面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。
一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。
即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。
此外,MDL模型也可以优于单领域模型,在一个域上的额外训练,可以提高模型在另一个域上的性能,这称为「正向知识迁移」,但也可能产生负向知识转移,这取决于训练方法和具体的领域组合。 虽然以前关于MDL的工作已经证明了跨领域联合学习任务的有效性,但它涉及到一个手工制作的模型架构,应用于其他工作的效率很低。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/pdf/2010.04904.pdf
为了解决这个问题,在「Multi-path Neural Networks for On-device Multi-domain Visual Classification」一文中,谷歌研究人员提出了一个通用MDL模型。
文章表示,该模型既可以有效地实现高精确度,减少负向知识迁移的同时,学习增强正向的知识迁移,在处理各种特定领域的困难时,可以有效地优化联合模型。
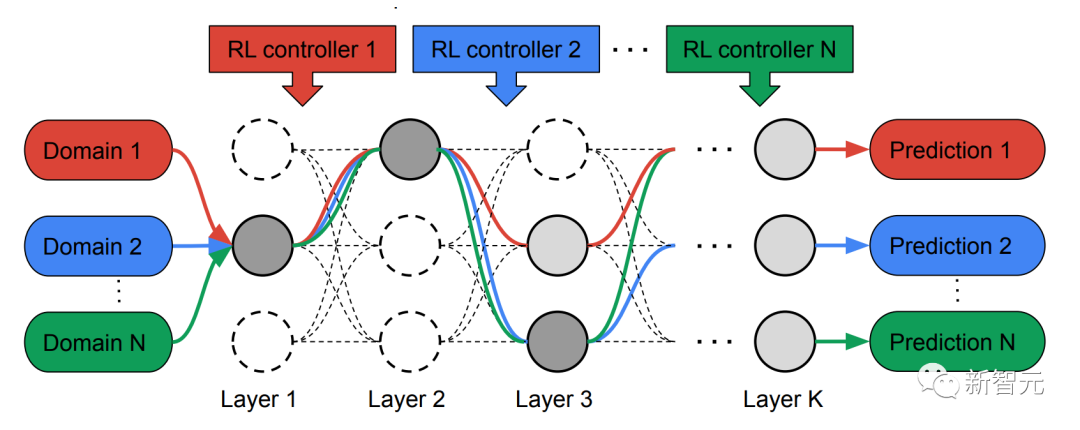
为此,研究人员提出了一种多路径神经架构搜索(MPNAS)方法,为多领域建立一个具有异质网络架构的统一模型。
该方法将高效的神经结构搜索(NAS)方法从单路径搜索扩展到多路径搜索,为每个领域联合寻找一条最优路径。同时引入一个新的损失函数,称为自适应平衡域优先化(ABDP),它适应特定领域的困难,以帮助有效地训练模型。由此产生的MPNAS方法是高效和可扩展的。
新模型在保持性能不下降的同时,与单领域方法相比,模型大小和FLOPS分别减少了78%和32%。
多路径神经结构搜索
为了促进正向知识迁移,避免负向迁移,传统的解决方案是,建立一个MDL模型,使各域共享大部分的层,学习各域的共享特征(称为特征提取),然后在上面建一些特定域的层。 然而,这种特征提取方法无法处理具有明显不同特征的域(如自然图像中的物体和艺术绘画)。另一方面,为每个MDL模型建立统一的异质结构是很耗时的,而且需要特定领域的知识。
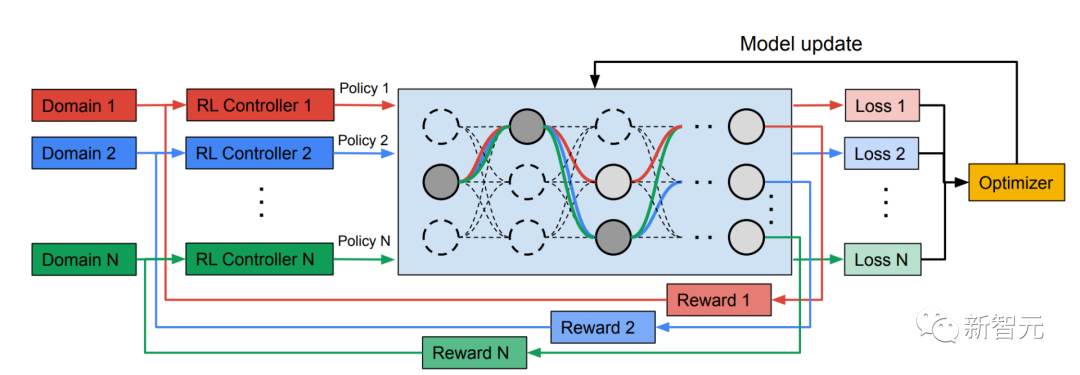
多路径神经搜索架构框架 NAS是一个自动设计深度学习架构的强大范式。它定义了一个搜索空间,由可能成为最终模型一部分的各种潜在构建块组成。
搜索算法从搜索空间中找到最佳的候选架构,以优化模型目标,例如分类精度。最近的NAS方法(如TuNAS)通过使用端到端的路径采样,提高了搜索效率。
受TuNAS的启发,MPNAS在两个阶段建立了MDL模型架构:搜索和训练。
在搜索阶段,为了给每个领域共同找到一条最佳路径,MPNAS为每个领域创建了一个单独的强化学习(RL)控制器,它从超级网络(即由搜索空间定义的候选节点之间所有可能的子网络的超集)中采样端到端的路径(从输入层到输出层)。
在多次迭代中,所有RL控制器更新路径,以优化所有领域的RL奖励。在搜索阶段结束时,我们为每个领域获得一个子网络。 最后,所有的子网络被结合起来,为MDL模型建立一个异质结构,如下图所示。
 奇域
奇域
奇域是一个专注于中式美学的国风AI绘画创作平台
 30 查看详情
30 查看详情 
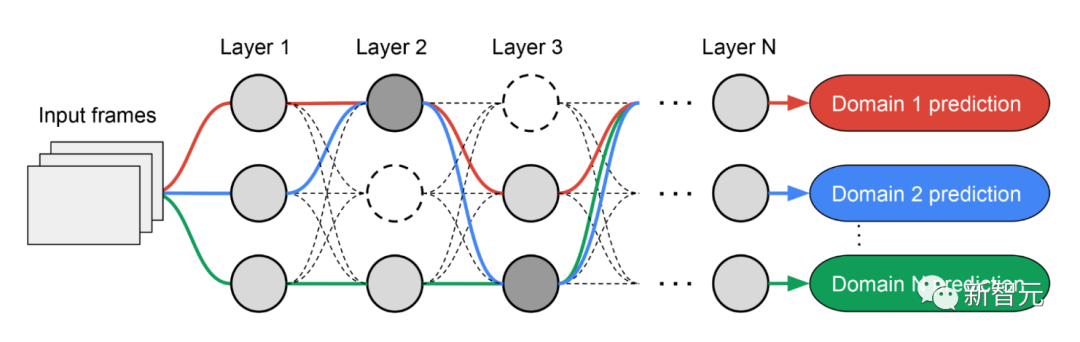
由于每个域的子网络是独立搜索的,所以每一层的构件可以被多个域共享(即深灰色节点),被单个域使用(即浅灰色节点),或者不被任何子网络使用(即点状节点)。
每个域的路径在搜索过程中也可以跳过任何一层。鉴于子网络可以以优化性能的方式自由选择沿路使用的区块,输出网络既是异质的又是高效的。
下图展示了Visual Domain Decathlon的其中两个领域的搜索架构。
Visual Domain Decathlon是CVPR 2017中的PASCAL in Detail Workshop Challenge的一部分,测试了视觉识别算法处理(或利用)许多不同视觉领域的能力。 可以看出,这两个高度相关的域(一个红色,另一个绿色)的子网,从它们的重叠路径中共享了大部分构建块,但它们之间仍然存在差异。
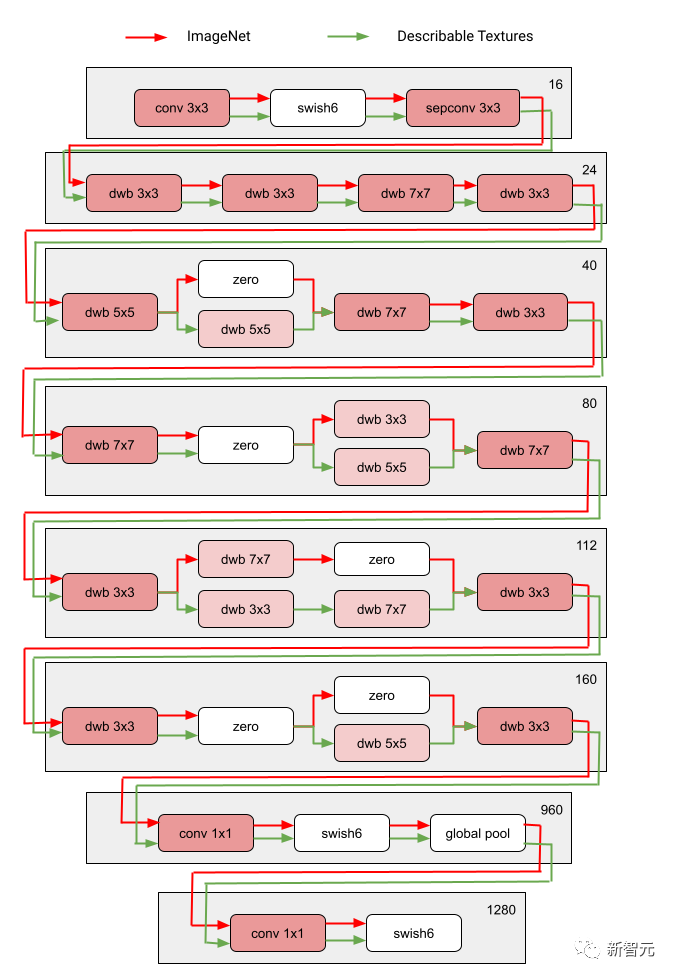
图中红色和绿色路径分别代表 ImageNet 和Describable Textures的子网络,深粉色节点代表多个域共享的块,浅粉色节点代表每条路径使用的块。图中的“dwb”块代表 dwbottleneck 块。图中的Zero块表示子网跳过该块 下图展示了上文提到的两个领域的路径相似性。 相似度通过每个域的子网之间的Jaccard相似度得分来衡量,其中越高意味着路径越相似。

图为十个域的路径之间的Jaccard相似度得分的混淆矩阵。分值范围为0到1,分值越大表示两条路径共享的节点越多。
训练异构多域模型
在第二阶段,MPNAS 产生的模型将针对所有领域从头开始训练。 为此,有必要为所有领域定义一个统一的目标函数。 为了成功处理各种各样的领域,研究人员设计了一种算法,该算法在整个学习过程中进行调整,以便在各个领域之间平衡损失,称为自适应平衡领域优先级 (ABDP)。 下面展示了在不同设置下训练的模型的准确率、模型大小和FLOPS。我们将MPNAS与其他三种方法进行比较:
独立于域的 NAS:分别为每个域搜索和训练模型。
单路径多头:使用预训练模型作为所有域的共享主干,每个域都有单独的分类头。
多头 NAS:为所有域搜索统一的骨干架构,每个域都有单独的分类头。
从结果中,我们可以观察到NAS需要为每个域构建一组模型,从而导致模型很大。 尽管单路径多头和多头NAS可以显着降低模型大小和FLOPS,但强制域共享相同的主干会引入负面的知识转移,从而降低整体准确性。

相比之下,MPNAS可以构建小而高效的模型,同时仍保持较高的整体精度。 MPNAS的平均准确率甚至比领域独立的NAS方法高1.9%,因为该模型能够实现积极的知识转移。 下图比较了这些方法的每个域top-1准确度。
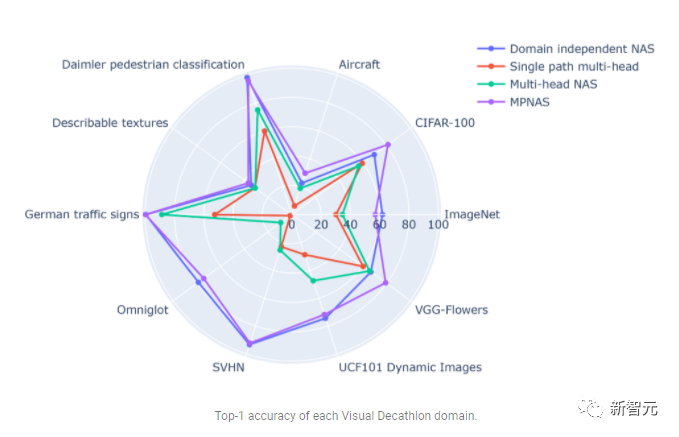
评估表明,通过使用 ABDP 作为搜索和训练阶段的一部分,top-1 的准确率从 69.96% 提高到 71.78%(增量:+1.81%)。
未来方向
MPNAS是构建异构网络以解决MDL中可能的参数共享策略的数据不平衡、域多样性、负迁移、域可扩展性和大搜索空间的有效解决方案。 通过使用类似MobileNet的搜索空间,生成的模型也对移动设备友好。 对于与现有搜索算法不兼容的任务,研究人员正继续扩展MPNAS用于多任务学习,并希望用MPNAS来构建统一的多域模型。
以上就是多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/540172.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫