Hadoop的数据存储原理主要依赖于Hadoop分布式文件系统(HDFS),以下是其核心原理:
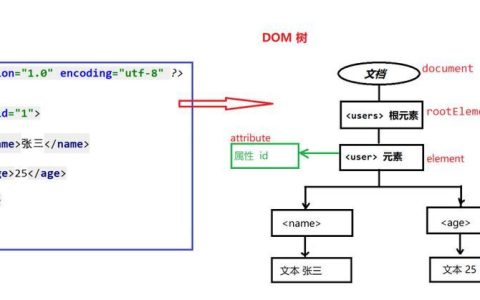
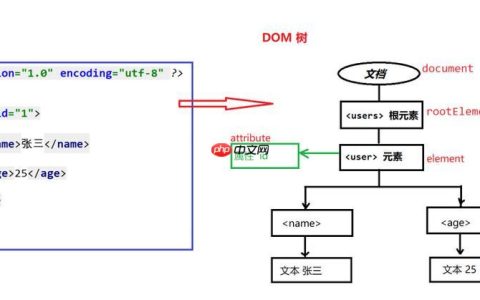
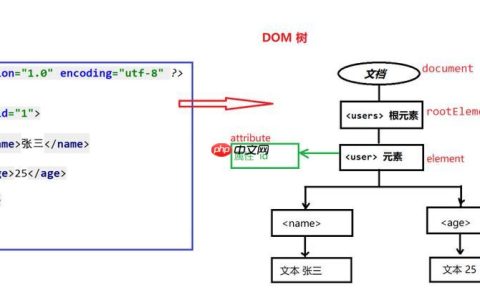
HDFS架构
NameNode:
管理文件系统的元数据,包括文件名、权限和块信息。维护文件系统的命名空间及块映射表。处理客户端的读写请求,并将请求转发至相应的DataNode。
Secondary NameNode:
协助NameNode,定期合并编辑日志和文件系统镜像,减轻NameNode的内存负担。在NameNode出现故障时,用于恢复文件系统的状态。
DataNode:
 阿里云-虚拟数字人
阿里云-虚拟数字人
阿里云-虚拟数字人是什么? …
 2 查看详情
2 查看详情  存储数据块的实际节点。负责数据的读写操作。定期向NameNode发送心跳信号和块报告,以报告其存活状态及存储的块信息。
存储数据块的实际节点。负责数据的读写操作。定期向NameNode发送心跳信号和块报告,以报告其存活状态及存储的块信息。
数据存储过程
写入数据:
客户端通过HDFS API启动写操作。NameNode接收请求后,分配数据块,并向客户端返回DataNode列表。客户端将数据流式传输至第一个DataNode,该节点将数据复制到其他DataNode(默认副本数为3)。所有DataNode完成写入后,向NameNode报告成功。
读取数据:
客户端发起读请求,NameNode返回包含所需数据块位置的DataNode列表。客户端从其中一个DataNode直接读取数据块。如果某个DataNode不可用,客户端会尝试连接列表中的下一个DataNode。
数据冗余与容错
副本机制:HDFS默认为每个数据块创建三个副本,分布在不同的DataNode上,以避免单点故障。数据本地化读取:优先从与客户端最近的DataNode读取数据,以减少网络传输延迟。心跳检测:DataNode定期向NameNode发送心跳信号,NameNode通过这些信号监控集群的健康状态。
数据一致性
HDFS采用“最终一致性”模型,即写入操作完成后,所有副本最终会达到一致状态。在写入过程中,如果某个副本失败,HDFS会自动重试写入其他副本。
扩展性
HDFS设计用于处理大规模数据集,能够水平扩展到数千个节点。通过增加DataNode的数量,可以线性提升存储容量和处理能力。
容错性
除了副本机制外,HDFS还支持机架感知(Rack Awareness),确保数据在物理位置上的分散存储,进一步提高容错性。
总之,Hadoop的数据存储原理通过分布式架构、数据冗余、数据本地化和容错机制,实现了高效、可靠的大规模数据存储和处理能力。
以上就是Hadoop数据存储原理是什么的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/510329.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫