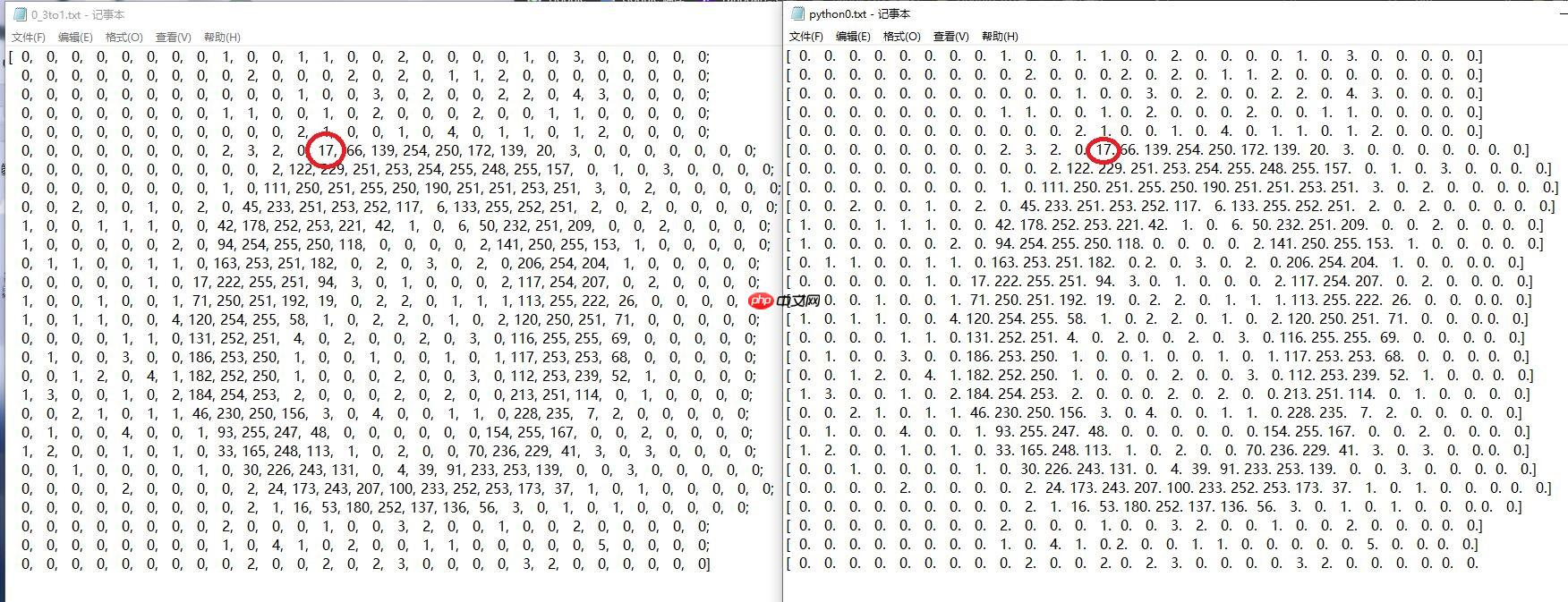
使用opencv 颜色空间转换函数convertTo方法进行归一化操作,
void convertTo( OutputArray m, int rtype, double alpha=1, double beta=0 ) const;
参数
m – 目标矩阵。如果m在运算前没有合适的尺寸或类型,将被重新分配。rtype – 目标矩阵的类型。因为目标矩阵的通道数与源矩阵一样,所以rtype也可以看做是目标矩阵的位深度。如果rtype为负值,目标矩阵和源矩阵将使用同样的类型。alpha – 尺度变换因子(可选)。beta – 附加到尺度变换后的值上的偏移量(可选)。
所以在photo.convertTo(photo, CV_32FC1, 1.f / 255.f * 2.f , -1.f);中: photo为输入图像,CV_32FC1为需要进行色彩空间转换的结果,32表示32位、F表示单精度float、C1表示单通道(如果是RGB彩色图像则改成C3)。由于手写数字识别的图像在Paddle Fluid中被归一化成:img=img/255*2.0-1.0。所以这里归一化的操作需要一致。
获取Input Tensor
// Get Input Tensor std::unique_ptr input_tensor(std::move(predictor->GetInput(0))); input_tensor->Resize({1, 1, 28, 28}); auto* input_data = input_tensor->mutable_data();
predictor在main函数中定义,作为参数传入RunModel函数,PaddlePredictor是Paddle-Lite的预测器,由CreatePaddlePredictor根据MobileConfig进行创建。用户可以根据PaddlePredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
创建unique_ptr智能指针input_tensor,使用Resize方法将其resize成{1, 1, 28, 28},与Paddle Fluid输入一致。
使用mutable_data方法,获取Tensor的底层数据的指针,根据传入的不同模型类型获取相应数据。用于设置Tensor数据。
准备好input_data后,就可以开始设置Tensor数据了。
向Tensor输入数据
// NHWC->NCHW const float *image_data = reinterpret_cast(photo.data); float32x4_t vmean0 = vdupq_n_f32(INPUT_MEAN[0]); float32x4_t vscale0 = vdupq_n_f32(1.0f / INPUT_STD[0]); float *input_data_c0 = input_data; int i = 0; for (; i < photo.cols*photo.rows ; i += 1) { float32x4x3_t vin3 = vld3q_f32(image_data); float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0); float32x4_t vs0 = vmulq_f32(vsub0, vscale0); vst1q_f32(input_data_c0, vs0); image_data += 1; input_data_c0 += 1; } for (; i < photo.cols*photo.rows ; i++) { *(input_data_c0++) = (*(image_data++) - INPUT_MEAN[0]) / INPUT_STD[0]; }
NHWC:[batch, in_height, in_width, in_channels]
NCHW:[batch, in_channels, in_height, in_width]
使用ARM NEON指令进行NHWC->NCHW操作,ARM NEON技术是适用于ARM Cortex-A系列处理器的一种128位SIMD(Single Instruction, Multiple Data,单指令、多数据)扩展结构。
执行预测
predictor->Run();
一切准备好以后,执行预测。
获取输出Tensor 并输出预测结果
// Get Output Tensorstd::unique_ptr output_tensor(std::move(predictor->GetOutput(0)));auto output_data = output_tensor->data();auto output_shape = output_tensor->shape();int64_t outputSize = ShapeProduction(output_shape);for(int i =0 ;i 0.5f ) std::cout << "预测结果为:" << i << " Acc:" << output_data[i] << std::endl;}
手写数字识别是10分类任务,output_shape=10。通过output_tensor->data()获取预测的结果,output_data内共有10个类别,从output_data[0]~output_data[9]分别代表预测为0~9的概率,设置阈值大于50%为预测正确。
至此RunModel函数结束。
main函数详解:
std::string num_model = argv[1];const int CPU_THREAD_NUM = 4;const paddle::lite_api::PowerMode CPU_POWER_MODE = paddle::lite_api::PowerMode::LITE_POWER_FULL;// DetectionMobileConfig config;config.set_threads(CPU_THREAD_NUM);config.set_power_mode(CPU_POWER_MODE);config.set_model_from_file(num_model);//v2.6 API// Create Predictor For Detction Modelstd::shared_ptr predictor = CreatePaddlePredictor(config);if (argc == 3){ std::string img_path = argv[2]; std::cout << argv[2] << std::endl; cv::Mat photo = imread(img_path, cv::IMREAD_COLOR); RunModel(photo,predictor); cv::imshow("num", photo); cv::waitKey(0);}else { exit(1);}return 0;
argv[1]保存num.nb模型路径,argv[2]保存待预测图片路径。
MobileConfig用来配置构建轻量级PaddlePredictor的配置信息,如NaiveBuffer格式的模型地址、模型的内存地址(从内存加载模型时使用)、能耗模式、工作线程数等等。
config.set_threads(CPU_THREAD_NUM);设置4线程,
config.set_power_mode(CPU_POWER_MODE);设置CPU能耗模式为LITE_POWER_FULL,
config.set_model_from_file(num_model);为Paddle-Lite v2.3以后加载.nb模型的接口
cv::Mat photo = imread(img_path, cv::IMREAD_COLOR);IMREAD_COLOR指定用彩色图像打开图片。
以上num.cc源码讲解完毕,现在创建编译脚本cmake.sh与运行脚本run.sh
cmake.sh
#!/bin/bash# configureTARGET_ARCH_ABI=armv8 # for RK3399, set to default arch abi#TARGET_ARCH_ABI=armv7hf # for Raspberry Pi 3BPADDLE_LITE_DIR=../Paddle-Lite# buildrm -rf buildmkdir buildcd buildcmake -DPADDLE_LITE_DIR=${PADDLE_LITE_DIR} -DTARGET_ARCH_ABI=${TARGET_ARCH_ABI} ..make
run.sh
#!/bin/bash# configureTARGET_ARCH_ABI=armv8 # for RK3399, set to default arch abi#TARGET_ARCH_ABI=armv7hf # for Raspberry Pi 3BPADDLE_LITE_DIR=../Paddle-Lite#runcd buildLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/0.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/1.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/2.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/3.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/4.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/5.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/6.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/7.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/8.jpgLD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI} ./num ../models/num.nb ../images/9.jpg
使用chmod +x赋予脚本可执行权限,然后运行sh cmake.sh && sh run.sh 即可完成编译及运行。
下次运行时直接sh run.sh无需再次编译耗时。
以上就是基于树莓派4B与Paddle-Lite实现的手写数字识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/46361.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























