
国内自研大模型迎来新面孔,而且发布即开源!
最新消息,多模态大语言模型TigerBot正式亮相,包含70亿参数和1800亿参数两个版本,均对外开源。
由该模型支持的对话AI同步上线。
写广告语、做表格、纠正语法错误,效果都不错;也支持多模态,能生成图片。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

评测结果显示,TigerBot-7B已达到OpenAI同样大小模型综合表现的 96%。
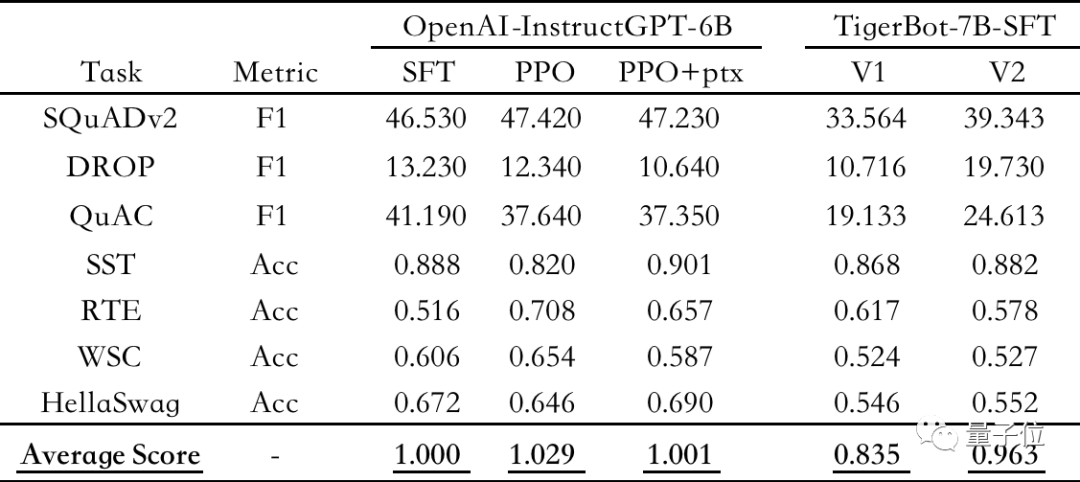
△公开 NLP 数据集上的自动评测,以OpenAI-instruct GPT-6B-SFT为基准,归一化并平均各模型的得分情况
而更大规模的TigerBot-180B或是目前业内开源的最大规模大语言模型。
此外,团队还一并开源100G预训练数据、监督微调1G或100万条数据。
基于TigerBot,开发者在半天内就能打造出自己的专属大模型。
目前TigerBot对话AI已邀请内测,开源代码数据等已上传至GitHub(详细链接见文末)。
如上这些重磅工作,来自一支最初只有5人的小团队,首席程序员&科学家就是CEO本人。
但这个团队,绝非师出无名。
从2017年起,他们就在NLP领域开始创业,专长垂直领域搜索。最擅长对数据重度以来的金融领域,和方正证券、国信证券等有过深入合作。
创始人兼CEO,有着20多年从业经验,曾任UC伯克利客座教授,手握3篇最佳顶会论文和10项技术专利。
如今,他们决心从专长领域走向通用大模型。
而且一开始便从最底层的基础模型做起,3个月内完成3000次实验迭代,还有底气将阶段性成果对外开源。
不禁让人好奇,他们是谁?想要做哪些事?如今已经带来了哪些阶段性成果?
TigerBot是什么?
具体来看,TigerBot是一款国产自研的多语言任务大模型。
覆盖生成、开放问答、编程、画图、翻译、头脑风暴等15大类能力,支持子任务超过60种。
而且支持插件功能,能让模型联网,获取到更加新鲜的数据和信息。
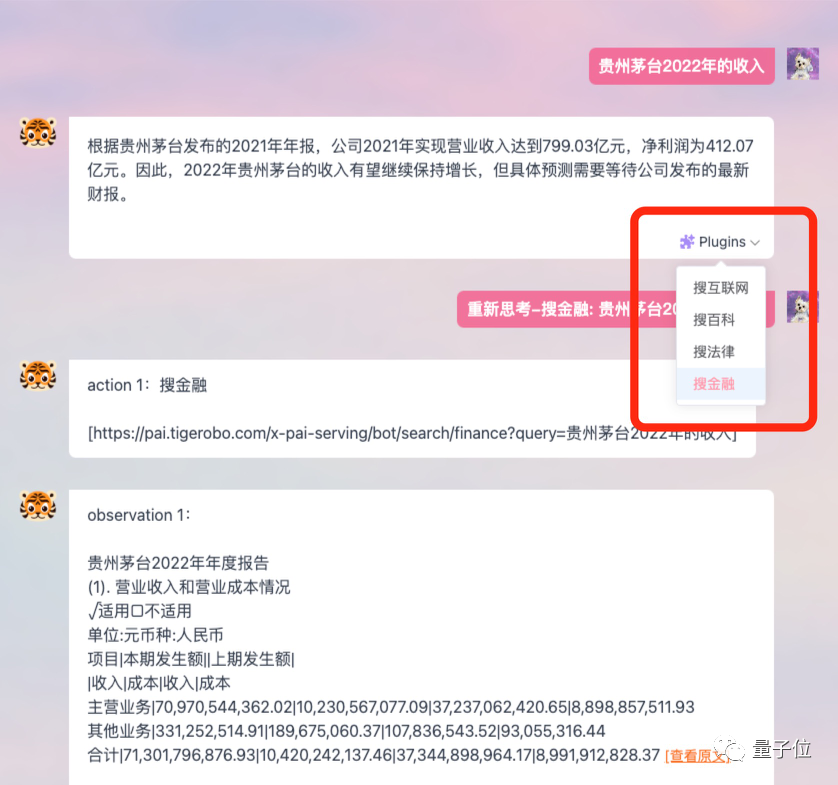
它的定位更偏向办公场景,提出改善人们工作流、提高效率的目标。
比如让它来帮我写一条Apple Vision Pro的新闻快讯,效果有模有样:

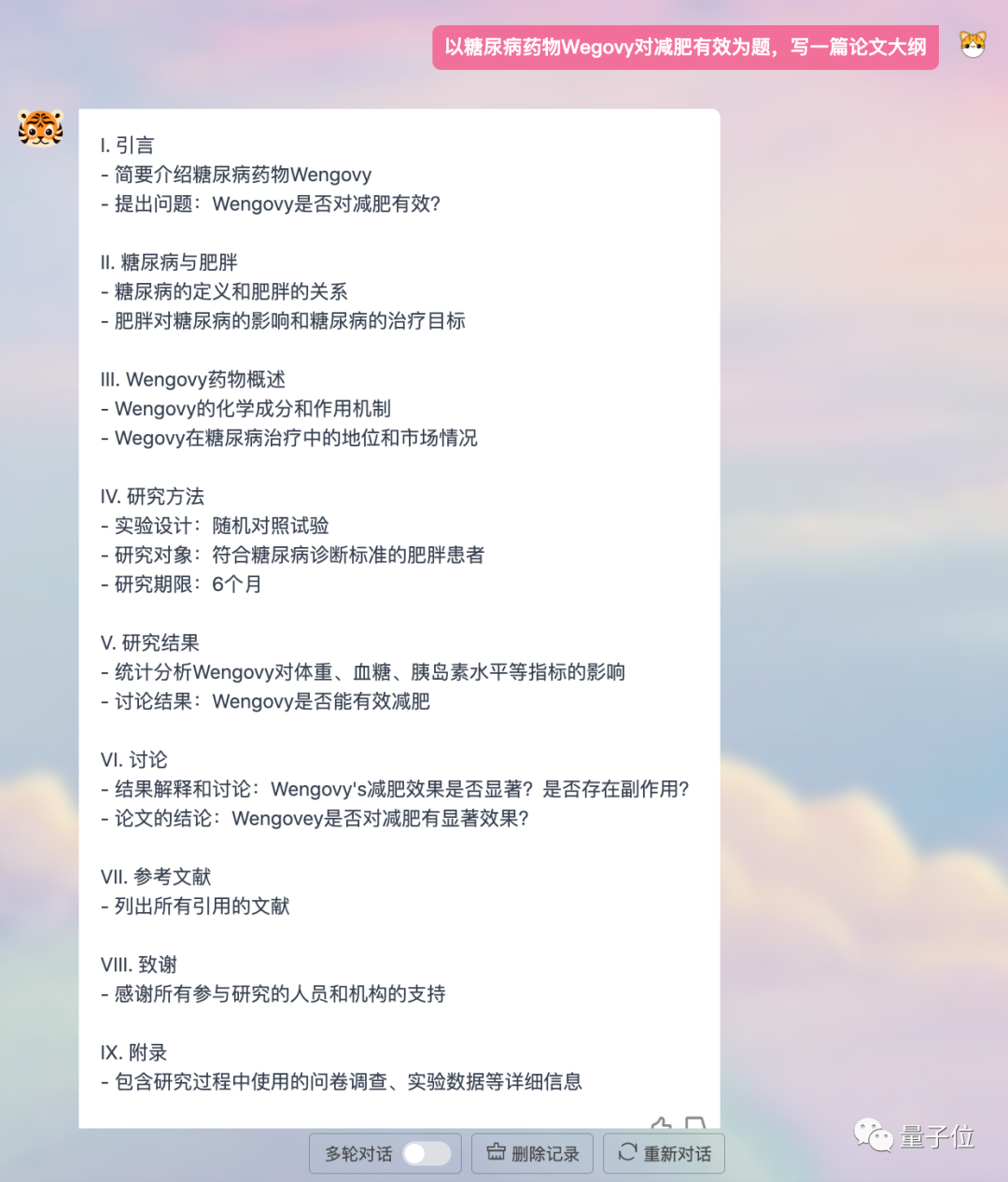
或者写一个论文大纲,条理清晰、结构合理:
编程也没问题,并且支持英文对话。
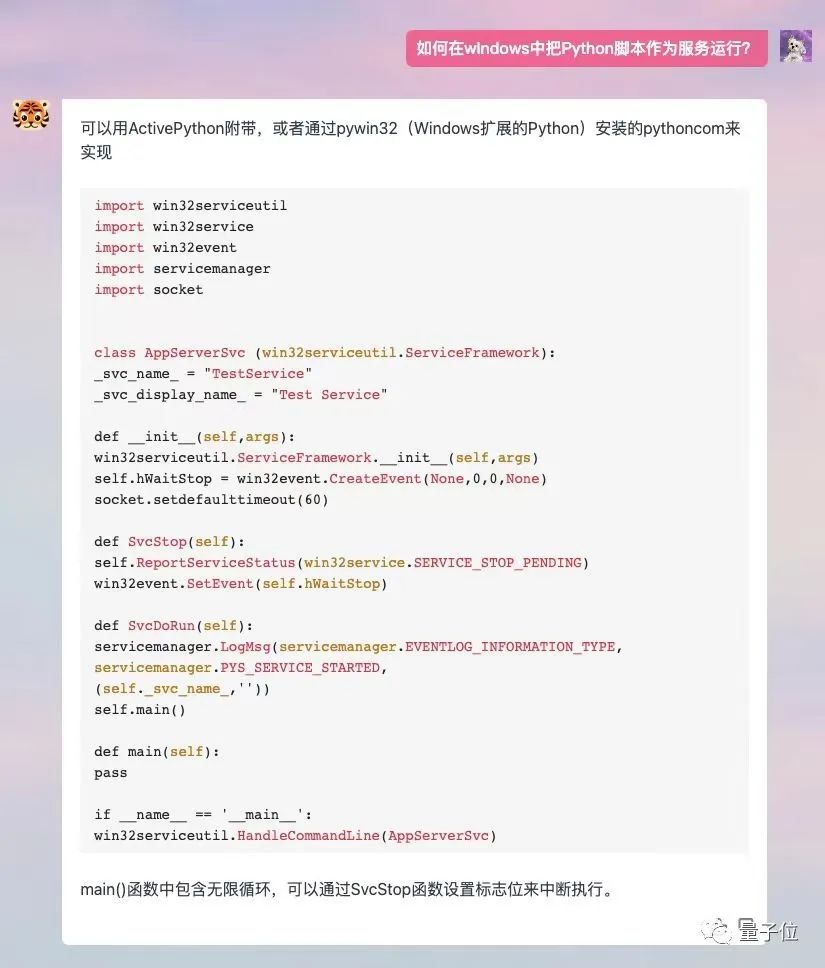
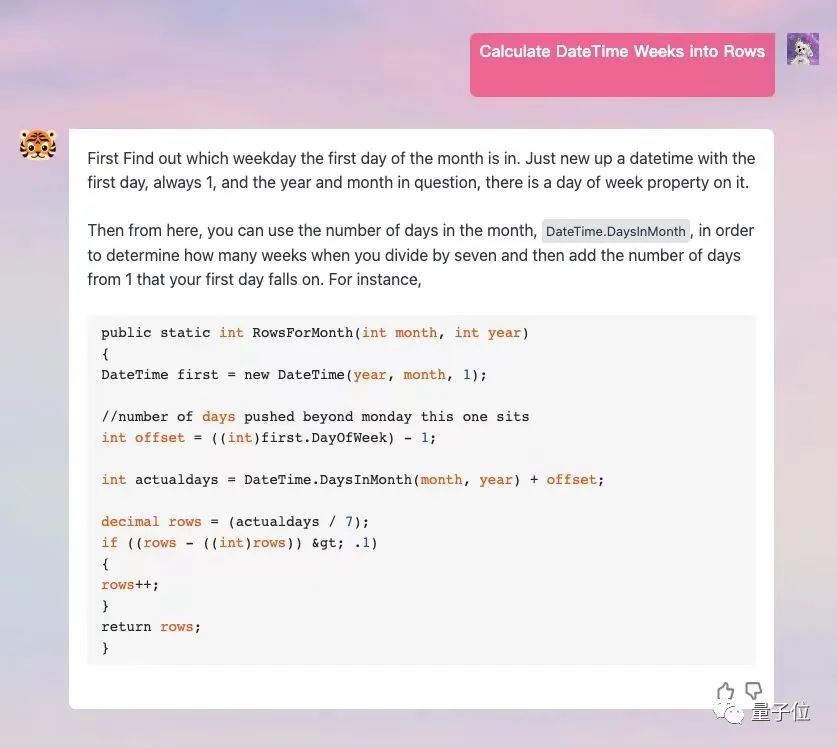
如果让它画图的话,每次都会生成3张不一样的,可以自己挑选。

这次发布,TigerBot一共推出了两种size:70亿参数(TigerBot-7B)和1800亿参数(TigerBot-180B)。
团队将目前取得的阶段性成果——模型、代码、数据,通通开源。
开源模型包括三个版本:
TigerBot-7B-sftTigerBot-7B-baseTigerBot-180B-research
其中TigerBot-7B-base的表现优于OpenAI同等可比模型、BLOOM。TigerBot-180B-research或是目前业内开源的最大规模模型(Meta开源OPT的参数量为1750亿、BLOOM则为1760亿规模)。
开源代码包括基本训练和推理代码,双卡推理180B模型的量化和推理代码。
数据包括100G预训练数据,监督微调1G或100万条数据。
根据OpenAI InstructGPT论文在公开NLP数据集上的自动评测,TigerBot-7B已达到 OpenAI 同样大小模型的综合表现的96%。
而这一版本还只是MVP(最小可行性模型)。
这些成果主要得益于团队在GPT和BLOOM基础上,在模型架构和算法上都做了更进一步的优化,也是TigerBot团队过去几个月来的主要创新工作,让模型的学习能力、创造力和生成可控上都有明显提升。
具体如何实现?往下看。
性能提升同时降低成本
TigerBot带来的创新主要有以下几个方面:
提出指令完成监督微调的创新算法提升模型可学习性运用ensemble和probabilistic modeling的方法实现可控事实性和创造性在并行训练上突破deep-speed等主流框架中的内存和通信问题,实现千卡环境下数月无间断针对中文语言更不规则的分布,从tokenizer到训练算法上做了更适合的优化
首先来看指令完成监督微调方法。
它能让模型在只使用少量参数的情况下,就能快速理解人类提出了哪类问题,提升回答的准确性。
原理上使用了更强的监督学习进行控制。
通过Mark-up Language(标记语言)的方式,用概率的方法让大模型能够更准确区分指令的类别。比如指令的问题是偏事实类还是发散类?是代码吗?是表格吗?
因此TigerBot涵盖了10大类、120类小任务。然后让模型基于判断,朝着对应方向优化。
带来的直接好处是调用参数量更少,同时模型对新数据或任务的适应能力更好,即学习性(learnability)提高。
在同样50万条数据训练的情况下,TigerBot的收敛速度比斯坦福推出的Alpaca快5倍,在公开数据集上评测显示性能提升17%。
其次,模型如何更好平衡生成内容的创造性和事实可控性,也非常关键。
TigerBot一方面采用ensemble的方法,将多个模型组合起来兼顾创造性和事实可控性。
甚至可以根据用户的需求,调整模型在二者之间的权衡。
另一方面还采用了AI领域经典的概率建模(Probabilistic Modeling)方法。
它能让模型在生成内容的过程中,根据最新生成的token,给出两个概率。一个概率判断内容是否应该继续发散下去,一个概率表示生成内容离事实内容的偏离程度。
综合两个概率的数值,模型会在创造性和可控性上做一个权衡。TigerBot中这两个概率的得出由专门数据进行训练。
考虑到模型生成下一个token时,往往无法看到全文的情况,TigerBot还会在回答写完后再进行一次判断,如果最终发现回答不准确,便会要求模型重写。
我们在体验过程中也发现,TigerBot生成回答并不是ChatGPT那样逐字输出的模式,而是在“思考”后给出完整答案。

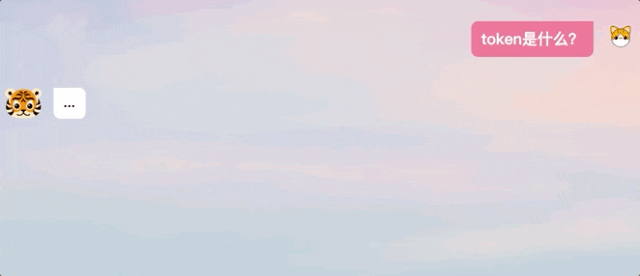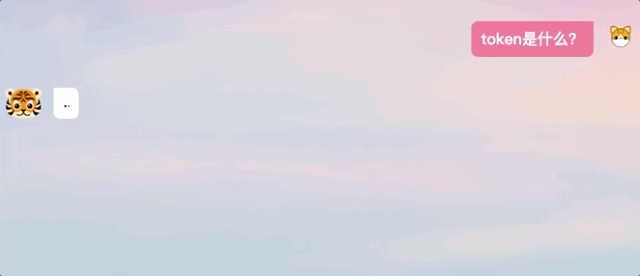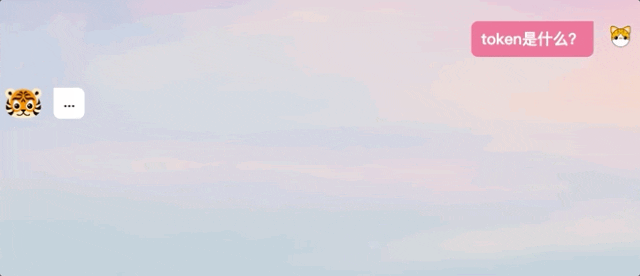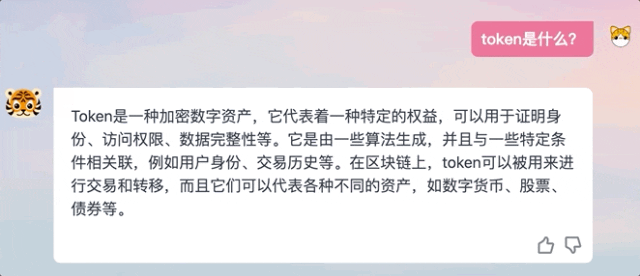
△ChatGPT和TigerBot回答方式对比
而且由于TigerBot的推理速度很快,能够支撑模型快速重写。
这里就要说到TigerBot在训练和推理上的创新了。
除了思考到模型底层架构的优化,TigerBot团队认为工程化水平在当下大模型时代也很重要。
一方面是因为要考虑运营效率——随着大模型趋势持续,谁能更快迭代模型非常关键;另一方面当然还要考虑算力的经济性。
因此,他们在并行训练方面,突破了deep-speed等主流框架中的若干内存和通信问题,实现了千卡环境下训练数月无间断。
这使得他们每月在训练上的开销,能够节省数十万。
最后,针对中文连续性强、多义歧义情况多等问题,TigerBot从tokenizer到训练算法上,都做了相应优化。
总结来看,TigerBot实现的技术创新,全都发生在当下大模型领域中最受关注的领域内。
不仅是底层架构的优化,还考虑到了落地层面的用户需求、开销成本等问题。并且整个创新过程的速度非常快,是10人左右小团队在几个月时间内实现。
这对团队本身的开发能力、技术见解、落地经验都有非常高的要求。
所以,到底是谁带着TigerBot突然杀入大众视野?
虎博科技是谁?
TigerBot的幕后开发团队,其实就藏在它本身的名字里——虎博科技。
 可图大模型
可图大模型
可图大模型(Kolors)是快手大模型团队自研打造的文生图AI大模型
 32 查看详情
32 查看详情 
它成立于2017年,也就是人们常说的AI上一轮爆发期内。
虎博科技给自己的定位是“一家人工智能技术驱动的公司”,专注于NLP技术的应用落地,愿景是打造下一代智能且简单的搜索体验。
具体实现路径上,他们选择了对数据信息最为敏感的领域之一——金融。自研了垂直领域内智能搜索、智能推荐、机器阅读理解、总结、翻译等技术,推出了智能金融搜索和问答系统“虎博搜索”等。
公司创始人兼CEO为陈烨,是一位世界级AI科学家。

他博士毕业于威斯康辛大学麦迪逊分校,曾任加州大学伯克利分校客座教授,到现在为止从业已有20余年。
他先后在微软、eBay、雅虎担任主任科学家和研发总监等要职,主导研发了雅虎的行为定向系统、eBay的推荐系统以及微软搜索广告竞拍市场机制等。
2014年,陈烨加入大众点评。之后美团点评合并,他任美团点评高级副总裁,分管集团广告平台,助力集团年广告收入从1000万提升至40多亿。
学术方面,陈烨曾三次获得顶会最佳论文奖(KDD和SIGIR),在SIGKKD、SIGIR、IEEE等人工智能学术会议上发表20篇论文,拥有10项专利。
2017年7月,陈烨正式创立虎博科技。成立1年后,虎博便快速拿下超亿元融资,目前公司披露融资总额达4亿元。

7个月以前,ChatGPT横空出世,AI在时隔6年以后,再次颠覆大众认知。
即便是陈烨这样在AI领域内创业多年的技术专家,也用“从业以来前所未有的震撼”来形容。
而在震撼之外,更多还是激动。
陈烨说,看到ChatGPT后,几乎不用思考或决定,内心的呼唤让他一定会跟进趋势。
所以,从1月份开始,虎博正式成立了TigerBot的初始开发团队。
不过和想象中不太一样,这是一支极客风格非常鲜明的团队。
用他们自己的话来说,致敬硅谷90年代经典的“车库创业”模式。
团队最初只有5个人,陈烨是首席程序员&科学家,负责最核心的代码工作。后面成员规模虽有扩充,但也只控制在了10人,基本上一人一岗。
为什么这样做?
陈烨的回答是:
我认为从0到1的创造,是一件很极客的事,而没有一个极客团队是超过10个人的。
以及纯技术科学的事,小团队更犀利。
的确,TigerBot的开发过程里,方方面面都透露着果断、敏锐。
陈烨将这个周期分为三个阶段。
第一阶段,也就是ChatGPT爆火不久后,团队迅速扫遍了OpenAI等机构过去5年内所有相关文献,大致了解ChatGPT的方法机制。
由于ChatGPT代码本身不开源,当时相关的开源工作也比较少,陈烨自己上阵写出TigerBot的代码,然后马上开始跑实验。
他们的逻辑很简单,让模型先在小规模数据上验证成功,然后经过系统科学评审,也就是形成一套稳定的代码。
在一个月时间内,团队就验证了模型在70亿规模下能达到OpenAI同规模模型80%的效果。
第二阶段,通过不断吸取开源模型和代码中的优点,加上对中文数据的专门优化处理,团队快速拿出了一版真实可用的模型,最早的内测版在2月便已上线。
同时,他们还发现在参数量达到百亿级别后,模型表现出了涌现的现象。
第三阶段,也就是到了最近的一两个月内,团队在基础研究上实现了一些成果和突破。
如上介绍的诸多创新点,就是在这一时期内完成的。
同时在这一阶段内整合更大规模算力,达到更快的迭代速度,1-2个星期内,TigerBot-7B的能力便快速从InstructGPT的80%提升到了96%。
陈烨表示,在这个开发周期内,团队始终保持着超高效运转。TigerBot-7B在几个月内经历了3000次迭代。
小团队的优势是反应速度快,早上确定工作,下午就能写完代码。数据团队几个小时就能完成高质量清洗工作。
但高速开发迭代,还只是TigerBot极客风格的体现点之一。
因为他们仅凭10个人在几个月内肝出来的成果,将以全套API的形式向行业开源。
如此程度的拥抱开源,在当下趋势尤其是商业化领域内,比较少见。
毕竟在激烈竞争中,构建技术壁垒是商业公司不得不面对的问题。
那么,虎博科技为什么敢于开源?
陈烨给出了两点理由:
第一,作为一名AI领域内的技术人员,出于对技术最本能的信仰,他有一点热血、有一点煽情。
我们想要以世界级的大模型,贡献于中国创新。给行业一个可用的、底层基础扎实的通用模型,能让更多人快速训练出专业大模型,实现产业集群的生态打造。
第二,TigerBot接下来还会继续保持高速迭代,陈烨认为在这种赛跑的局面下,他们能保持身位优势。即便是看到有人以TigerBot为底层开发出了性能更好的产品,这对于行业内来说又何尝不是一件好事?
陈烨透露,接下来虎博科技还会持续快速推进TigerBot的工作,进一步扩充数据来提升模型性能。
“大模型趋势就像淘金热”
在ChatGPT发布6个月以后,随着一个个大模型横空出世、一家家巨头火速跟进,AI行业格局正在被快速重塑。
尽管当下还相对混沌,但大致来看,基本上会分为模型层、中间层、应用层三层。
其中模型层决定底层能力,至关重要。
它的创新程度、稳定程度、开放程度,直接决定了应用层的丰富程度。
而应用层的发展是大模型趋势演进的外化体现;更是AIGC愿景里,人类社会生活走向下一阶段的重要影响因素。
那么,在大模型趋势的起点,如何夯实底层模型基础,是行业内必须思考的事。
在陈烨看来,目前人类才只开发了大模型10-20%的潜力,在fundamental层面还有非常大的创新和提升空间。
就好像曾经的西部淘金热,最初要找到金矿在哪里一样。
所以在这样的趋势和行业发展要求下,虎博科技作为国产领域创新代表,高举开源大旗,迅速起跑、追赶世界最前沿技术,确实也为行业内带来了一股与众不同的气息。
国产AI创新正在高速狂奔,未来一段时间内,相信我们还会看到更多有想法、有能力的团队亮相,为大模型领域注入新的见解、带来新的改变。
而这,或许就是趋势轰轰烈烈演进过程中,最迷人之处了。
福利时刻:
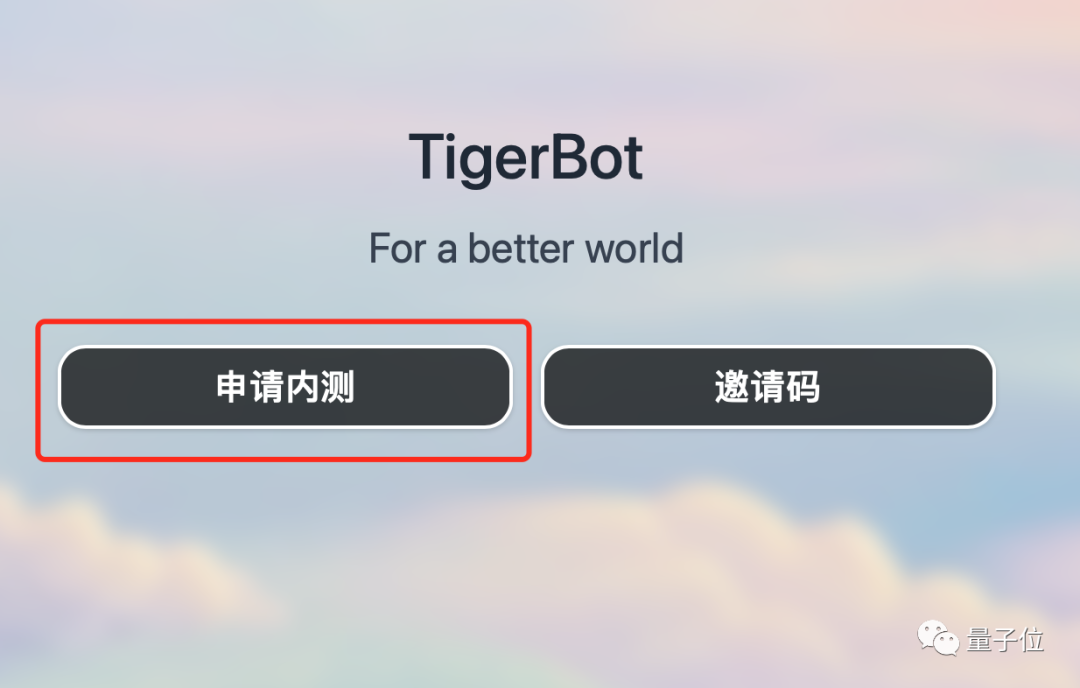
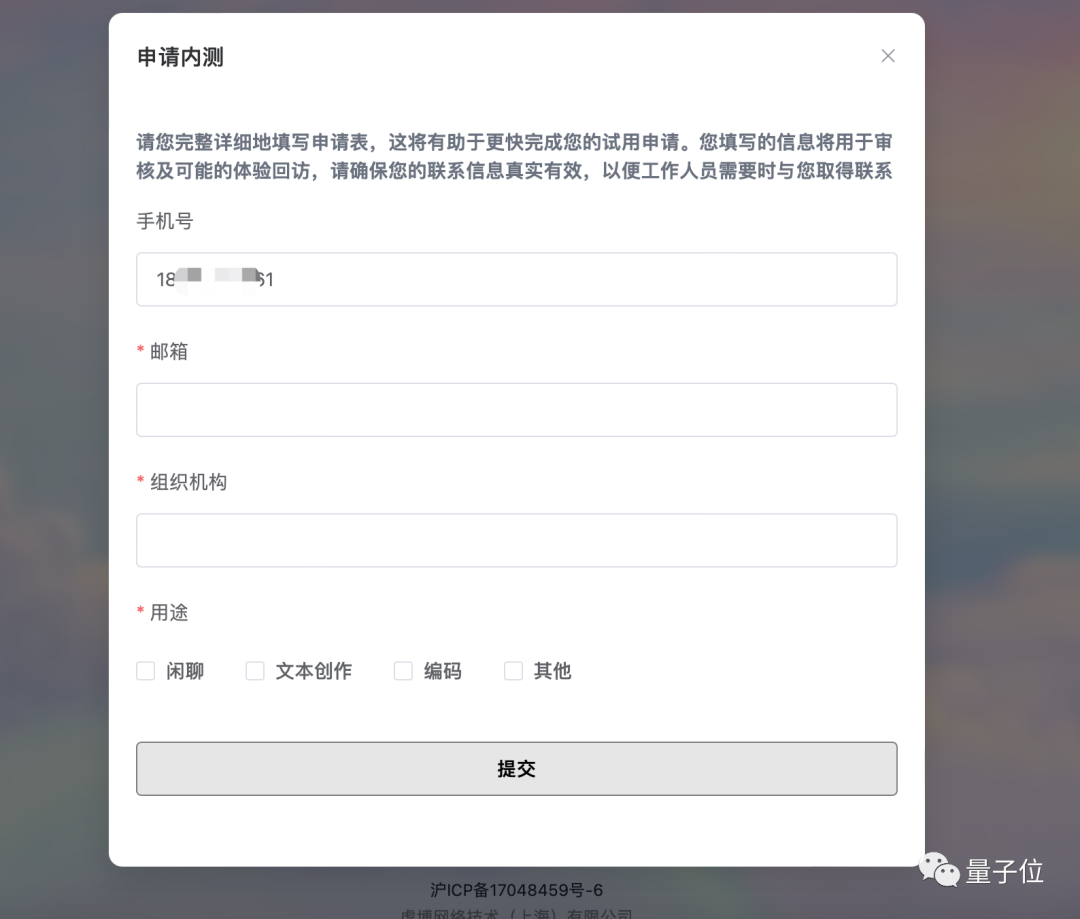
想体验TigerBot的童鞋,可以通过下方链接或点击“阅读原文”进入网站,点击“申请内测”,组织代码中写“量子位”即可通过内测~
官网地址:https://www.tigerbot.com/chat
GitHub开源地址:https://github.com/TigerResearch/TigerBot
以上就是效果达OpenAI同规模模型96%,发布即开源!国内团队新发大模型,CEO上阵写代码的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/528735.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


















