
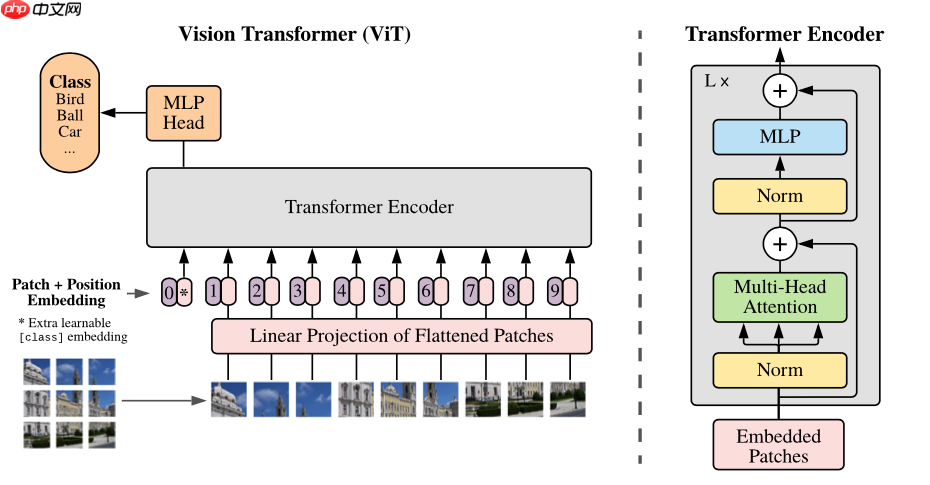
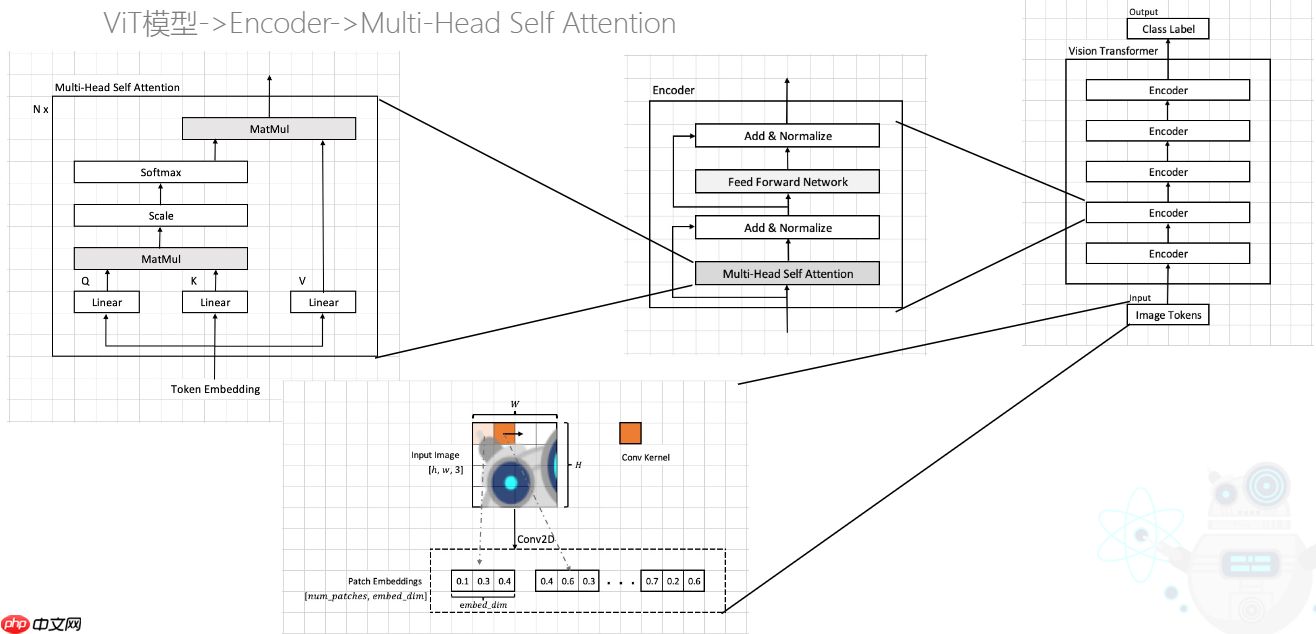
本文介绍Vision Transformer,其不依赖CNN,适用于图像分类与迁移学习。含PatchEmbedding层(图片分块嵌入,加位置和分类token)、多头自注意力层、Encoder层(组合注意力与MLP等),整体结构在大型数据集上表现超SOTA模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

整体介绍
当前Transformer模型被大量应用在NLP自然语言处理当中,而在计算机视觉领域,Transformer的注意力机制attention也被广泛应用,比如Se模块,CBAM模块等等注意力模块,这些注意力模块能够帮助提升网络性能。而我们的工作展示了不需要依赖CNN的结构,也可以在图像分类任务上达到很好的效果,并且也十分适合用于迁移学习。Vision Transformer将CV和NLP领域知识结合起来,对原始图片进行分块,展平成序列,输入进原始Transformer模型的编码器Encoder部分,最后接入一个全连接层对图片进行分类。在大型数据集上表现超过了当前SOTA模型
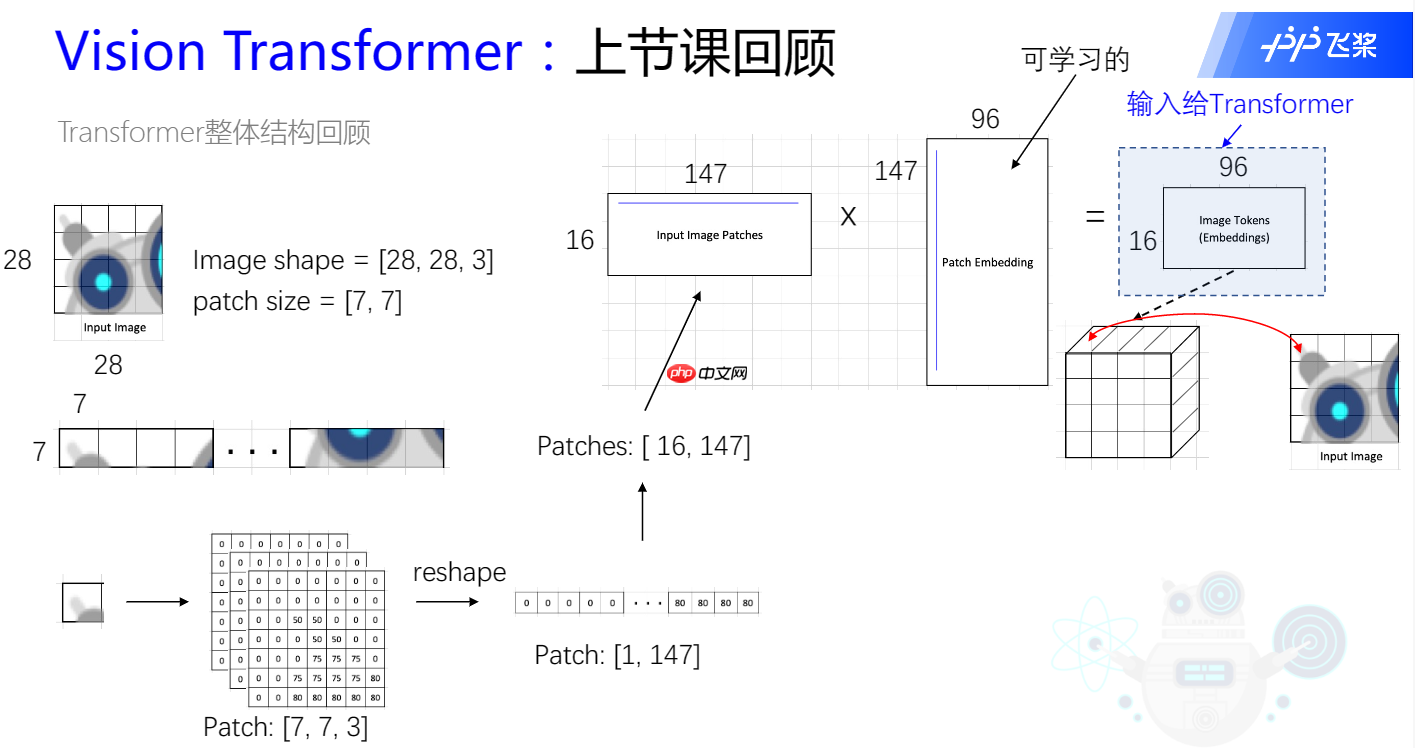
PatchEmbedding层
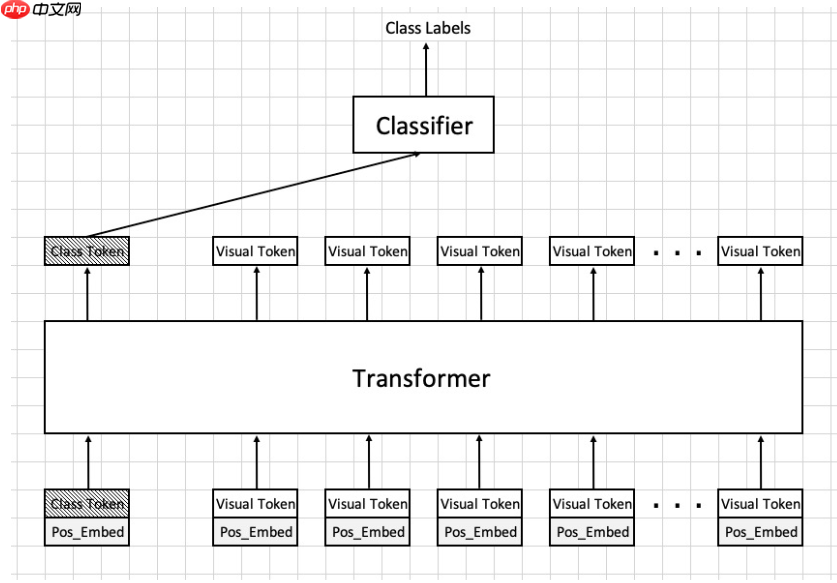
PatchEmbeddingPatchEmbedding主要是将输入的图片进行”分词”,将图片转换成一个一个的小块传入,在NLP里就对应sequencesequence,具体来说,例如下图所示,我们传进去的是(3,28,28)(3,28,28)的图片,经过Embedding层之后就会变成16个7∗716个7∗7 的小块,之后通过flatten将(7,7,3)(7,7,3)打平成147个像素点,于是就变成(16,147)(16,147),16就是我们所说的numpatchsnumpatchs,147147再接上全连接层后对应的就是embeddimembeddim,在传进transformstransforms之前需要将每一个tokentoken附上每一块的位置信息和分类模块,这里叫positionembeddingpositionembedding和classtokenclasstoken,二者值的确定都是可学习的参数,需要经过神经网络的学习进行优化
In [7]
import paddleimport paddle.nn as nnclass PatchEmbedding(nn.Layer): def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.): super().__init__() n_patches = (image_size // patch_size) * (image_size // patch_size) self.patch_embedding = nn.Conv2D(in_channels=in_channels, out_channels=embed_dim, kernel_size=patch_size, stride=patch_size) self.dropout = nn.Dropout(dropout) self.class_token = paddle.create_parameter( shape=[1, 1, embed_dim], dtype='float32', default_initializer=nn.initializer.Constant(0.)) self.position_embedding = paddle.create_parameter( shape=[1, n_patches+1, embed_dim], dtype='float32', default_initializer=nn.initializer.TruncatedNormal(std=.02)) def forward(self, x): # [n, c, h, w] clss_tokens = self.class_token.expand([x.shape[0], -1, -1]) # for batch,直接在第一个class_token后添加第一个X,之后将其拼接到X后 x = self.patch_embedding(x) # [n, embed_dim, h', w'] x = x.flatten(2) x = x.transpose([0, 2, 1]) x = paddle.concat([clss_tokens, x], axis=1) return x
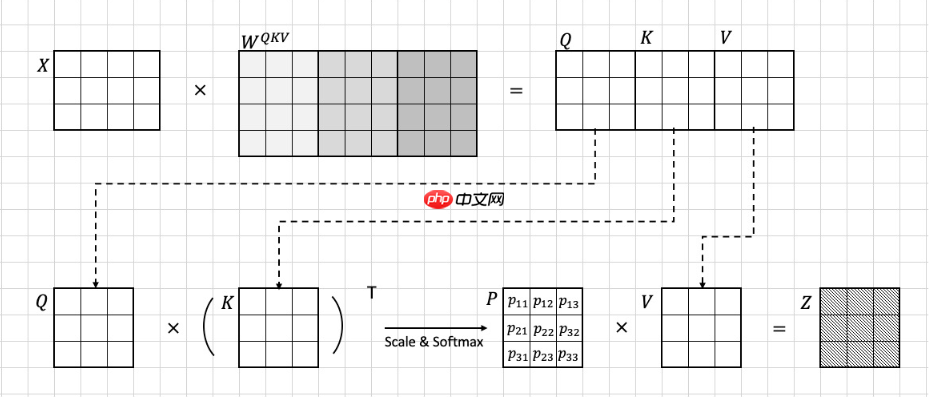
attention层
transformtransform里面最重要的部分可以说就是attentionattention层,attentionattention层的思路也是起源于NLP,为了找到每一个patchpatch与它附近的小块的信息,attentionattention的目的就是使每一个tokentoken注意到其他部分的信息,也叫自注意力机制。具体地,如下图所示,X是Embedding的输出,可以看到他的patch数量是3,也就是说有3个token,这里看到图中的WqWkWvWqWkWv和PP都是可学习的参数,其中我们将QKVQKV合成一个大的矩阵,目的是后续直接将该矩阵切成三份,QKQK的作用就是和其他的tokentoken做运算之后经过scaleforsoftmaxscaleforsoftmax,收集它们的信息,之后在和VV增加网络的复杂度
In [8]
class Attention(nn.Layer): """multi-head self attention""" def __init__(self, embed_dim, num_heads, qkv_bias=True, dropout=0., attention_dropout=0.): super().__init__() self.num_heads = num_heads self.head_dim = int(embed_dim / num_heads) self.all_head_dim = self.head_dim * num_heads self.scales = self.head_dim ** -0.5 self.qkv = nn.Linear(embed_dim, self.all_head_dim * 3) self.proj = nn.Linear(embed_dim, embed_dim) self.dropout = nn.Dropout(dropout) self.attention_dropout = nn.Dropout(attention_dropout) self.softmax = nn.Softmax(axis=-1) def transpose_multihead(self, x): # x: [N, num_patches, all_head_dim] -> [N, n_heads, num_patches, head_dim] new_shape = x.shape[:-1] + [self.num_heads, self.head_dim] x = x.reshape(new_shape) x = x.transpose([0, 2, 1, 3]) return x def forward(self, x): B, N, _ = x.shape # x -> [N, num_patches, dim] # x -> q, k, v qkv = self.qkv(x).chunk(3, axis=-1) # 切分qkv q, k, v = map(self.transpose_multihead, qkv) attn = paddle.matmul(q, k, transpose_y=True) # q * k' attn = attn * self.scales attn = self.softmax(attn) attn = self.attention_dropout(attn) out = paddle.matmul(attn, v) out = out.transpose([0, 2, 1, 3]) out = out.reshape([B, N, -1]) out = self.proj(out) return out
Encoder层
可以看到,在实现最重要的attentionattention之后,还需要实现MLPMLP,layearnormalizelayearnormalize以及残差层链接,组成EncoderEncoder层,五个EncoderEncoder组成一个transformtransform,在每个EncoderEncoder以及每个MLPMLP,layearnormalizelayearnormalize都不会改变数据的维度,目的是我们增加层数时不会变更太多
In [10]
class Identity(nn.Layer): def __init__(self): super().__init__() def forward(self, x): return xclass Mlp(nn.Layer): def __init__(self, embed_dim, mlp_ratio, dropout=0.): super().__init__() self.fc1 = nn.Linear(embed_dim, int(embed_dim * mlp_ratio)) self.fc2 = nn.Linear(int(embed_dim * mlp_ratio), embed_dim) self.act = nn.GELU() self.dropout = nn.Dropout(dropout) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.dropout(x) x = self.fc2(x) x = self.dropout(x) return xclass EncoderLayer(nn.Layer): def __init__(self, embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0, dropout=0., attention_dropout=0.): super().__init__() self.attn_norm = nn.LayerNorm(embed_dim) self.attn = Attention(embed_dim, num_heads) self.mlp_norm = nn.LayerNorm(embed_dim) self.mlp = Mlp(embed_dim, mlp_ratio) def forward(self, x): # TODO h = x # residual x = self.attn_norm(x) x = self.attn(x) x = x + h h = x x = self.mlp_norm(x) x = self.mlp(x) x = x + h return x class Encoder(nn.Layer): def __init__(self, embed_dim, depth): super().__init__() layer_list = [] for i in range(depth): encoder_layer = EncoderLayer() layer_list.append(encoder_layer) self.layers = nn.LayerList(layer_list) self.norm = nn.LayerNorm(embed_dim) def forward(self, x): for layer in self.layers: x = layer(x) x = self.norm(x) return x class VisualTransformer(nn.Layer): def __init__(self, image_size=224, patch_size=16, in_channels=3, num_classes=1000, embed_dim=768, depth=3, num_heads=8, mlp_ratio=4, qkv_bias=True, dropout=0., attention_dropout=0., droppath=0.): super().__init__() self.patch_embedding = PatchEmbedding(image_size, patch_size, in_channels, embed_dim) self.encoder = Encoder(embed_dim, depth) self.classifier = nn.Linear(embed_dim, num_classes) def forward(self, x): # x:[N, C, H, W] x = self.patch_embedding(x) # [N, embed_dim, h', w'] # x = x.flatten(2) # [N, embed_dim, h'*w'] h'*w'=num_patches # x = x.transpose([0, 2, 1]) # [N, num_patches, embed_dim] print(x.shape) x = self.encoder(x) print(x.shape) x = self.classifier(x[:, 0]) return xdef main(): t = paddle.randn([4, 3, 224, 224]) vit = VisualTransformer() out=vit(t) print('aaaaaaaaaa',out.shape) paddle.summary(vit, (4, 3, 224, 224)) #查看网络详细信息if __name__ == "__main__": main()
以上就是复现篇:Vision Transform复现及讲解的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/47271.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























