☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

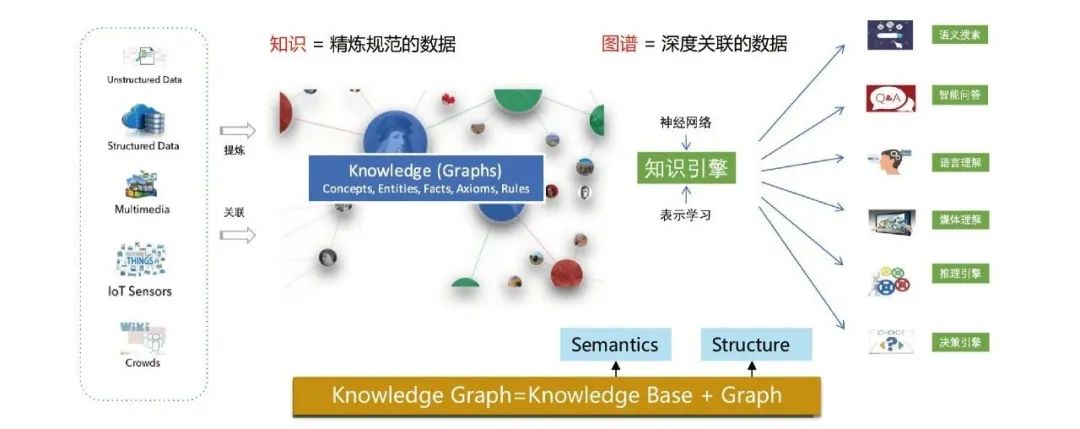
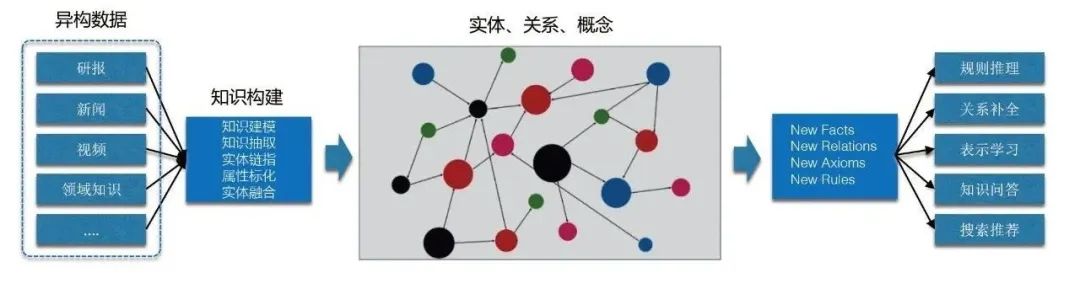
随着信息技术的发展和互联网的快速普及,大量海量的文本数据被创造和积累。这些数据包含了各种各样的信息,但如何从这些数据中提取有用的知识成为了一个挑战。知识图谱的出现为解决这个问题提供了一种有效的方法。知识图谱是一种以图为基础的知识表示和推理模型,通过将实体(Entity)以节点的形式连接起来,以关系(Relation)作为边来表示实体之间的关联,构建出一个结构化的知识网络。
在构建知识图谱的过程中,实体关系抽取是一个重要的环节。实体关系抽取旨在从海量文本数据中识别出实体之间的关系,将其转化为可供计算机理解和推理的结构化数据。而实体关系抽取的核心任务就是从文本中自动识别和抽取出实体及其关系。
为了解决实体关系抽取问题,研究者们提出了各种各样的方法和技术。下面介绍一个基于机器学习的实体关系抽取方法。
首先,需要准备训练数据集。训练数据集是指包含了已标注好实体和关系信息的文本数据集。通常需要手动标注一部分数据集,来作为模型的训练集和测试集。标注的方式可以是手工标注或半自动化标注。
接下来,需要进行特征工程。特征工程是将文本数据转化为计算机可以处理的特征向量的过程。常见的特征有词袋模型(Bag-of-Words)、词嵌入(Word Embedding)和句法分析树等。特征工程的目的是提取出能够表征实体和关系的有意义的特征,用于训练模型。
 AI建筑知识问答
AI建筑知识问答
用人工智能ChatGPT帮你解答所有建筑问题
 22 查看详情
22 查看详情 
然后,选择一个适合的机器学习算法进行模型训练。常见的机器学习算法包括支持向量机(Support Vector Machine)、决策树(Decision Tree)和深度学习算法等。这些算法可以通过训练数据集,学习到实体和关系之间的模式和规律。
最后,使用训练好的模型对未标注的文本进行实体关系抽取。给定一个文本句子,首先使用特征工程将其转化为特征向量,然后使用训练好的模型进行预测,得到实体和关系的结果。
以下是一个简单的Python代码示例,使用支持向量机算法进行实体关系抽取:
# 导入相应的库from sklearn.svm import SVCfrom sklearn.feature_extraction.text import TfidfVectorizer# 准备训练数据集texts = ['人民', '共和国', '中华人民共和国', '中华', '国']labels = ['人民与共和国', '中华人民共和国', '中华人民共和国', '中华与国', '中华人民共和国']# 特征工程,使用TfidfVectorizer提取特征vectorizer = TfidfVectorizer()features = vectorizer.fit_transform(texts)# 训练模型model = SVC()model.fit(features, labels)# 预测test_text = '中华共和国'test_feature = vectorizer.transform([test_text])predicted = model.predict(test_feature)print(predicted)
以上代码示例中,我们首先准备了一组训练数据集,其中包含了一些实体和关系的文本信息。然后使用TfidfVectorizer对文本进行特征提取,得到特征向量。接着使用支持向量机算法进行模型训练,最后对未标注的文本进行实体关系抽取预测。
总结而言,知识图谱构建中的实体关系抽取问题是一个重要的研究方向,通过机器学习的方法可以有效地解决这个问题。但是实体关系抽取仍然存在一些挑战,如语义歧义、上下文信息等。未来随着技术的不断发展和创新,相信这个问题会得到更好的解决。同时,我们也需要注意在实践中遵循数据隐私和知识伦理等相关问题,确保知识图谱构建的合法性和可信度。
以上就是知识图谱构建中的实体关系抽取问题的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/487268.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫