今天我在给大家分享一个 OCR 应用——ddddocr自动识别验证码。
前面 4 个d是“带带弟弟”的首拼音。[/笑哭]。
项目地址:https://github.com/sml2h3/ddddocr。
使用的时候用pip命令直接安装即可pip install ddddocr。
OCR的核心技术包含两方面,一是目标检测模型检测图片中的文字,二是文字识别模型,将图片中的文字转成文本文字。
第一类验证码最简单,它们没有复杂的背景图片,所以目标检测模型可以省略,直接将图片送入文字识别模型即可。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

识别代码如下:
import ddddocr
from PIL import Image
# 模型
ocr = ddddocr.DdddOcr(beta=True)
# 验证码图片
with open('test.jpg', 'rb') as f:
image = f.read()
res = ocr.classification(image)
# 验证码文字内容
print(res)
第二类验证码有复杂的背景,需要先用目标检测模型框出文字,在进行识别。
 码上飞
码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 138 查看详情
138 查看详情 

代码如下:
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("test2.jpg", 'rb') as f:
image = f.read()
# 目标检测
poses = det.detection(image)
print(poses)
im = cv2.imread("test2.jpg")
# 遍历检测出的文字
for box in poses:
x1, y1, x2, y2 = box
# 给每个文字画矩形框
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
输出结果如下:
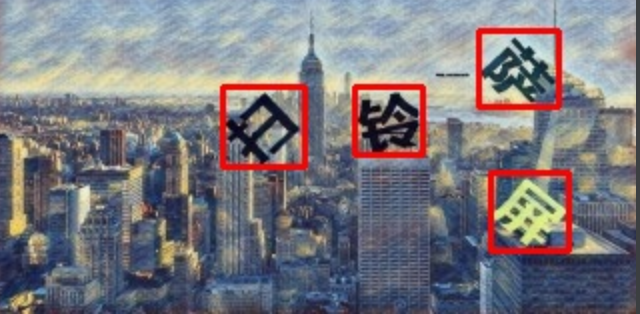
可以看到文字部分已经被框出来了,如果我们在上述代码直接将im[y1:y2, x1:x2]送入文字识别模型,就可以识别出对应的文本内容了。
ddddocr还能识别下面这种带滑块的验证码。


这种虽然不属于OCR的业务范畴,但作为一个通用的验证码识别工具,作者还是支持了,必须给作者点个赞。
以上就是用OCR技术,自动识别各种验证码,工具已开源的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/545139.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫