
运行平台:WindowsPython版本:Python3.6IDE:Sublime Text其他工具:Chrome浏览器
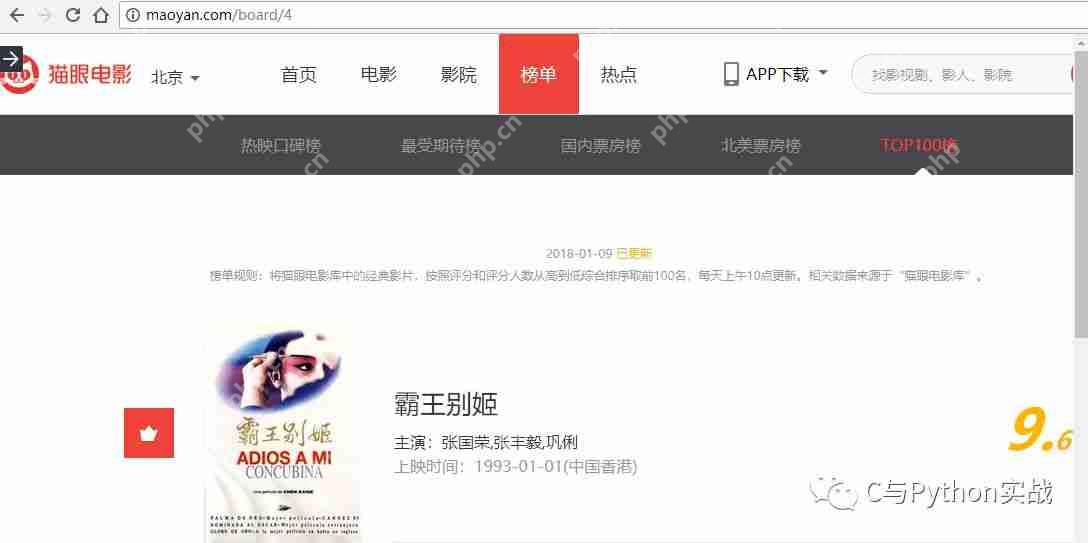
获取单页内容首先,在Chrome浏览器中打开猫眼电影首页,点击“榜单”,然后选择”TOP100榜”,即可查看所需内容。
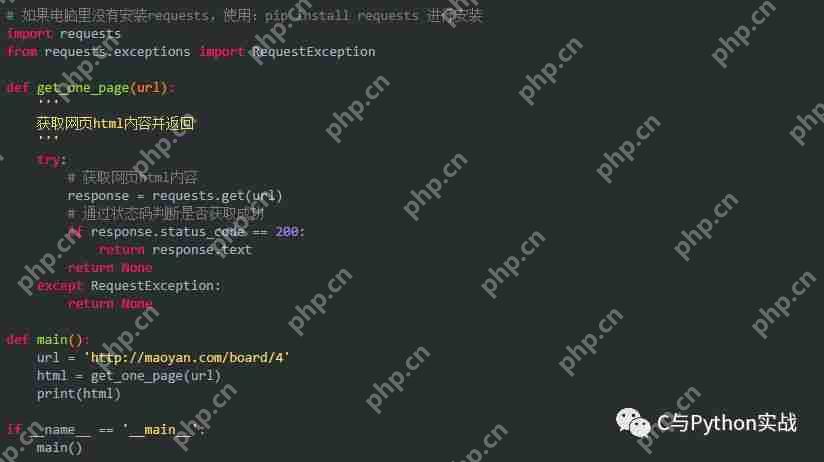
 接下来,我们通过编写代码来提取网页的HTML内容。
接下来,我们通过编写代码来提取网页的HTML内容。
 运行结果如下:
运行结果如下:
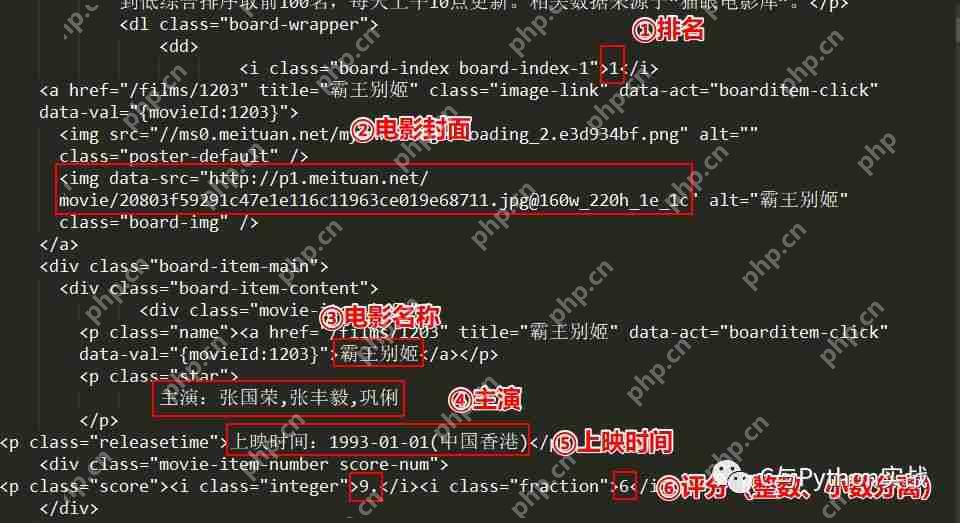
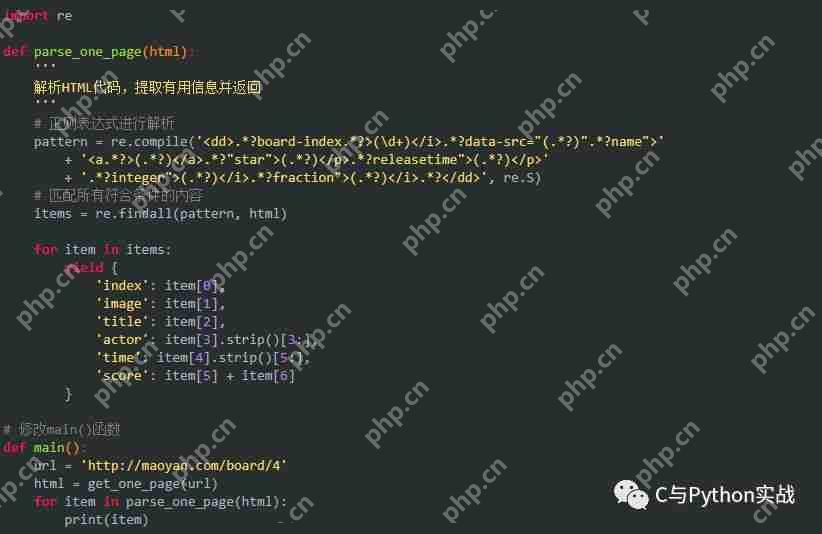
使用正则表达式提取关键信息在上图中,我们已经标记了需要提取的内容,下面通过代码实现这一步骤:
 运行结果如下:
运行结果如下:
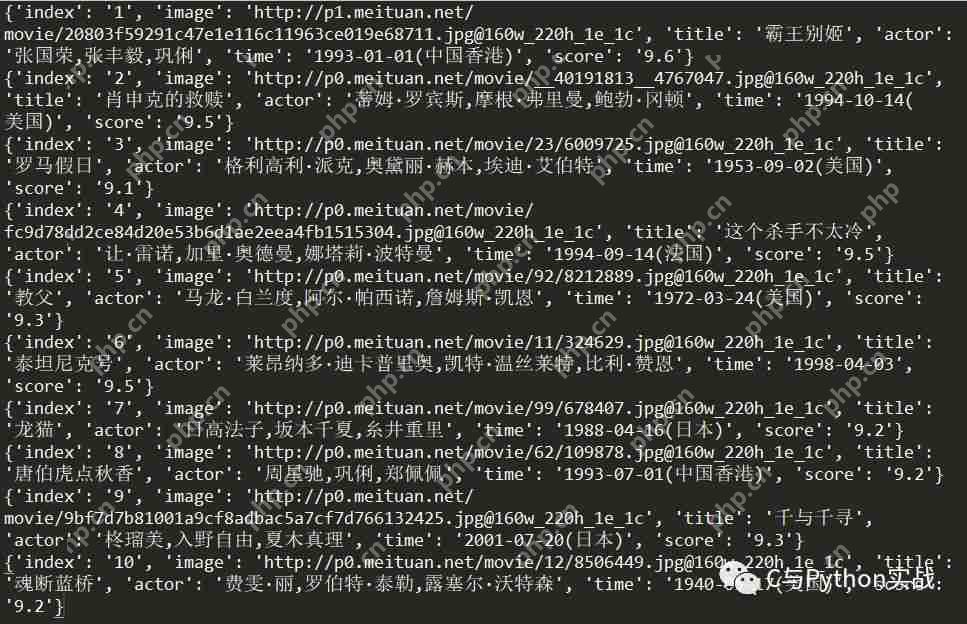
存储获取的电影信息在获取电影信息后,我们需要将这些数据保存起来,包括文本信息和电影封面。
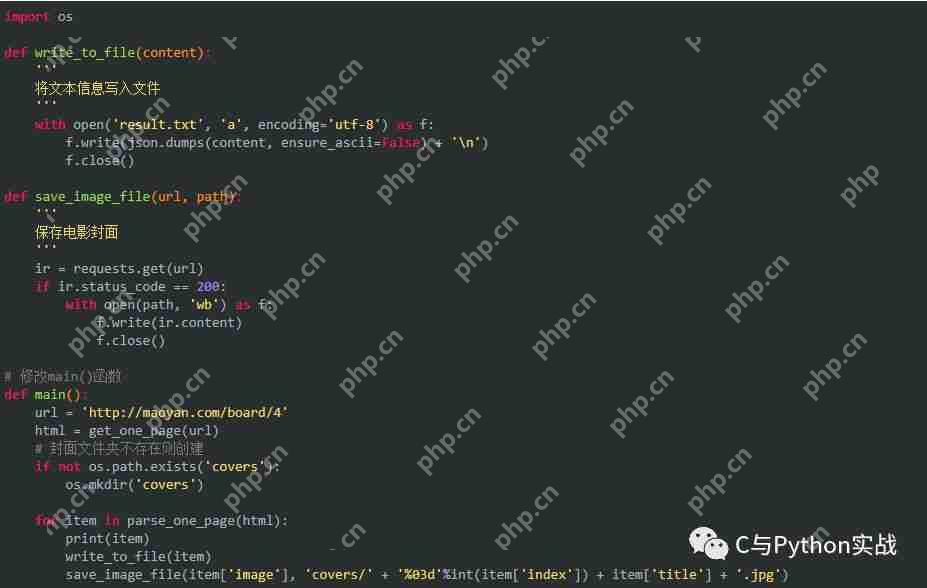 保存结果如下:
保存结果如下:

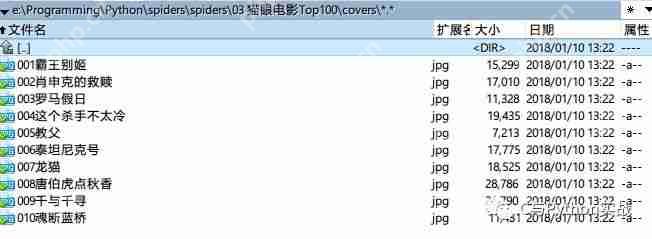
下载TOP100所有电影信息通过点击标签页,我们发现只是URL发生了变化:
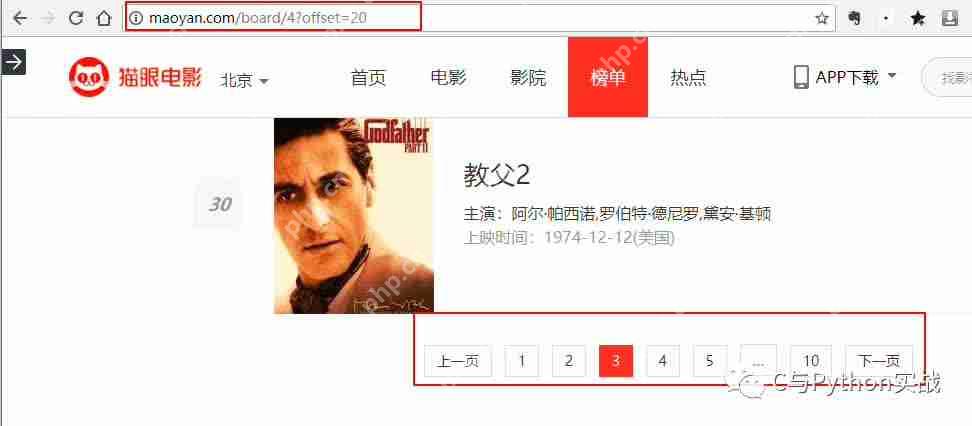 修改main函数以动态改变URL:
修改main函数以动态改变URL:
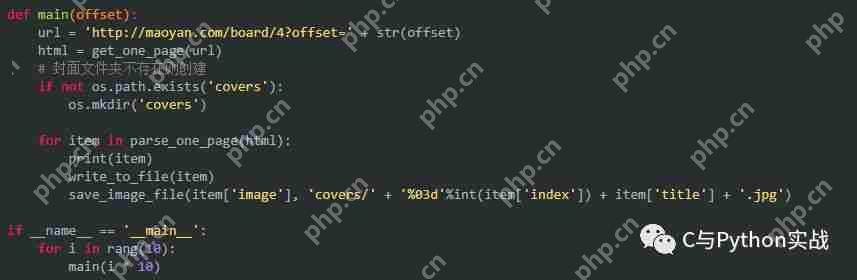 至此,我们已经成功获取了TOP100的电影信息和封面。
至此,我们已经成功获取了TOP100的电影信息和封面。
多线程抓取虽然此次抓取的数据量不大,但为了学习,我们使用多进程进行抓取,以应对未来可能的大量数据抓取。
 以下是普通抓取和多进程抓取的时间对比:
以下是普通抓取和多进程抓取的时间对比:

以下是完整代码:
 影谱
影谱
汉语电影AI辅助创作平台
 8 查看详情
8 查看详情 
立即学习“Python免费学习笔记(深入)”;

以上就是Python爬虫之三:抓取猫眼电影TOP100的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/514360.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















