您可能会认为同步加载脚本会让脚本下载后执行下一行代码,对吧?但这不是同步加载 javascript 文件的含义。当您比较加载特定文件的异步、同步和延迟策略时,就会出现混乱。
更多关于以异步、同步、延迟方式加载 javascript 文件的信息,请参见文章末尾。
在这里我们首先讨论代码执行。要在脚本成功下载后执行代码行,可以在 script 标签上使用 onload 属性。请参考下面的代码片段:
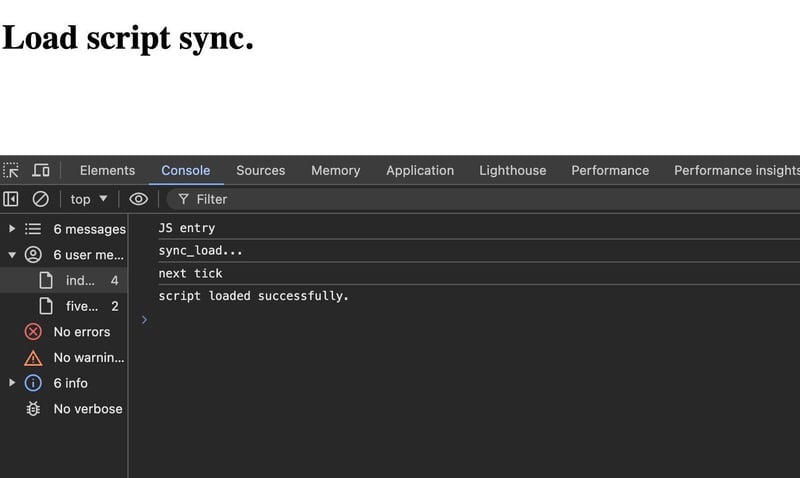
Sync Script Tag Load script sync.
function afterLoad() { console.log('script loaded successfully.') // executes after script has loaded } function sync_load() { console.log('sync_load...') var s = document.createElement('script'); s.type = 'text/javascript'; s.async = false; // load synchronously s.onload = afterLoad; s.src = "https://ajax.googleapis.com/ajax/libs/jquery/3.7.1/jquery.min.js"; var x = document.getElementsByTagName('script')[0]; x.parentNode.insertBefore(s, x); } console.log('JS entry') sync_load(); console.log('next tick') // this executes before after_load
输出:
现在,回到async vssync vs defer策略,请通过stackoverflow参考下图:
 挖错网
挖错网
一款支持文本、图片、视频纠错和AIGC检测的内容审核校对平台。
 28 查看详情
28 查看详情 

在这种情况下,异步与同步之间的区别在解析 html 文件时发挥作用。记住这一点!
快乐编码✨
以上就是使用脚本标签同步加载文件时要避免的常见错误的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/469368.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫