RCU是什么?
RCU的名字取自Read-Copy-Update(读-复制-更新)三个单词的首字母,至于为什么叫这个名字,主要还是和它的工作方式有关,它本质上是一种同步机制,为了便于建立概念,你可以暂时简单地将RCU和互斥锁、读写锁、自旋锁归为一类,但RCU与它们不同的是——RCU支持多个读者和单一写者并发进行,并且读者是无锁的,因此RCU适用于读密集型的应用场景。
看到这里,你或许有很多疑问,RCU为什么可以读写并发?为什么有写者存在时读者不需要等待写者操作完成?为什么有了读写锁之后还需要RCU?…别着急,下面将一一解答你的这些疑问。
RCU为什么可以读写并发?
在解释这个问题之前,请允许我先反问一个问题——为什么读写不能并发?原因当前显而易见了,因为读写并发会导致数据不一致,有人读到的是新数据,有人读到的是旧数据。如果我现在告诉你,当前场景不用担心数据不一致的问题呢?或者说数据不一致的影响几乎为0呢?是不是就没有顾虑了?答案当然不是,因为这里还有一种情况,就是写者有可能直接删除了旧数据(kfree),如果是这种情况,读者可能就会访问已经被free的数据,内核可能就直接挂掉了,因此RCU必然要引入一种新的方法来解决这个问题。接下来我们就看下RCU是如何解决这些问题的:
首先RCU将数据更新过程拆分分为“移除”和“回收”两个阶段(这里以删除链表的节点为例会更容易理解这2个阶段所做的事情)
移除阶段:写者删除链表里面的目标节点,但是并不释放该节点,此时从读者的视角看这个被删除的节点仍然是可见的。回收阶段:写者释放在移除阶段被移除的节点,这时候就需要考虑可能还存在部分读者还在使用这个节点,因此回收阶段必须等到这些读者都不再使用这个节点后才能开始。
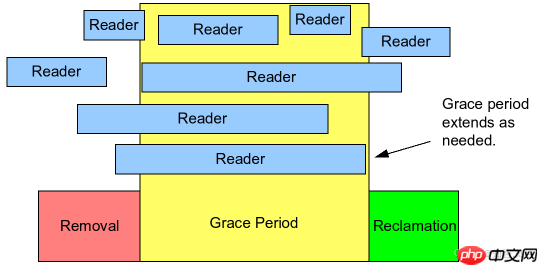
下面这张图可以更加直观的了解这个过程(红色的是移除阶段,绿色的是回收阶段,黄色的暂时不用关心)
 在这里插入图片描述
在这里插入图片描述在这张图片里,所有在红色区域开启的读者读到的数据可能是旧的,也可能是新的;在黄色和绿色区域读到的数据一定是新的。
简单总结下:RCU更新数据时,会同时维护新旧2份数据,同时记录哪些读者还在使用旧数据(使用新数据的读者并不需要关注),写者必须等待这些读者都不再使用旧数据后,才会真正释放掉旧数据的资源。
到这里你应该已经明白RCU是怎么运作的了,如果你还想继续搞清楚RCU是如何实现的,可以继续往下看,下文我们会结合代码来介绍RCU的工作原理。
在此之前,我们有必要介绍几个RCU的核心概念:
RCU 核心概念临界区
通过 rcu_read_lock() 和 rcu_read_unlock() 这两个宏来界定的代码区间称为(读)临界区。在临界区内,开发者可以安全地访问共享数据,而无需担心这些数据会被更改或删除。不过临界区内的代码需要遵守一项约定——临界区内的代码不可以进行进程切换(睡眠、主动让出CPU等操作),为什么需要这个约定将在后文中介绍。
在CONFIG_PREEMPTION=n 和 CONFIG_PREEMPT_COUNT=n不支持抢占 和 抢占计数器的内核, rcu_read_lock() 和 rcu_read_unlock() 仅仅只执行了 2条内存屏障的指令而已:
代码语言:javascript代码运行次数:0运行复制
#define preempt_disable() barrier()#define preempt_enable() barrier()static __always_inline void rcu_read_lock(void) // 简化后的代码,移除了一些空操作{ preempt_disable();}static inline void rcu_read_unlock(void) // 简化后的代码,移除了一些空操作{ preempt_enable();}注意:rcu_read_lock() 和 rcu_read_unlock()是保护普通数据的临界区API,在中断以及其他场景下会有不同的API,而且,并没有写临界区这一概念!
为什么需要临界区? 目的1:需要告知写者进入回收阶段的时机,但并不是通过信号或者其他通知机制实现的,这里的“告知”实际上是“隐式”的,因为读者和写者之间并无之间关联,后文将介绍具体实现逻辑。 目的2:保证需要读的指针在整个临界区内是一致的,这是因为读写可能是并发进行的,所以指针指向的数据很有可能发生”突变”,因此临界区的作用就是限制这种情况的发生——它可以保证在临界区内读到的数据是一致的,即要么都是旧数据,要么都是新数据。 为什么没有写临界区的概念? 这个问题应该改为:对单一写者来说为什么没有写临界区?这还是和RCU的机制有关,RCU能够容忍数据的短时间不同步,并且写者能保证原子地更新数据。如果存在多个写者,并且它们修改的是同一个数据结构(例如同一个链表节点),那么就需要额外的同步机制(互斥锁、自旋锁等等)来防止并发修改同一个共享数据。 宽限期(grace period)
从字面意思理解,宽限期就是在某个规定的时间范围内,给予一定的宽容或放宽处理的时期。再结合前面提到的写者必须要等待还在使用旧数据的读者完成后,才可以释放旧的数据,那么这个宽限期是为了谁而设置的就显而易见了——由于还有读者仍然在使用旧数据,为了不影响这些读者,它们会被允许继续使用旧数据,直到最后一个持有旧数据的读者退出临界区后,宽限期也随之结束。
宽限期的开始由写者触发,写者更新完数据后,内核会开启一次宽限期,但是写者无法控制宽限期结束,只能被动等待。宽限期的结束其实是由读者决定的,所有在宽限期开始前进入读临界区的读者均退出后宽限期自动结束。如果某个读者在临界区内进行了无限循环的操作,那么宽限期也将会无限延长。(这会触发RCU stall的警告,并且极有可能造成系统卡死、重启)
 灵机语音
灵机语音
灵机语音
 56 查看详情
56 查看详情  静默态(quiescent state)
静默态(quiescent state)
前面关于宽限期的概念中有提到写者无法控制宽限期结束,只能被动等待,那到底要等到什么时候呢?或者说必然需要一种机制能够让写者”知道”宽限期已经结束了,我们可能会想到使用信号量、通知链之类的方法,但是这些机制又会引入其他的锁,那这就和RCU无锁的设计初衷相悖了。
所以RCU提出了一种读者无感的方式来“告知”写者自己已经退出临界区了,让我们回忆下前面关于RCU临界区的那条约定:临界区内的代码不可以进行进程切换(睡眠、主动让出CPU等操作),我们假定所有的代码都是符合这个约定的,于是就可以反推出——一旦某个CPU进行了进程切换,那么此CPU一定不在临界区,所以确认CPU是否还在临界区的问题就转化成了确认此CPU是否进行过进程切换。
当CPU不处于临界区时,我们将此CPU定义为静默态,内核判断是否所有读者都已经退出临界区的条件就是检测CPU是否处于静默态,只要检测到CPU经历过一次上下文切换即可判定CPU经历过静默态,当系统中所有的CPU都经历了静默态后,宽限期结束。
对于读者来说这并没有增加任何额外的开销,只需要保证临界区内不进行进程切换即可。
RCU 的使用
这里仅介绍保护普通数据结构和链表 2种最常见的应用场景,除了这2种之外,其他应用在中断、调度器甚至支持睡眠的RCU都不在本文的讨论范围之内,感兴趣的同学可以仔细查看内核RCU文档(其他类型RCU)进行学习。
RCU保护普通数据结构的示例
下面介绍的是RCU保护普通数据结构的例子,这是RCU最简单的应用场景。
假设存在一个受RCU保护的共享指针 gbl_foo,其指向的数据结构定义如下:
代码语言:javascript代码运行次数:0运行复制
struct foo { int a; char b; long c;};DEFINE_SPINLOCK(foo_mutex);struct foo __rcu *gbl_foo; //受RCU保护的指针必须带上 __rcu标记读者示例代码语言:javascript代码运行次数:0运行复制
struct foo *p = NULL;rcu_read_lock(); //进入读临界区p = rcu_dereference(gbl_foo); //将受RCU保护的指针复制到局部变量if (p != NULL) { // 再解引用这个局部变量 do_something_with(p->a, p->b, p->c);}rcu_read_unlock();//退出读临界区如果不定义局部变量也是可以的,例如
代码语言:javascript代码运行次数:0运行复制
rcu_read_lock();do_something_with(rcu_dereference(gbl_foo)->a, rcu_dereference(gbl_foo)->b, rcu_dereference(gbl_foo)->c)rcu_read_unlock();请注意 rcu_dereference()返回的值仅在包含的 RCU 读取侧临界区内有效。例如,以下是不合法的:
代码语言:javascript代码运行次数:0运行复制
rcu_read_lock();p = rcu_dereference(gbl_foo);rcu_read_unlock();x = p->a; /* BUG!!! */rcu_read_lock();y = p->b; /* BUG!!! */rcu_read_unlock();写者示例代码语言:javascript代码运行次数:0运行复制
void foo_update_a(int new_a){ struct foo *new_fp; struct foo *old_fp; new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL); spin_lock(&foo_mutex); old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex)); *new_fp = *old_fp; new_fp->a = new_a; rcu_assign_pointer(gbl_foo, new_fp); spin_unlock(&foo_mutex); synchronize_rcu(); kfree(old_fp);}foo_mutex 用于保护多个写者需要修改同一个共享的变量, RCU只允许多个读者无锁,存在多个写者时必须加锁进行保护,示例中使用的是自旋锁,实际使用中可以根据需要选择不同的锁。rcu_dereference_protected() 是rcu_dereference()的变体,作用和rcu_dereference()一样,不过此函数专供写者使用,它可以在读临界区之外使用,但是需要使用锁进行保护,rcu_dereference()只能在读临界区使用,否则会出现lockdep 警告(“suspicious rcu_dereference_check() usage”)。lockdep_is_held(&foo_mutex)作用是检查是否已经持有foo_mutex,如果未持有,则会出现lockdep 警告 “suspicious rcu_dereference_protected() usage”rcu_assign_pointer() 更新受RCU保护的指针gbl_foosynchronize_rcu()阻塞等待宽限期结束,宽限期结束后,释放旧数据RCU保护链表的示例遍历链表示例
内核中 RCU 列表的一个广泛使用用例是无锁遍历系统中的所有进程。 task_struct->tasks 代表链接所有进程的链表节点。该列表可以与任何列表添加或删除操作并行遍历。for_each_process()是内核中遍历任务(进程)列表的宏。
假设有个读者正在使用这个接口来获取所有的进程信息,示例如下:
代码语言:javascript代码运行次数:0运行复制
// 关于for_each_process 的定义#define next_task(p) list_entry_rcu((p)->tasks.next, struct task_struct, tasks)#define for_each_process(p) for (p = &init_task ; (p = next_task(p)) != &init_task ; )// 读者示例struct task_struct *task;rcu_read_lock();for_each_process(task) {if (task) {do_something_with(task)}}rcu_read_unlock();写者示例如下:
代码语言:javascript代码运行次数:0运行复制
void release_task(struct task_struct *p) -->write_lock_irq(&tasklist_lock) -->__exit_signal(p) -->__unhash_process(tsk, group_dead) -->write_unlock_irq(&tasklist_lock) -->put_task_struct_rcu_user(p)// 简化版 __unhash_process()static void __unhash_process(struct task_struct *p, bool group_dead){ if (group_dead) { /*xxx*/list_del_rcu(&p->tasks); /*xxx*/}}void put_task_struct_rcu_user(struct task_struct *task){if (refcount_dec_and_test(&task->rcu_users))call_rcu(&task->rcu, delayed_put_task_struct);}static void delayed_put_task_struct(struct rcu_head *rhp){struct task_struct *tsk = container_of(rhp, struct task_struct, rcu);perf_event_delayed_put(tsk);trace_sched_process_free(tsk);put_task_struct(tsk);}写者可以并发调用release_task()释放一个已结束的任务(task)及其相关的资源.tasklist_lock用于防止并发列表添加/删除操作破坏列__unhash_process 会调用list_del_rcu 删除某个节点,但并不影响读者的遍历delayed_put_task_struct()是释放task资源的具体实现call_rcu()是synchronize_rcu()的异步版本。RCU 注意事项
这里总结下RCU的一些使用注意事项:
RCU 的直接操作对象必须是指针,被保护的目标数据结构需要能够被这个指针直接或者间接访问到。RCU适用于读多写少并且能够容忍短暂的数据不同步的场景,如果是写入比较多的场景,使用其他的同步机制可能更加合适RCU读临界区内不能调用可能引发休眠、调度的函数,否则可能会导致写者误判宽限期已经结束,从而释放旧数据。临界区内也不能长时间阻塞,过长时间的阻塞可能会触发RCU stall的警告,甚至系统重启。必须在正确的语境中调用RCU API,比如不能在读临界区内调用synchronize_rcu()rcu_read_lock() / rcu_read_unlock() 必须成对出现,支持嵌套调用参考RCU concepts 内核文档合集What is RCU, Fundamentally?深入理解 Linux 的 RCU 机制RCU锁原理与实现再谈Linux内核中的RCU机制Non-Preemptible RCU soft lockup: zap_pid_ns_processesLinux RCU 内核同步机制深入剖析Linux RCU原理(二)-渐入佳境【Linux 内核源码分析】RCU机制
以上就是【Linux内核】【锁机制】RCU机制入门的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/484616.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫