本文基于DeepGlobe地表覆盖数据集,利用PaddleSeg的PP-LiteSeg、DeepLabV3P、ANN三种分割模型,在相同超参数下开展训练对比。数据集经格式转换、7:3划分训练与验证集后,通过准确率、mIoU等指标评估,结果显示DeepLabV3P模型效果最优,可辅助识别农业用地非法侵占。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【校园AI Day-AI workshop】卫星遥感图像切割多模型对比
1. 引言
1.1 项目简介
农业是国之根本,但侵占基本农田的案例时有发生,我国土地面积辽阔,对农业用地非法侵占行为的识别需要耗费大量的时间和人力物力。利用深度学习的语义分割,能够帮助政府管理人员识别和统计农业用地地块,大大减少人工工作量。
本文使用PaddleSeg套件中的三种分割模型(PP-LiteSeg, DeepLabV3P, ANN),针对DeepGlobe地表覆盖数据集。配置相同的超参数,对比三种模型训练结果。主要分为引言、环境安装、数据准备、模型训练、模型评估、结果对比以及附录等主要部分。
1.2 数据集介绍
本文使用的是DeepGlobe地表覆盖数据集,其包含具体内容如下所示。本文将train文件夹下的图像按7:3比例划分为训练集和验证集。其次,将标注图像的三通道转换为单通道(通道值从0开始),用0-6进行像素替换。
├── class_dict.csv├── metadata.csv├── test│ ├── 100877_sat.jpg│ ├── 103215_sat.jpg│ ├── ...├── train│ ├── 1008694_mask.png│ ├── 1000694_sat.jpg│ ├── ...├── valid│ ├── 105036_sat.jpg│ ├── 107780_sat.jpg│ ├── ...
数据集中某张images原图如下所示:
数据集中某张images对应的mask图像如下所示:
2. 环境安装
2.1 克隆PaddleSeg
PaddleSeg是基于飞桨PaddlePaddle开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。PaddleSeg具体介绍及使用说明请参考:飞桨高性能图像分割开发套件
In [3]
! git clone https://gitee.com/paddlepaddle/PaddleSeg
正克隆到 'PaddleSeg'...remote: Enumerating objects: 18055, done.remote: Counting objects: 100% (3018/3018), done.remote: Compressing objects: 100% (1534/1534), done.remote: Total 18055 (delta 1698), reused 2505 (delta 1435), pack-reused 15037接收对象中: 100% (18055/18055), 341.84 MiB | 12.92 MiB/s, 完成.处理 delta 中: 100% (11562/11562), 完成.检查连接... 完成。
In [4]
# 移动文件夹! mv PaddleSeg /home/aistudio/work
2.2 安装依赖库
In [ ]
%cd ~/work/PaddleSeg/!pip install -r requirements.txt%env PYTHONPATH=.:$PYTHONPATH%env CUDA_VISIBLE_DEVICES=0
3. 数据准备
3.1 解压数据集
In [6]
# 切换当前工作目录%cd ~
/home/aistudio
In [ ]
# 解压数据集! unzip /home/aistudio/data/data145161/DeepGlobeLandCoverClassificationDataset.zip
3.2 数据集格式转换
我们需要将自定义数据集转换成如下格式,进而使用PadleSeg套件进行训练。
DeepGlobe||--images| |--0.jpg| |--1.jpg| |--2.jpg| |--...||--labels| |--0.png| |--1.png| |--2.png| |--...||--train.txt||--val.txt||--test.txt
images文件夹存放原图(通道数为3),labels文件夹存放标注图像(通道数为1),train.txt、val.txt、test.txt指定训练集、验证集和测试集。本项目按照7:3的比例对images划分训练集与验证集,并分别输出到train.txt与val.txt文件中。
labels文件夹下标注图要求: 标注图像必须为单通道图像,像素值即为对应的类别,像素标注类别需要从0开始递增。 例如0,1,2,3表示有4种类别,标注类别最多为256类。其中可以指定特定的像素值用于表示该值的像素不参与训练和评估(默认为255)。
本项目所用数据集包含7种类别,如下表所示,因此我们需要将labels文件夹下的标注图像转换为单通道,对应像素点由0-6表示。
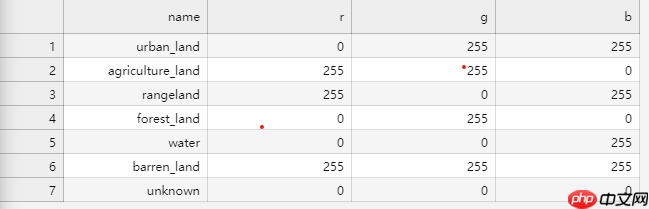
train.txt和val.txt的内容如下所示:
images/0.jpg labels/0.pngimages/1.jpg labels/1.pngimages/2.jpg labels/2.pngimages/3.jpg labels/3.png
推荐用户将数据集放置在PaddleSeg下的data文件夹下。
In [7]
%cd ~
/home/aistudio
3.2.1 查看图片编码类型
通过以下代码可以查看某张图片的shape,dtype等详细信息,从而知道是否满足传入数据要求。
In [ ]
%cd ~import numpy as npimport matplotlib.pyplot as pltimport cv2#jupyter 魔法指令,预加载,显示图片%matplotlib inline#读取图片img = cv2.imread('train/100694_mask.png',-1)#这里输入需要导入图片的位置print(img)#显示图片的数据print(img.shape)#查看图片的长宽及颜色print(img.dtype)
3.2.2 格式转化labels标注图像
按照PaddleSeg要求格式对labels图像进行转化 三通道转单通道 RGB标注彩图转换为物体的黑白mask图像代码如下所示
此处标注图像通道转换脚本参考了网上项目中的思路,也可以考虑使用其他转换思路,如使用numpy像素替换。
In [10]
# 读取标签import pandas as pdfrom PIL import Imageimport numpy as npimport cv2classpd = pd.read_csv('class_dict.csv')classpdd = dict() # 存储各标签数量def countlabel(img_path): label= Image.open(img_path) label = np.asarray(label) img= np.zeros((label.shape[0],label.shape[1]),np.uint8) label.shape for i in range(len(classpd)): row = classpd.loc[i,:] r1,g1,b1 = row.r,row.g,row.b red,green,blue = label[:,:,0], label[:,:,1], label[:,:,2] mask = (red==r1) & (green==g1) & (blue==b1) if(row['name'] not in d.keys()): d[row['name']]=0 d[row['name']]+=np.sum(mask)
In [11]
data_all = pd.read_csv('metadata.csv')data_all.head()
image_id split sat_image_path mask_path0 100694 train train/100694_sat.jpg train/100694_mask.png1 102122 train train/102122_sat.jpg train/102122_mask.png2 10233 train train/10233_sat.jpg train/10233_mask.png3 103665 train train/103665_sat.jpg train/103665_mask.png4 103730 train train/103730_sat.jpg train/103730_mask.png
In [12]
mask_ = pd.notna(data_all.mask_path)data_notna = data_all[mask_]ddata_mask_path = data_notna.mask_path
In [14]
from tqdm import trangefor i in trange(len(ddata_mask_path),desc='Progress ',leave=False): countlabel(ddata_mask_path[i])
In [15]
def imageconvlabel(img_path): label= Image.open(img_path) label = np.asarray(label) img= np.zeros((label.shape[0],label.shape[1]),np.uint8) for i in range(len(classpd)): row = classpd.loc[i,:] r1,g1,b1 = row.r,row.g,row.b red,green,blue = label[:,:,0], label[:,:,1], label[:,:,2] mask = (red==r1) & (green==g1) & (blue==b1) img[mask]=i cv2.imwrite(img_path+'new.png',img)
In [17]
# 转化成label标注图for i in trange(len(ddata_mask_path),desc='Progress ',leave=False): imageconvlabel(ddata_mask_path[i])
3.2.3 拆分文件夹
将train文件夹下的所有转换好的以new.png为后缀的label标注图片与image原图片分别输出到名为labels与images两个文件夹内。
In [18]
# 将图片文件移动到images文件夹中import osimport shutildef take_samefile(or_path, tar_path, tar_type): tar_path = tar_path if not os.path.exists(tar_path): os.makedirs(tar_path) path = or_path files = os.listdir(path) # 读取or_path文件列表 for file in files: file_type = str(file).split('.')[1] # 读取文件后缀 if file_type == tar_type: print("take{}from{}".format(file, files)) dir = path + '/' + file # 存储文件路径 deter = tar_path + '/' + str(file) shutil.copyfile(dir, deter)take_samefile(r"train", r"images", "jpg")
IOPub data rate exceeded.The Jupyter server will temporarily stop sending outputto the client in order to avoid crashing it.To change this limit, set the config variable`--ServerApp.iopub_data_rate_limit`.Current values:ServerApp.iopub_data_rate_limit=1000000.0 (bytes/sec)ServerApp.rate_limit_window=3.0 (secs)
In [19]
# 将标签文件移动到labels文件夹中import osimport shutildef take_samefile(or_path, tar_path, tar_type): tar_path = tar_path if not os.path.exists(tar_path): os.makedirs(tar_path) path = or_path files = os.listdir(path) # 读取or_path文件列表 for file in files: file_type = str(file).split('.')[-2] # 读取文件后缀 if file_type == tar_type: print("take{}from{}".format(file, files)) dir = path + '/' + file # 存储文件路径 deter = tar_path + '/' + str(file) shutil.copyfile(dir, deter)take_samefile(r"train", r"labels", "pngnew")
IOPub data rate exceeded.The Jupyter server will temporarily stop sending outputto the client in order to avoid crashing it.To change this limit, set the config variable`--ServerApp.iopub_data_rate_limit`.Current values:ServerApp.iopub_data_rate_limit=1000000.0 (bytes/sec)ServerApp.rate_limit_window=3.0 (secs)
3.2.4 重命名labels与images
PaddleSeg要求传入label数据的命名格式从0开始依次递增,例如:0.png,1.png,2.png…
因labels中图片与images中图片相对应,所以将两文件夹内的图片先排序在依次重命名,就可以使得两文件夹重命名后的同名图片也一一对应。例如123.jpg与123.png是相对应image和label。
In [ ]
'''labels图像批量重命名'''# 将labels文件内容排序后重命名import osstart = 0 # 开始的序号image_dir = '/home/aistudio/labels/' # 源图片路径images_list = os.listdir(image_dir)images_list.sort() # 文件名 按数字排序print(images_list)nums = len(os.listdir(image_dir))print('found %d pictures' % nums)output_dir = '/home/aistudio/labels/' # 图像重命名后的保存路径for i in images_list: os.rename(image_dir+i,output_dir+str(start)+'.png') # 前面是旧的路径,后面是新路径 start = start + 1print('finished!')
In [ ]
'''images图像批量重命名'''# 将images文件内容排序后重命名import osstart = 0 # 开始的序号image_dir = '/home/aistudio/images/' # 源图片路径images_list = os.listdir(image_dir)images_list.sort() # 文件名 按数字排序print(images_list)nums = len(os.listdir(image_dir))print('found %d pictures' % nums)output_dir = '/home/aistudio/images/' # 图像重命名后的保存路径for i in images_list: os.rename(image_dir+i,output_dir+str(start)+'.jpg') # 前面是旧的路径,后面是新路径 start = start + 1print('finished!')
In [22]
# 可视化相对应的image与labelimport cv2import matplotlib.pyplot as pltimport numpy as npimage = cv2.imread('images/0.jpg')plt.figure(figsize=(8,8))plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))image1 = cv2.imread('labels/0.png')plt.figure(figsize=(8,8))plt.imshow(cv2.cvtColor(image1, cv2.COLOR_BGR2RGB))plt.show()
In [23]
# 新建目录! mkdir /home/aistudio/data/DeepGlobe
In [24]
# 移动需要用的文件夹! mv /home/aistudio/images /home/aistudio/data/DeepGlobe! mv /home/aistudio/labels /home/aistudio/data/DeepGlobe
In [25]
%cd ~
/home/aistudio
3.2.5 生成train.txt与val.txt文件
按照7:3划分训练集与测试集并按照格式要求输出到train.txt与val.txt文件中
In [26]
# 生成yml所需的数据列表import osdata_path = '/home/aistudio/data/DeepGlobe/images' # 这里数据的img和lab的文件名一张,可以简单写imgs_name = os.listdir(data_path) # 获取文件夹下所有文件的名字with open(data_path.replace('images', 'train.txt'), 'w') as tf: with open(data_path.replace('images', 'val.txt'), 'w') as vf: for idx, img_name in enumerate(imgs_name): if img_name != ".ipynb_checkpoints": img_path = os.path.join('images', img_name) lab_path = img_path.replace('images', 'labels').replace('jpg', 'png') # 替换image为label的路径 # print(idx) if idx % 10 == 1 or idx % 10 == 2 or idx % 10 == 3: # 按7:3组织训练集和验证集 vf.write(img_path + ' ' + lab_path + 'n') else: tf.write(img_path + ' ' + lab_path + 'n') print('ok')
ok
In [27]
! mkdir -p /home/aistudio/work/PaddleSeg/data/DeepGlobe! mv data/DeepGlobe/ work/PaddleSeg/data/
4. 模型训练
下面将分别进行配置三个分割模型(PP-LiteSeg, DeepLabV3P, ANN),并开始训练。
更详细的模型库请参考:PaddleSeg模型库总览
模型训练与评估的详细指令可参考:PaddleSeg全流程跑通
In [2]
# 进入PaddleSeg的目录%cd /home/aistudio/work/PaddleSeg/
/home/aistudio/work/PaddleSeg
4.1 PP-LiteSeg模型
本模型选用的基本配置文件地址如下所示,并按照以下参数进行修改,完整修改后的配置文件请见附录代码。
Backbone: STDC2
/home/aistudio/work/PaddleSeg/configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml
4.1.1 开始PP-LiteSeg模型训练
训练指令中设定每100轮训练保存一次模型,并开启边训练边评估指令。配置文件的参数设定如下所示,为统一模型参数从而比较三种模型的效果,以下两个模型配置文件也将使用与此相同的参数配置。
batch_size: 8iters: 3500选用的数据增强操作如下所示:
transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化
optimizer: sgdlr_scheduler: PolynomialDecayloss: CrossEntropyLossIn [ ]
# 进入PaddleSeg的目录%cd /home/aistudio/work/PaddleSeg/# 设置1张可用的卡! export CUDA_VISIBLE_DEVICES=0 # 训练 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数! python train.py --config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml --do_eval --use_vdl --save_interval 100 --save_dir out/PPLiteSeg_yml_output # do_eval:是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model# log_iters:打印日志的间隔步数,默认为10# save_interval:模型保存的间隔步数# save_dir:模型和visualdl日志文件的保存根路径
4.1.2 PP-LiteSeg模型训练过程可视化
为了更直观我们的网络训练过程,对网络进行分析从而更快速的得到更好的网络,飞桨提供了可视化分析工具:VisualDL,训练中开启use_vdl指令,在模型保存文件夹下会自动保存.log文件,在侧边栏中的数据模型可视化选项中选中该logdir所在文件夹,打开即可看到可视化训练过程。更多可视化细节可参考:训练过程可视化
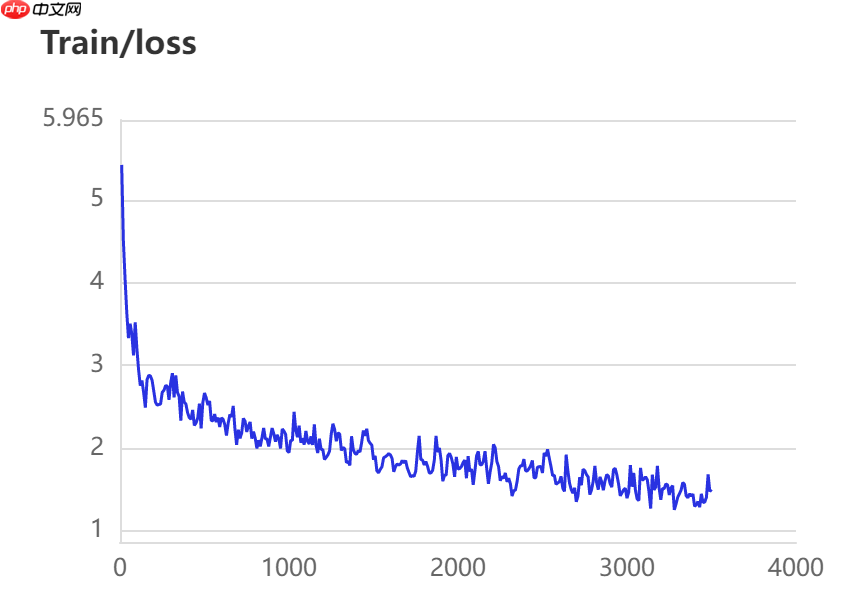
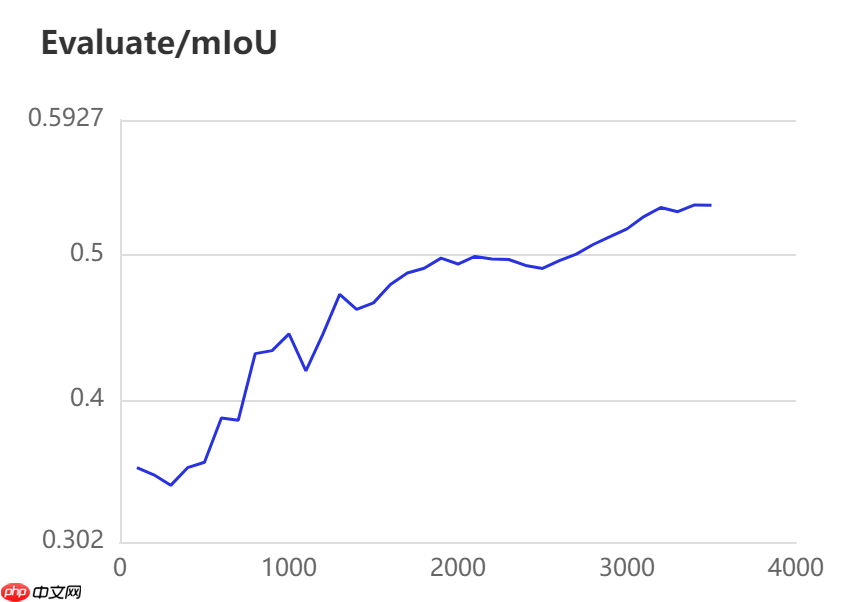
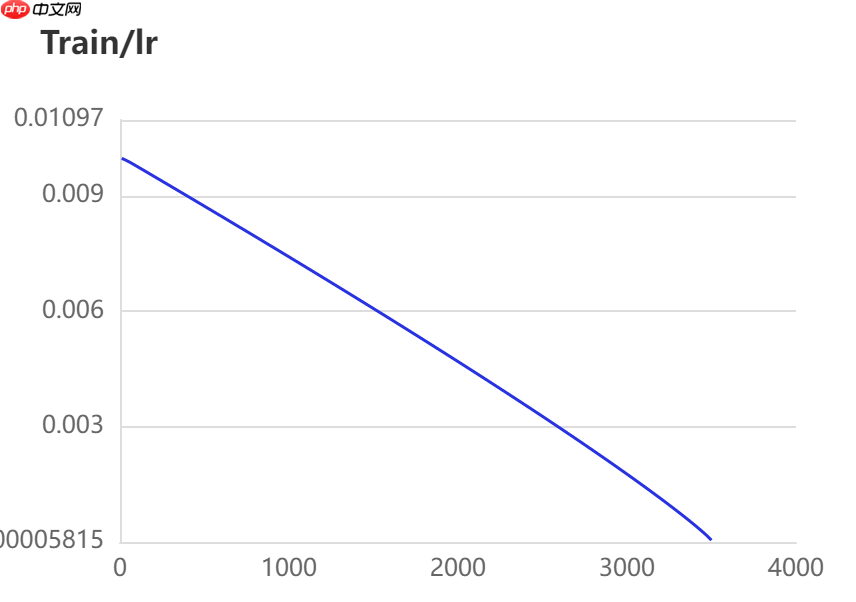
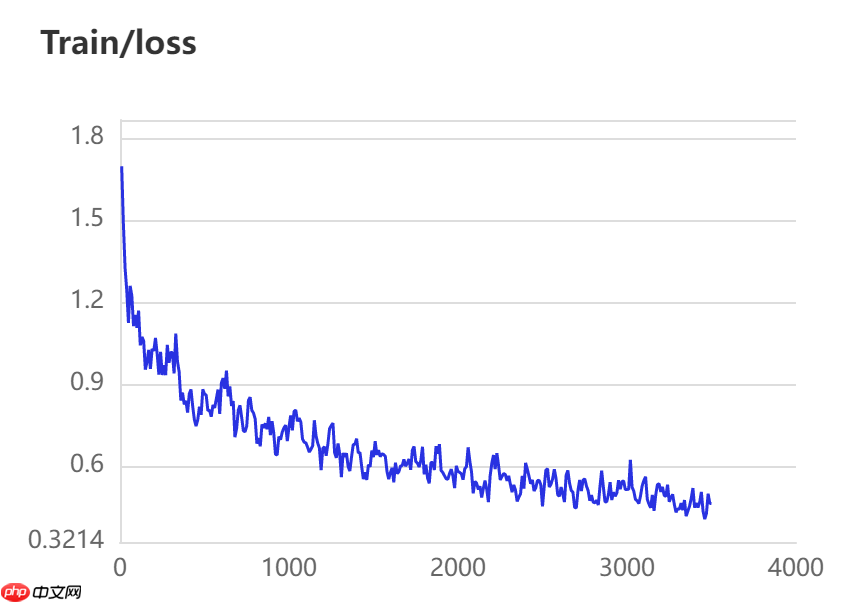
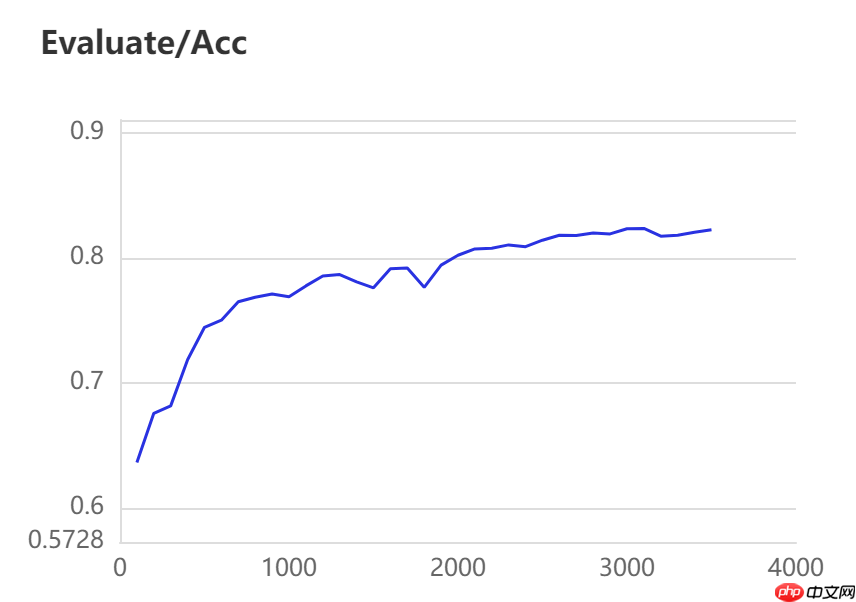
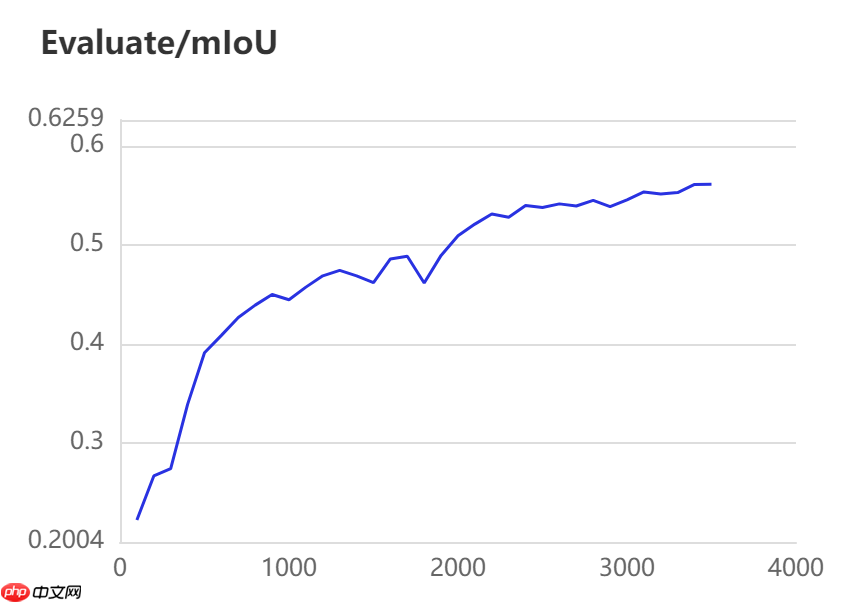
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件 3500轮训练过程中,学习率(learn rate)、训练损失(loss)、平均交并比(Mean Intersection over Union,简称mIoU)以及准确率(acc)的具体变化如下图所示。


4.2 Deeplabv3P模型
本模型选用的基本配置文件地址如下所示,并按照以下参数进行修改,完整修改后的配置文件请见附录代码。
Backbone: ResNet50_vd
/home/aistudio/work/PaddleSeg/configs/quick_start/deeplabv3p_resnet50_os8_optic_disc_512x512_1k_teacher.yml
4.2.1 开始Deeplabv3P模型训练
训练指令中设定每100轮训练保存一次模型,并开启边训练边评估指令。参数设定与上一个模型相同,详情如下所示:
batch_size: 8iters: 3500选用的数据增强操作如下所示:
transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化
optimizer: sgdlr_scheduler: PolynomialDecayloss: CrossEntropyLossIn [ ]
# 进入PaddleSeg的目录%cd /home/aistudio/work/PaddleSeg/# 设置1张可用的卡! export CUDA_VISIBLE_DEVICES=0 # 训练 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数! python train.py --config configs/quick_start/deeplabv3p_resnet50_os8_optic_disc_512x512_1k_teacher.yml --do_eval --use_vdl --save_interval 100 --save_dir output/deeplabv3p_yml_output
4.2.2 Deeplabv3P模型训练过程可视化
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件 3500轮训练过程中,学习率(learn rate)、训练损失(loss)、平均交并比(Mean Intersection over Union,简称mIoU)以及准确率(acc)的具体变化如下图所示。
4.3 ANN模型
训练指令中设定每100轮训练保存一次模型,并开启边训练边评估指令。本模型选用的基本配置文件地址如下所示,并按照以下参数进行修改,完整修改后的配置文件请见附录代码。
Backbone: ResNet101_vd
/home/aistudio/work/PaddleSeg/configs/ann/ann_resnet101_os8_voc12aug_512x512_40k.yml
4.3.1 开始ANN模型训练
参数设定与以上两个模型相同,详情如下所示:
batch_size: 8iters: 3500选用的数据增强操作如下所示:
transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化
optimizer: sgdlr_scheduler: PolynomialDecayloss: CrossEntropyLossIn [ ]
# 进入PaddleSeg的目录%cd /home/aistudio/work/PaddleSeg/# 设置1张可用的卡! export CUDA_VISIBLE_DEVICES=0 # 训练 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数! python train.py --config configs/ann/ann_resnet101_os8_voc12aug_512x512_40k.yml --do_eval --use_vdl --save_interval 100 --save_dir output/ann_yml_output
4.3.2 ANN模型训练过程可视化
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件 3500轮训练过程中,学习率(learn rate)、训练损失(loss)、平均交并比(Mean Intersection over Union,简称mIoU)以及准确率(acc)的具体变化如下图所示。
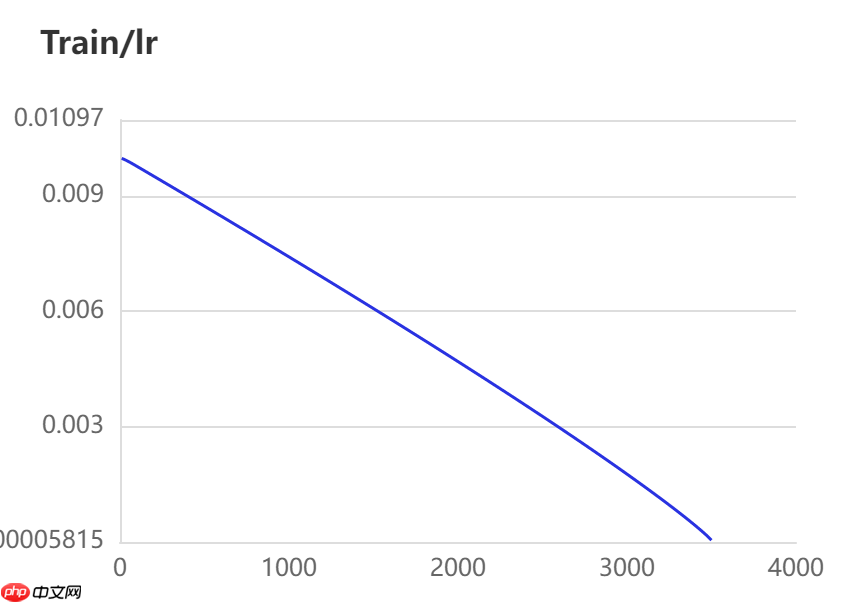
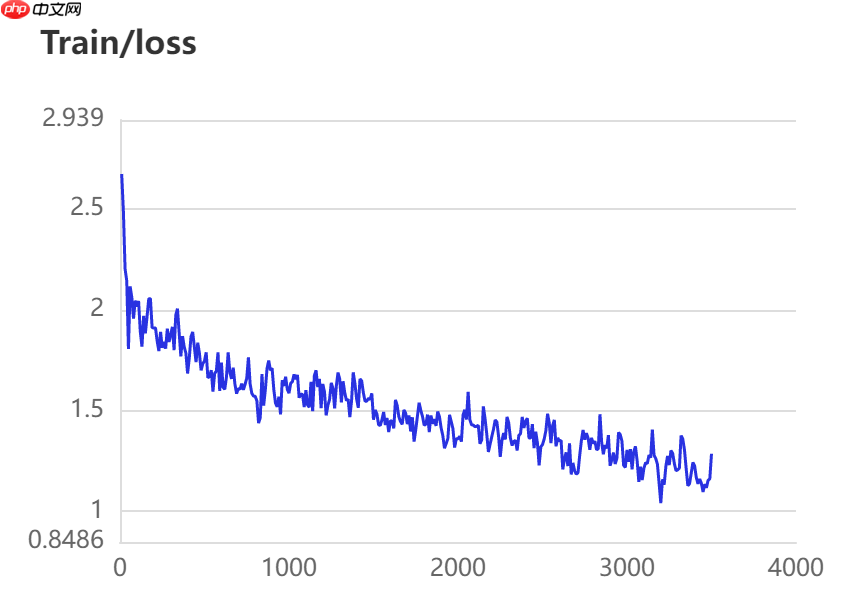
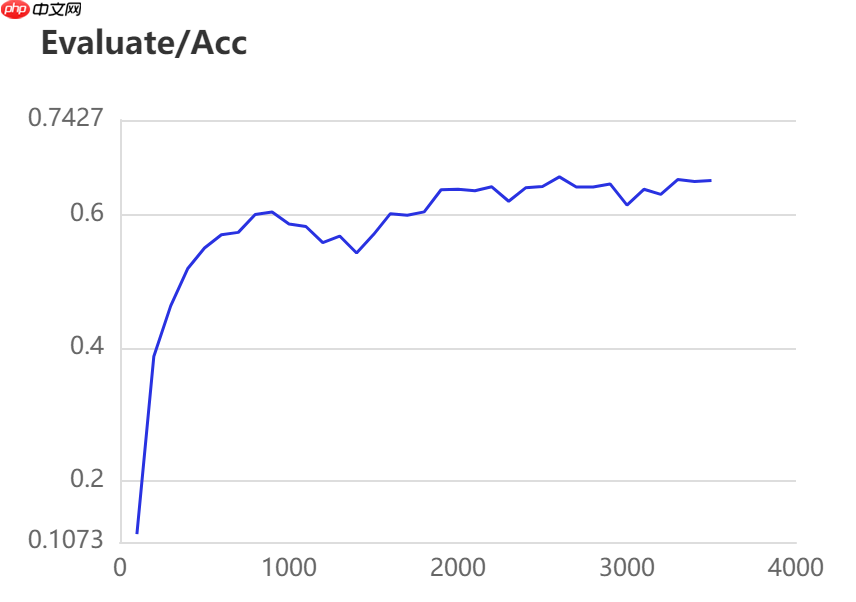
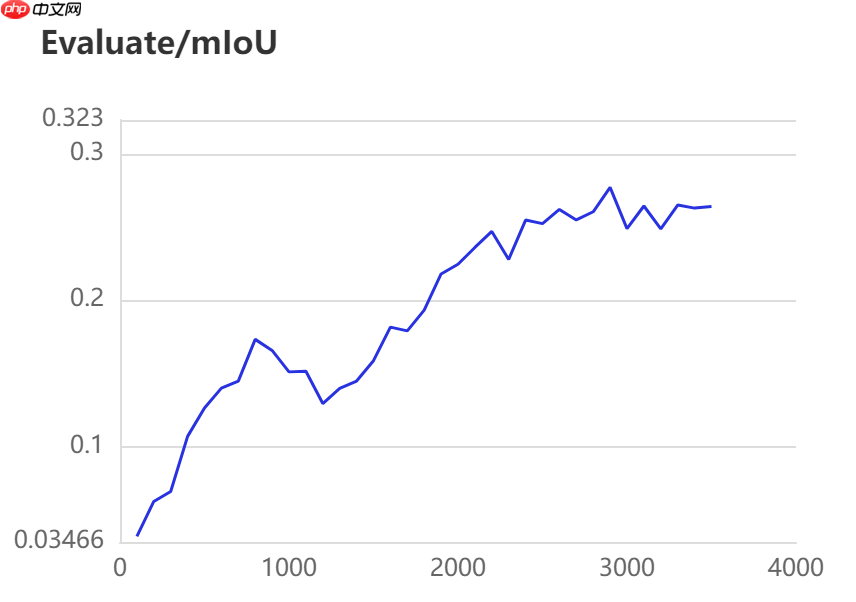
5. 模型评估
在图像分割领域中,评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
准确率:指类别预测正确的像素占总像素的比例,准确率越高模型质量越好。平均交并比:对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。Kappa系数:一个用于一致性检验的指标,可以用于衡量分类的效果。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。其公式如下所示,P0P_0P0为分类器的准确率,PeP_eP**e为随机分类器的准确率。Kappa系数越高模型质量越好。
5.1 评估PP-LiteSeg模型
使用如下命令评估训练保存的iter=3500时的模型
PP-LiteSeg模型评估结果如下所示:
mIoU: 0.5338Acc: 0.8206Kappa: 0.7199Dice: 0.6396In [ ]
! python val.py --config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml --model_path output/PPLiteSeg_yml_output/iter_3500/model.pdparams
5.2 评估Deeplabv3p模型
使用如下命令评估训练保存的iter=3500时的模型
Deeplabv3p模型评估结果如下所示:
mIoU: 0.5613Acc: 0.8246Kappa: 0.7470Dice: 0.6698In [ ]
! python val.py --config configs/quick_start/deeplabv3p_resnet50_os8_optic_disc_512x512_1k_teacher.yml --model_path output/deeplabv3p_yml_output/iter_3500/model.pdparams
5.3 评估ANN模型
使用如下命令评估训练保存的iter=3500时的模型
ANN模型评估结果如下所示:
mIoU: 0.2650Acc: 0.6530Kappa: 0.4466Dice: 0.3500In [ ]
! python val.py --config configs/ann/ann_resnet101_os8_voc12aug_512x512_40k.yml --model_path output/ann_yml_output/iter_3500/model.pdparams
6. 结果对比
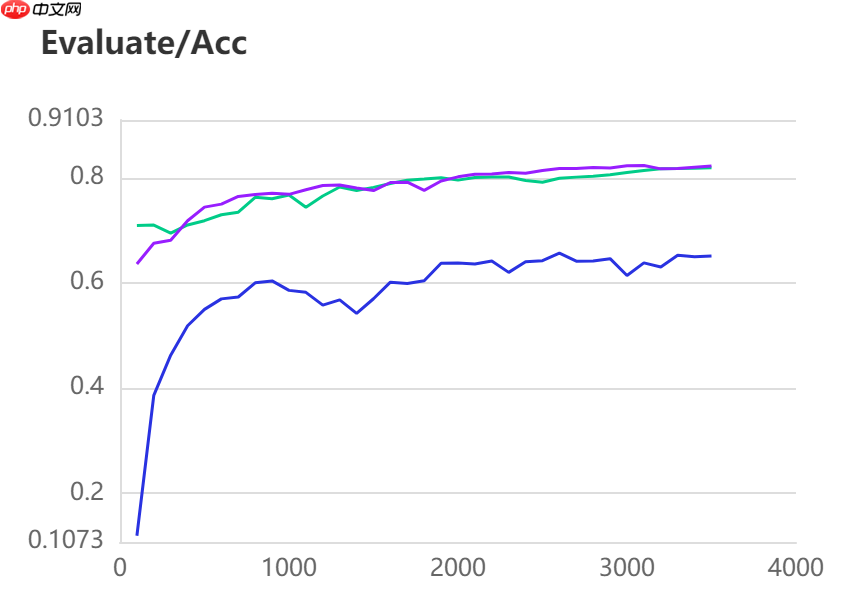
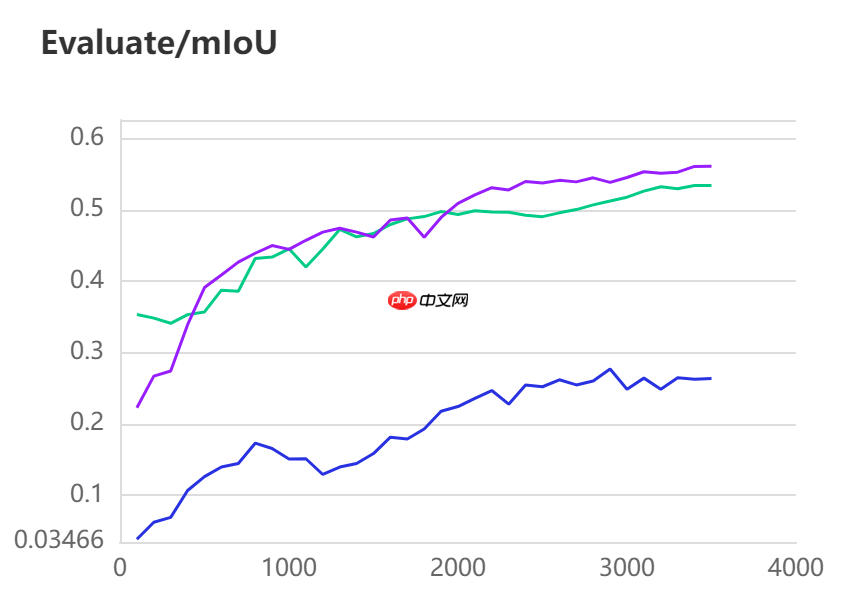
三种模型的效果(准确率与mIoU)详细对比如下所示:
图中记录了0-3500iter的完整训练过程,其中蓝色的线为ANN模型(Backbone: ResNet101_vd)训练效果,绿色的线为PP-LitSeg模型(Backbone: STDC2)训练效果,紫色的线为DeepLabv3p模型(Backbone: ResNet50_vd)的训练效果。
通过可视化训练结果可以看出,三种模型中,DeepLabv3p模型在DeepGlobe地表覆盖数据集中表现的效果更好。
7 附录配置文件
本项目中三个模型用到的完整配置文件代码如下所示:
# work/PaddleSeg/configs/quick_start/pp_liteseg_optic_disc_512x512_1k.ymlbatch_size: 8 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大iters: 3500 #模型迭代的次数train_dataset: #训练数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 train_path: data/DeepGlobe/train.txt #数据集中用于训练的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: train #表示用于训练 transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化val_dataset: #验证数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 val_path: data/DeepGlobe/val.txt #数据集中用于验证的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: val #表示用于验证 transforms: #数据预处理/增强的方式 - type: Normalize #图像进行归一化optimizer: #设定优化器的类型 type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器 momentum: 0.9 #动量 weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合lr_scheduler: # 学习率的相关设置 type: PolynomialDecay # 一种学习率类型。共支持12种策略 learning_rate: 0.01 power: 0.9 end_lr: 0loss: #设定损失函数的类型 types: - type: CrossEntropyLoss #损失函数类型 coef: [1, 1, 1] # PP-LiteSeg有一个主loss和两个辅助loss,coef表示权重: total_loss = coef_1 * loss_1 + .... + coef_n * loss_nmodel: #模型说明 type: PPLiteSeg #设定模型类别 backbone: # 设定模型的backbone,包括名字和预训练权重 type: STDC2 pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz
# work/PaddleSeg/configs/quick_start/deeplabv3p_resnet50_os8_optic_disc_512x512_1k_teacher.ymlbatch_size: 8iters: 3500train_dataset: #训练数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 train_path: data/DeepGlobe/train.txt #数据集中用于训练的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: train #表示用于训练 transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化val_dataset: #验证数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 val_path: data/DeepGlobe/val.txt #数据集中用于验证的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: val #表示用于验证 transforms: #数据预处理/增强的方式 - type: Normalize #图像进行归一化optimizer: type: sgd momentum: 0.9 weight_decay: 4.0e-5lr_scheduler: type: PolynomialDecay learning_rate: 0.01 end_lr: 0 power: 0.9loss: types: - type: CrossEntropyLoss coef: [1]model: type: DeepLabV3P backbone: type: ResNet50_vd output_stride: 8 multi_grid: [1, 2, 4] pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz num_classes: 7 backbone_indices: [0, 3] aspp_ratios: [1, 12, 24, 36] aspp_out_channels: 256 align_corners: False pretrained: Null
# work/PaddleSeg/configs/ann/ann_resnet101_os8_voc12aug_512x512_40k.yml_base_: 'ann_resnet50_os8_voc12aug_512x512_40k.yml'model: backbone: type: ResNet101_vd pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet101_vd_ssld.tar.gz
# work/PaddleSeg/configs/ann/ann_resnet50_os8_voc12aug_512x512_40k.yml_base_: '../_base_/pascal_voc12aug.yml'loss: types: - type: CrossEntropyLoss coef: [1, 0.4]model: type: ANN backbone: type: ResNet50_vd output_stride: 8 pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz backbone_indices: [2, 3] key_value_channels: 256 inter_channels: 512 psp_size: [1, 3, 6, 8] enable_auxiliary_loss: True align_corners: False pretrained: null
# work/PaddleSeg/configs/_base_/pascal_voc12aug.yml_base_: './pascal_voc12.yml'train_dataset: mode: train
# work/PaddleSeg/configs/_base_/pascal_voc12.ymlbatch_size: 8iters: 3500train_dataset: #训练数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 train_path: data/DeepGlobe/train.txt #数据集中用于训练的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: train #表示用于训练 transforms: #数据预处理/增强的方式 - type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍 min_scale_factor: 0.5 max_scale_factor: 2.0 scale_step_size: 0.25 - type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小 crop_size: [512, 512] - type: RandomHorizontalFlip #采用水平反转的方式进行数据增强 - type: RandomDistort #亮度、对比度、饱和度随机变动 brightness_range: 0.5 contrast_range: 0.5 saturation_range: 0.5 - type: Normalize #将图像归一化val_dataset: #验证数据设置 type: Dataset #数据集名字 dataset_root: data/DeepGlobe #数据集路径 val_path: data/DeepGlobe/val.txt #数据集中用于验证的标识文件 num_classes: 7 #指定目标的类别个数(背景也算为一类) mode: val #表示用于验证 transforms: #数据预处理/增强的方式 - type: Normalize #图像进行归一化optimizer: type: sgd momentum: 0.9 weight_decay: 4.0e-5lr_scheduler: type: PolynomialDecay learning_rate: 0.01 end_lr: 0 power: 0.9loss: types: - type: CrossEntropyLoss coef: [1]
以上就是【校园AI Day-AI workshop】卫星遥感图像切割多模型对比的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/46582.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫