
针对海洋鱼类识别难的问题,本实践使用卷积神经网络(Convolutional Neural Network,CNN)构建深度学习模型,自动提取高质量的特征,并将训练好的模型贡献到PaddleHub,使用户只用1行代码即可实现调用,从而解决海洋鱼类识别的问题。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【PaddleHub模型贡献】一行代码实现海洋生物识别
海洋中的鱼类资源不仅有一定的食用价值,而且有很高的药用价值,近年来,世界各国对于海洋鱼类资源的重视程度与日俱增。在鱼类资源的开发利用中,必须对鱼类进行识别,从而了解其分布情况。但是由于鱼的种类繁多,形状大小相似,同时考虑到海底拍摄环境亮度低、场景模糊的实际情况,对鱼类资源的识别较为困难。
针对海洋鱼类识别难的问题,本实践使用卷积神经网络(Convolutional Neural Network,CNN)构建深度学习模型,自动提取高质量的特征,并将训练好的模型贡献到PaddleHub,使用户只用1行代码即可实现调用,从而解决海洋鱼类识别的问题。
接下来,让我们一起来学习如何使用百度深度学习框架飞桨来搭建卷积神经网络,实现海洋鱼类资源的识别。
一、实现原理
基础的卷积神经网络CNN由 卷积(convolution), 激活(activation)和 池化(pooling)三种结构组成。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,我们会把CNN输出的特征空间作为全连接层或全连接神经网络(fully connected neural network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNNs),比如VGG, ResNet都是由简单的CNN调整、组合而来。
1.卷积层
卷积层会对输入的特征图(或原始数据)进行卷积操作,输出卷积后产生的特征图。卷积层是卷积神经网络的核心部分。输入到卷积层的特征图是一个三维数据,不仅有宽、高两个维度,还有通道维度上的数据,因此输入特征图和卷积核可用三维特征图表示。如下图所示,对于一个(3,6,6)的输入特征图,卷积核大小为(3,3,3),输出大小为(1,4,4),当卷积核窗口滑过输入时,卷积核与窗口内的输入元素作乘加运算,并将结果保存到输出相应的位置。
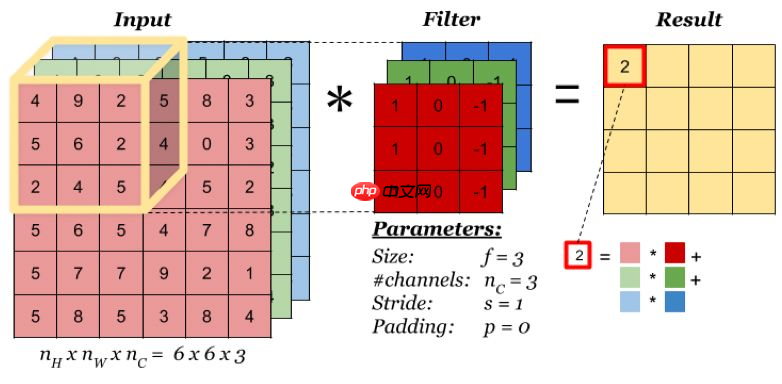
上图中卷积操作输出了一张特征图,即通道数为1的特征图,而一张特征图包含的特征数太少,在大多数计算机视觉任务中是不够的,所以需要构造多张特征图,而输入特征图的通道数又与卷积核通道数相等,一个卷积核只能产生一张特征图,因此需要构造多个卷积核。在RGB彩色图像上使用多个卷积核进行多个不同特征的提取,示意图如下:
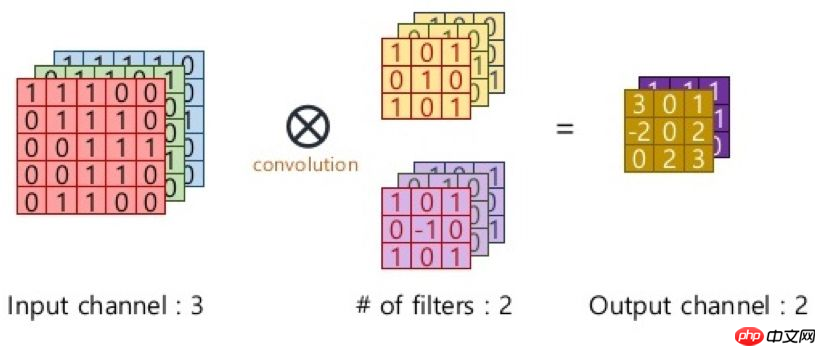
2.激活层
如果输入变化很小,导致输出结构发生截然不同的结果,这种情况是我们不希望看到的,为了模拟更细微的变化,输入和输出数值不只是0到1,可以是0和1之间的任何数,
激活函数是用来加入非线性因素的,因为线性模型的表达力不够,所以激活层的作用可以理解为把卷积层的结果做非线性映射。
我们知道在神经网络中,对于图像,我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
这里有一些小技巧:
一般不要用sigmoid,首先试RELU,因为快,但要小心点,如果RELU失效,请用Leaky ReLU,某些情况下tanh倒是有不错的结果。
3.池化层
池化层的作用是对网络中的特征进行选择,降低特征数量,从而减少参数数量和计算开销。池化层降低了特征维的宽度和高度,也能起到防止过拟合的作用。最常见的池化操作为最大池化或平均池化。如下图所示,采用了最大池化操作,对邻域内特征点取最大值作为最后的特征值。
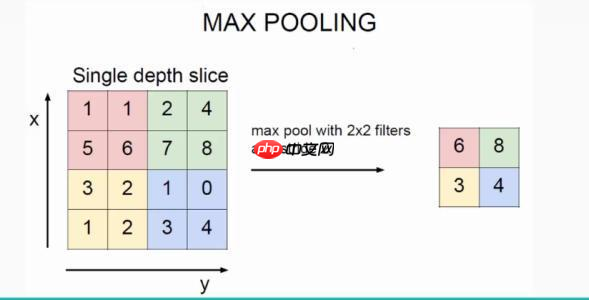
最常见的池化层使用大小为2×2,步长为2的滑窗操作,有时窗口尺寸为3,更大的窗口尺寸比较罕见,因为过大的滑窗会急剧减少特征的数量,造成过多的信息损失。
需要注意的是:池化层没有参数、池化层没有参数、池化层没有参数
4.批归一化层
批归一化层是由Google的DeepMind团队提出的在深度网络各层之间进行数据批量归一化的算法,以解决深度神经网络内部协方差偏移问题,使用网络训练过程中各层梯度的变化趋于稳定,并使网络在训练时能更快地收敛。
二、数据集简介
本次实践所使用的是fish4knowledge公开数据集。该数据集是台湾电力公司、台湾海洋研究所和ken丁国家公园在2010年10月1日至2013年9月30日期间,在台湾南湾海峡、兰屿岛和胡比湖的水下观景台收集的鱼类图像数据集,包括23类鱼种,共27370张鱼的图像。
该数据集已上传至AI Studio:https://aistudio.baidu.com/aistudio/datasetdetail/75102

23个类别分别是:
Dascyllus reticulatus 网纹宅泥鱼
Plectroglyphidodon dickii 迪克氏固曲齿鲷
Chromis chrysura 长棘光鳃鱼
Amphiprion clarkia 双带小丑鱼
Chaetodon lunulatus 弓月蝴蝶鱼
Chaetodon trifascialis 川纹蝴蝶鱼
Myripristis kuntee 康德锯鳞鱼
Acanthurus nigrofuscus 双斑刺尾鱼
Hemigymnus fasciatus 横带粗唇鱼
Neoniphon samara 莎姆金鳞鱼
Abudefduf vaigiensis 五带豆娘鱼
Canthigaster valentine 黑马鞍鲀鱼
Pomacentrus moluccensis 摩鹿加雀鲷
Zebrasoma scopas 黑三角倒吊鱼
Hemigymnus melapterus 黑鳍粗唇鱼
Lutjanus fulvus 黄足笛鲷
Scolopsis bilineata 双线眶棘鲈
Scaridae 鹦嘴鱼
Pempheris vanicolensis 黑缘单鳍鱼
Zanclus cornutus 镰鱼
Ncoglyphidodon nigroris 黑嘴雀鱼
Balistapus undulates 黄纹炮弹鱼
Siganus fuscescens 褐蓝子鱼
解压数据集:
In [ ]
!unzip data/data75102/fish_image.zip -d /home/aistudio/
三、模型开发
本项目基于PaddleX开发,使用ResNet50_vd_ssld。
安装PaddleX:
In [ ]
!pip install paddlex
1.划分数据集
按训练集:验证集:测试集=7:2:1的比例划分
In [ ]
!paddlex --split_dataset --format ImageNet --dataset_dir '/home/aistudio/fish_image' --val_value 0.2 --test_value 0.1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import impDataset Split Done.Train samples: 19150Eval samples: 5454Test samples: 2720Split files saved in /home/aistudio/fish_image
2.数据预处理
导入必要的资源库:
In [ ]
import matplotlibmatplotlib.use('Agg') import osos.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddlex as pdx
图像归一化并对训练集做数据增强:
In [ ]
from paddlex.cls import transformstrain_transforms = transforms.Compose([ transforms.RandomCrop(crop_size=224), transforms.RandomHorizontalFlip(), transforms.Normalize()])eval_transforms = transforms.Compose([ transforms.ResizeByShort(short_size=256), transforms.CenterCrop(crop_size=224), transforms.Normalize()])
定义数据迭代器:
In [ ]
train_dataset = pdx.datasets.ImageNet( data_dir='fish_image', file_list='fish_image/train_list.txt', label_list='fish_image/labels.txt', transforms=train_transforms, shuffle=True)eval_dataset = pdx.datasets.ImageNet( data_dir='fish_image', file_list='fish_image/val_list.txt', label_list='fish_image/labels.txt', transforms=eval_transforms)
2021-03-17 11:30:53 [INFO]Starting to read file list from dataset...2021-03-17 11:30:54 [INFO]19150 samples in file fish_image/train_list.txt2021-03-17 11:30:54 [INFO]Starting to read file list from dataset...2021-03-17 11:30:54 [INFO]5454 samples in file fish_image/val_list.txt
3.模型训练
如果使用的是普通版环境,请把train_batch_size调小至32-,否则会内存溢出。
In [ ]
num_classes = len(train_dataset.labels)model = pdx.cls.ResNet50_vd_ssld(num_classes=num_classes)model.train(num_epochs = 10, save_interval_epochs = 2, train_dataset = train_dataset, train_batch_size = 256, eval_dataset = eval_dataset, learning_rate = 0.025, warmup_steps = 128, warmup_start_lr = 0.0001, lr_decay_epochs=[2, 4, 8], lr_decay_gamma = 0.025, save_dir='/home/aistudio/output', use_vdl=True)
2021-03-17 11:45:52 [INFO][TRAIN] Epoch=10/10, Step=60/74, loss=0.17589, acc1=0.949219, acc5=0.996094, lr=0.0, time_each_step=0.86s, eta=0:0:402021-03-17 11:45:54 [INFO][TRAIN] Epoch=10/10, Step=62/74, loss=0.127886, acc1=0.960938, acc5=0.992188, lr=0.0, time_each_step=0.86s, eta=0:0:382021-03-17 11:45:55 [INFO][TRAIN] Epoch=10/10, Step=64/74, loss=0.203243, acc1=0.9375, acc5=0.996094, lr=0.0, time_each_step=0.86s, eta=0:0:362021-03-17 11:45:57 [INFO][TRAIN] Epoch=10/10, Step=66/74, loss=0.22026, acc1=0.929688, acc5=0.992188, lr=0.0, time_each_step=0.84s, eta=0:0:342021-03-17 11:45:59 [INFO][TRAIN] Epoch=10/10, Step=68/74, loss=0.164074, acc1=0.953125, acc5=0.988281, lr=0.0, time_each_step=0.83s, eta=0:0:332021-03-17 11:46:00 [INFO][TRAIN] Epoch=10/10, Step=70/74, loss=0.135595, acc1=0.957031, acc5=0.992188, lr=0.0, time_each_step=0.82s, eta=0:0:312021-03-17 11:46:02 [INFO][TRAIN] Epoch=10/10, Step=72/74, loss=0.161868, acc1=0.957031, acc5=1.0, lr=0.0, time_each_step=0.81s, eta=0:0:292021-03-17 11:46:03 [INFO][TRAIN] Epoch=10/10, Step=74/74, loss=0.196277, acc1=0.945312, acc5=0.984375, lr=0.0, time_each_step=0.81s, eta=0:0:282021-03-17 11:46:03 [INFO][TRAIN] Epoch 10 finished, loss=0.157934, acc1=0.955236, acc5=0.991976, lr=0.0 .2021-03-17 11:46:03 [INFO]Start to evaluating(total_samples=5454, total_steps=22)...100%|██████████| 22/22 [00:24<00:00, 1.12s/it]2021-03-17 11:46:28 [INFO][EVAL] Finished, Epoch=10, acc1=0.979465, acc5=0.994499 .
4.查看模型预测效果
In [ ]
import cv2import matplotlib.pyplot as plt# 加载模型print('**************************************加载模型*****************************************')model = pdx.load_model('output/best_model')# 显示图片img = cv2.imread('fish_image/Plectroglyphidodon_dickii/fish_000013120001_01106.png')b,g,r = cv2.split(img)img = cv2.merge([r,g,b])%matplotlib inlineplt.imshow(img)# 预测result = model.predict('fish_image/Plectroglyphidodon_dickii/fish_000013120001_01106.png', topk=3)print('**************************************预测*****************************************')print(result[0])
**************************************加载模型*****************************************2021-03-17 11:48:49 [INFO]Model[ResNet50_vd_ssld] loaded.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
**************************************预测*****************************************
{'category_id': 16, 'category': 'Plectroglyphidodon_dickii', 'score': 0.9853951}
四、将模型封装成PaddleHub的Module
1.导出inference模型
在这里我们需要将PaddleX训练得到的模型转换成可预测部署的模型
–model_dirinference模型所在的文件地址,文件包括:.pdparams、.pdopt、.pdmodel、.json和.yml–save_dir导出inference模型,文件将包括:__model__、__params__和model.ymlIn [ ]
!paddlex --export_inference --model_dir=output/best_model --save_dir=./inference_model/ResNet50_vd_ssld
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import impW0317 11:51:36.167836 3057 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0317 11:51:36.172704 3057 device_context.cc:372] device: 0, cuDNN Version: 7.6.2021-03-17 11:51:41 [INFO]Model[ResNet50_vd_ssld] loaded.2021-03-17 11:51:42 [INFO]Model for inference deploy saved in ./inference_model/ResNet50_vd_ssld.
2.模型转换
PaddleX模型可以快速转换成PaddleHub模型,只需要用下面这一句命令即可:
In [ ]
!hub convert --model_dir inference_model/ResNet50_vd_ssld --module_name MarineBiometrics --module_version 1.0.0 --output_dir outputs
转换成功后的模型保存在outputs文件夹下,我们解压一下:
In [ ]
!gzip -dfq /home/aistudio/outputs/MarineBiometrics.tar.gz!tar -xf /home/aistudio/outputs/MarineBiometrics.tar
五、模型预测
安装我们刚刚转换好的Module:
In [ ]
# 安装Module!hub install MarineBiometrics
In [ ]
# 查看该Module的基本信息!hub show MarineBiometrics
+---------------+----------------------------------------+| ModuleName |MarineBiometrics |+---------------+----------------------------------------+| Version |1.0.0 |+---------------+----------------------------------------+| Summary |The model uses convolution neural networ|| |k to tell you the key to identify marine|| | fish, so that anyone can call out the n|| |ames of the creatures. |+---------------+----------------------------------------+| Author |郑博培、彭兆帅 |+---------------+----------------------------------------+| Author-Email |2733821739@qq.com, 1084667371@qq.com |+---------------+----------------------------------------+| Location |MarineBiometrics |+---------------+----------------------------------------+
1.通过API的方式调用
预测单张图片:
 In [ ]
In [ ]
import cv2import paddlehub as hubmodule = hub.Module(name="MarineBiometrics")images = [cv2.imread('fish_image/Plectroglyphidodon_dickii/fish_000013120001_01102.png')]# execute predict and print the resultresults = module.predict(images=images)for result in results: print(result)
[2021-03-17 12:04:55,311] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
[{'category_id': 16, 'category': 'Plectroglyphidodon_dickii', 'score': 0.9932127}]
2.将模型部署至服务器
下面,我们只需要使用hub serving命令即可完成模型的一键部署,对此命令的说明如下:
$ hub serving start --modules/-m [Module1==Version1, Module2==Version2, ...] --port/-p XXXX -config/-c XXXX
modules/-m PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出。当不指定Version时,默认选择最新版本port/-p 服务端口,默认为8866config/-c 使用配置文件配置模型
因此,我们仅需要一行代码即可完成模型的部署,如下(注:AIStudio上要再终端运行):
$ hub serving start -m MarineBiometrics
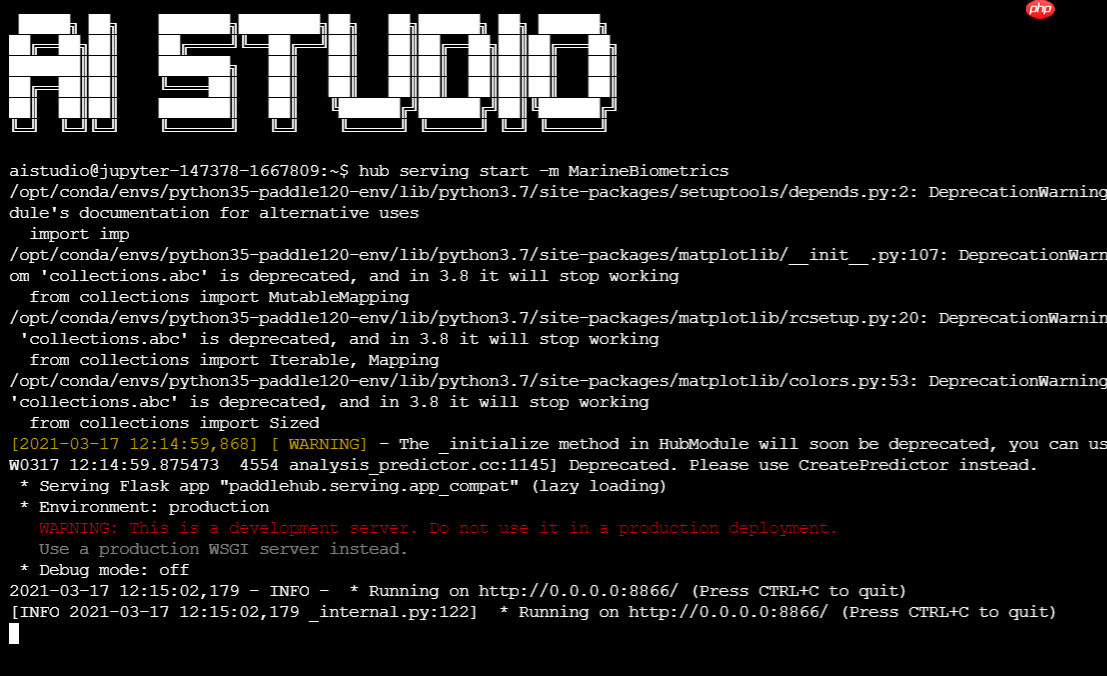
等待模型加载后,此预训练模型就已经部署在机器上了。
在模型安装的同时,会生成一个客户端请求示例,存放在模型安装目录,默认为${HUB_HOME}/.paddlehub/modules,对于此例,我们可以在~/.paddlehub/modules/MarineBiometrics找到此客户端示例serving_client_demo.py,代码如下:
输入多张图片:

 In [24]
In [24]
# coding: utf8import requestsimport jsonimport cv2import base64def cv2_to_base64(image): data = cv2.imencode('.jpg', image)[1] return base64.b64encode(data.tostring()).decode('utf8')if __name__ == '__main__': # 获取图片的base64编码格式 img1 = cv2_to_base64(cv2.imread("fish_image/Lutjanus_fulvus/fish_000010519594_03501.png")) img2 = cv2_to_base64(cv2.imread("fish_image/Chromis_chrysura/fish_000013160001_01168.png")) data = {'images': [img1, img2]} # 指定content-type headers = {"Content-type": "application/json"} # 发送HTTP请求 url = "http://127.0.0.1:8866/predict/MarineBiometrics" r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 打印预测结果 print(r.json()["results"])
[[{'category': 'Lutjanus_fulvus', 'category_id': 11, 'score': 0.9962420463562012}], [{'category': 'Chromis_chrysura', 'category_id': 7, 'score': 0.9983481168746948}]]
六、总结与升华
全世界大约有两千万以观察海洋生物为目的的潜水者。在每次潜水结束后,大家谈论的主要话题总是观察到的动植物。但是像“刚才看见的那个叫什么?”这样的问题,答案总是无人知晓。因为在看到生物的那一刻,我们手边没有合适的工具帮助鉴别,而我们也没有扎实的生物和分类学知识基础。为弥补这一遗憾,海洋生物识别这一模型就应运而生了。
个人简介
北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
百度飞桨开发者技术专家 PPDE
百度飞桨官方帮帮团、答疑团成员
深圳柴火创客空间 认证会员
百度大脑 智能对话训练师
阿里云人工智能、DevOps助理工程师
我在AI Studio上获得至尊等级,点亮9个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378

以上就是【PaddleHub模型贡献】一行代码实现海洋生物识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/53869.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















