
该项目针对公共场所吸烟问题,利用PaddleX训练吸烟检测模型,再通过EasyEdge部署到PC和手机APP。先从公开数据集获取按VOC格式标注的数据,经解压、处理清洗、划分后,用YOLOv3(MobileNetV3_large为backbone)训练,导出模型后上传至EasyEdge完成部署,实现吸烟行为的智能检测、警告与记录。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

公共场所吸烟检测与EasyEdge部署
公共场所进行吸烟检测,如果发现有吸烟行为,及时警告并记录。
项目背景
吸烟有害健康。
为减少和消除烟草烟雾危害,保障公众健康,根据国务院立法工作计划,2013年卫生计生委启动了《公共场所控制吸烟条例》起草工作。按照立法程序的有关要求,在总结地方控烟工作经验的基础上,深入调研,广泛征求了工业和信息化部、烟草局等25个部门,各省级卫生计生行政部门、部分行业协会及有关专家的意见,经不断修改完善,形成了《公共场所控制吸烟条例(送审稿)》。送审稿明确,所有室内公共场所一律禁止吸烟。此外,体育、健身场馆的室外观众坐席、赛场区域;公共交通工具的室外等候区域等也全面禁止吸烟。
但,仍存在公共场合吸烟问题,为此一种无人化、智能化吸烟检测装置的需求迫在眉睫。

一、项目介绍
该项目使用PaddleX快速训练吸烟模型,然后通过EasyEdge端与边缘AI服务平台部署到电脑PC与手机APP上,实现飞桨框架深度学习模型的落地。
模型训练:PaddleX,YoloV3的backbone使用MobileNetV3_large
模型落地:EasyEdge端与边缘AI服务平台 使用文档
PC效果展示: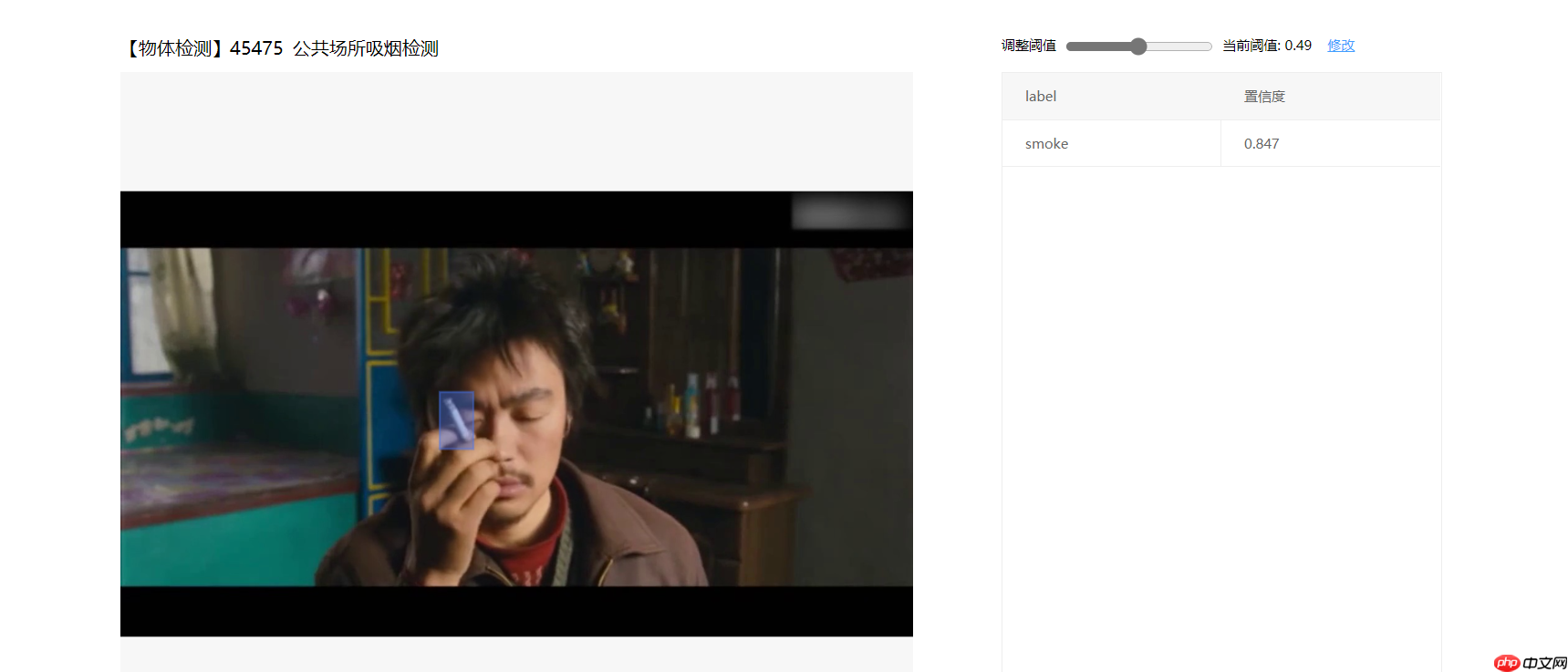
二、数据集简介
本次数据集从浆友公开数据集中获取。
具体链接为:https://aistudio.baidu.com/aistudio/datasetdetail/94796。
本项目为目标检测场景,所使用的吸烟检测数据集已经按VOC格式进行标注,目录情况如下:
dataset/ ├── annotations/ ├── images/
模型训练与导出
三、模块导入
PaddleX是飞桨提供的全流程开发工具。它集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,将智能视觉领域的四大任务:图像分类、目标检测、语义分割、实例分割的数据读取、数据增强、超参配置、训练评估等进行模块化抽象,并全流程打通,并提供简明易懂的Python API,方便用户根据实际生产需求进行直接调用或二次开发。 Paddlex版本:PaddleX 1.3.11 项目环境:Paddle 2.1.0
PaddleX项目地址:https://github.com/PaddlePaddle/PaddleX
PaddleX文档链接:https://paddlex.readthedocs.io
PaddleX可视化模型训练客户端下载:https://www.paddlepaddle.org.cn/paddle/paddlex
In [ ]
!pip install paddlex==1.3.11!pip install paddle2onnx
四、解压数据集
In [ ]
# 进行数据集解压!unzip -oq /home/aistudio/data/data102810/pp_smoke.zip -d /home/aistudio/dataset
五、数据处理和数据清洗
In [ ]
# 这里修改.xml文件中的元素!mkdir dataset/Annotations1 #创建目录 Annotations1import xml.dom.minidomimport ospath = r'dataset/Annotations' # xml文件存放路径sv_path = r'dataset/Annotations1' # 修改后的xml文件存放路径files = os.listdir(path)cnt = 1for xmlFile in files: dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) # 打开xml文件,送到dom解析 root = dom.documentElement # 得到文档元素对象 item = root.getElementsByTagName('path') # 获取path这一node名字及相关属性值 for i in item: i.firstChild.data = '/home/aistudio/dataset/JPEGImages/' + str(cnt).zfill(6) + '.jpg' # xml文件对应的图片路径 with open(os.path.join(sv_path, xmlFile), 'w') as fh: dom.writexml(fh) cnt += 1
In [ ]
# 这里修改.xml文件中的元素!mkdir dataset/Annotations2 #创建目录 Annotations2import xml.dom.minidomimport ospath = r'dataset/Annotations1' # xml文件存放路径sv_path = r'dataset/Annotations2' # 修改后的xml文件存放路径files = os.listdir(path)for xmlFile in files: dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) # 打开xml文件,送到dom解析 root = dom.documentElement # 得到文档元素对象 names = root.getElementsByTagName('filename') a, b = os.path.splitext(xmlFile) # 分离出文件名a for n in names: n.firstChild.data = a + '.jpg' with open(os.path.join(sv_path, xmlFile), 'w') as fh: dom.writexml(fh)
In [ ]
# 这里修改.xml文件中的元素!mkdir dataset/Annotations3 #创建目录 Annotations3#!/usr/bin/env python2# -*- coding: utf-8 -*- import osimport xml.etree.ElementTree as ET origin_ann_dir = '/home/aistudio/dataset/Annotations2/'# 设置原始标签路径为 Annosnew_ann_dir = '/home/aistudio/dataset/Annotations3/'# 设置新标签路径 Annotationsfor dirpaths, dirnames, filenames in os.walk(origin_ann_dir): # os.walk游走遍历目录名 for filename in filenames: # if os.path.isfile(r'%s%s' %(origin_ann_dir, filename)): # 获取原始xml文件绝对路径,isfile()检测是否为文件 isdir检测是否为目录 origin_ann_path = os.path.join(origin_ann_dir, filename) # 如果是,获取绝对路径(重复代码) new_ann_path = os.path.join(new_ann_dir, filename) tree = ET.parse(origin_ann_path) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析" root = tree.getroot() # 获取根节点 for object in root.findall('object'): # 找到根节点下所有“object”节点 name = str(object.find('name').text) # 找到object节点下name子节点的值(字符串) # 如果name等于str,则删除该节点 if (name in ["smoke"]): # root.remove(object) pass # 如果name等于str,则修改name else: object.find('name').text = "smoke" tree.write(new_ann_path)#tree为文件,write写入新的文件中。
In [ ]
#删除冗余文件并修改文件夹名字!rm -rf dataset/Annotations!rm -rf dataset/Annotations1!rm -rf dataset/Annotations2!mv dataset/Annotations3 dataset/Annotations!mv dataset/images dataset/JPEGImages
In [ ]
#在原始数据集中,存在.jpg文件和.xml文件匹配不对等的情况,这里我们根据.jpg文件名删除了在Annotations文件夹中无法匹配的.xml文件,#使得.jpg和.xml能够一一对应。import osimport shutilpath_annotations = 'dataset/Annotations'path_JPEGImage = 'dataset/JPEGImages'xml_path = os.listdir(path_annotations)jpg_path = os.listdir(path_JPEGImage)for i in jpg_path: a = i.split('.')[0] + '.xml' if a in xml_path: pass else: print(i) os.remove(os.path.join(path_JPEGImage,i))
In [ ]
#划分数据集#基于PaddleX 自带的划分数据集的命令,数据集中训练集、验证集、测试集的比例为7:2:1(最常用的户划分方式)。!paddlex --split_dataset --format VOC --dataset_dir /home/aistudio/dataset/ --val_value 0.2 --test_value 0.1
六、模型训练
配置GPU环境数据增强与数据预处理创建数据读取器配置模型进行训练In [ ]
#配置GPU环境import osos.environ['CUDA_VISIBLE_DEVICES'] = "0"from paddlex.det import transformsimport paddlex as pdxfrom paddlex.det import transforms# 数据增强与数据预处理# API说明https://gitee.com/paddlepaddle/PaddleX/blob/develop/docs/apis/transforms/det_transforms.mdtrain_transforms = transforms.Compose([ transforms.RandomHorizontalFlip(), transforms.Normalize(), transforms.ResizeByShort(short_size=512, max_size=512), transforms.Padding(coarsest_stride=32)])eval_transforms = transforms.Compose([ transforms.Normalize(), transforms.ResizeByShort(short_size=512, max_size=512), transforms.Padding(coarsest_stride=32),])# 定义训练和验证时的transforms# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/det_transforms.htmltrain_transforms = transforms.Compose([ transforms.MixupImage(mixup_epoch=350), transforms.RandomDistort(), transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize( target_size=608, interp='RANDOM'), transforms.RandomHorizontalFlip(), transforms.Normalize()])eval_transforms = transforms.Compose([ transforms.Resize( target_size=608, interp='CUBIC'), transforms.Normalize()])# 定义训练和验证所用的数据集# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-vocdetectiontrain_dataset = pdx.datasets.VOCDetection( data_dir='/home/aistudio/dataset', file_list='/home/aistudio/dataset/train_list.txt', label_list='/home/aistudio/dataset/labels.txt', transforms=train_transforms, parallel_method='thread', shuffle=True)eval_dataset = pdx.datasets.VOCDetection( data_dir='/home/aistudio/dataset', file_list='/home/aistudio/dataset/val_list.txt', label_list='/home/aistudio/dataset/labels.txt', parallel_method='thread', transforms=eval_transforms)# 初始化模型,并进行训练# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.htmlnum_classes = len(train_dataset.labels)# API说明: https://paddlex.readthedocs.io/zh_CN/release-1.3/apis/models/detection.html#paddlex-det-yolov3# 这里采用了yolov3移动版,用于后续部署APP,可以对应开发文档选用自己何时模型,从精度、速度、大小考虑。model = pdx.det.YOLOv3(num_classes=num_classes, backbone='MobileNetV3_large')# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#train# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.htmlmodel.train( num_epochs=300, train_dataset=train_dataset, train_batch_size=24, # 跟随老师讲说,这里基本把显存拉到了30GB 留有2GB余量 eval_dataset=eval_dataset, learning_rate=0.001 / 8, warmup_steps=1000, warmup_start_lr=0.0, save_interval_epochs=1, lr_decay_epochs=[240, 270], use_vdl= True, save_dir='output/yolov3_mobilenet')
In [8]
#可视化 !visualdl --logdir home/aistudio/output/yolov3_mobilenet/vdl_log --port 8001
七、模型评估
In [ ]
model.evaluate(eval_dataset, batch_size=1, epoch_id=None, return_details=False)
八、模型导出
In [ ]
#把模型导出,下载本地,然后上传到EasyEdge!paddlex --export_inference --model_dir=/home/aistudio/output/yolov3_mobilenet/best_model --save_dir=./down_model
模型部署
九、模型送到EasyEdge里面,部署APP与Window桌面应用
EasyEdge是基于百度飞桨轻量化推理框架Paddle Lite研发的端与边缘AI服务平台,能够帮助深度学习开发者将自建模型快速部署到设备端。只需上传模型,最快2分种即可获得适配终端硬件/芯片的模型。
#只需要把导出的模型分别对应上传到EasyEdge,labels.txt这个文件就是之前数据集里面的标签文件
【第一步】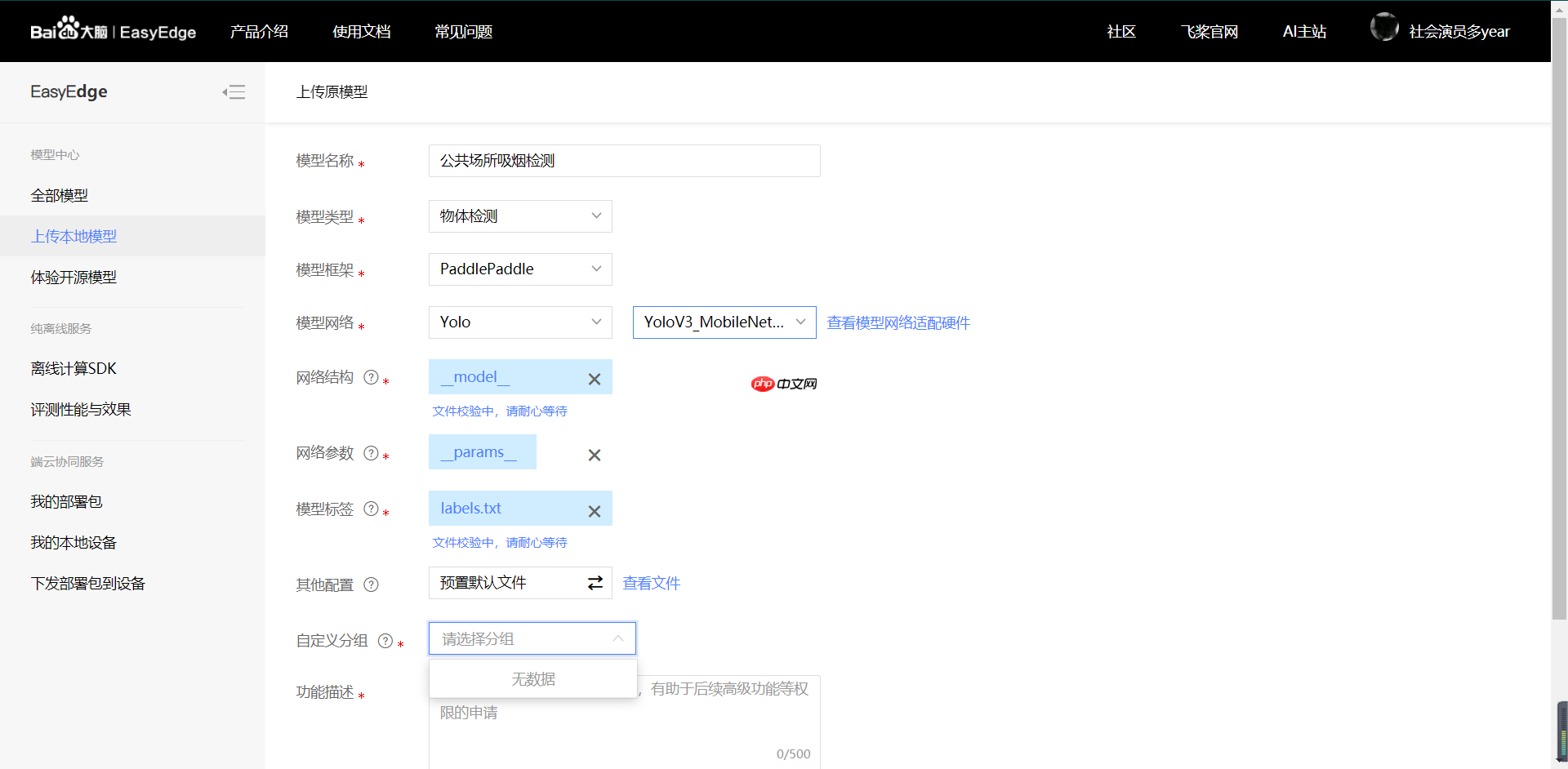
【第二步】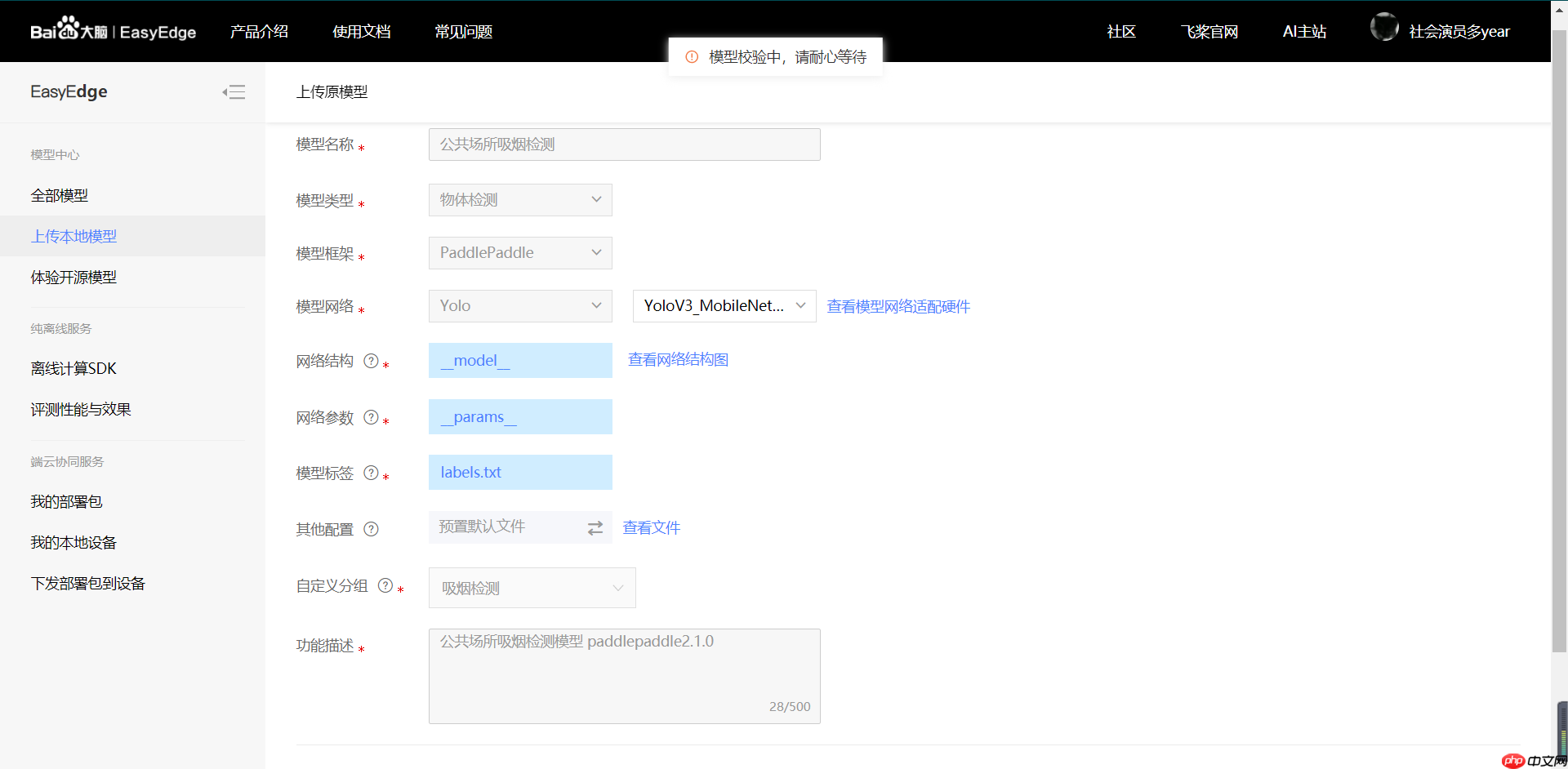
【第三步】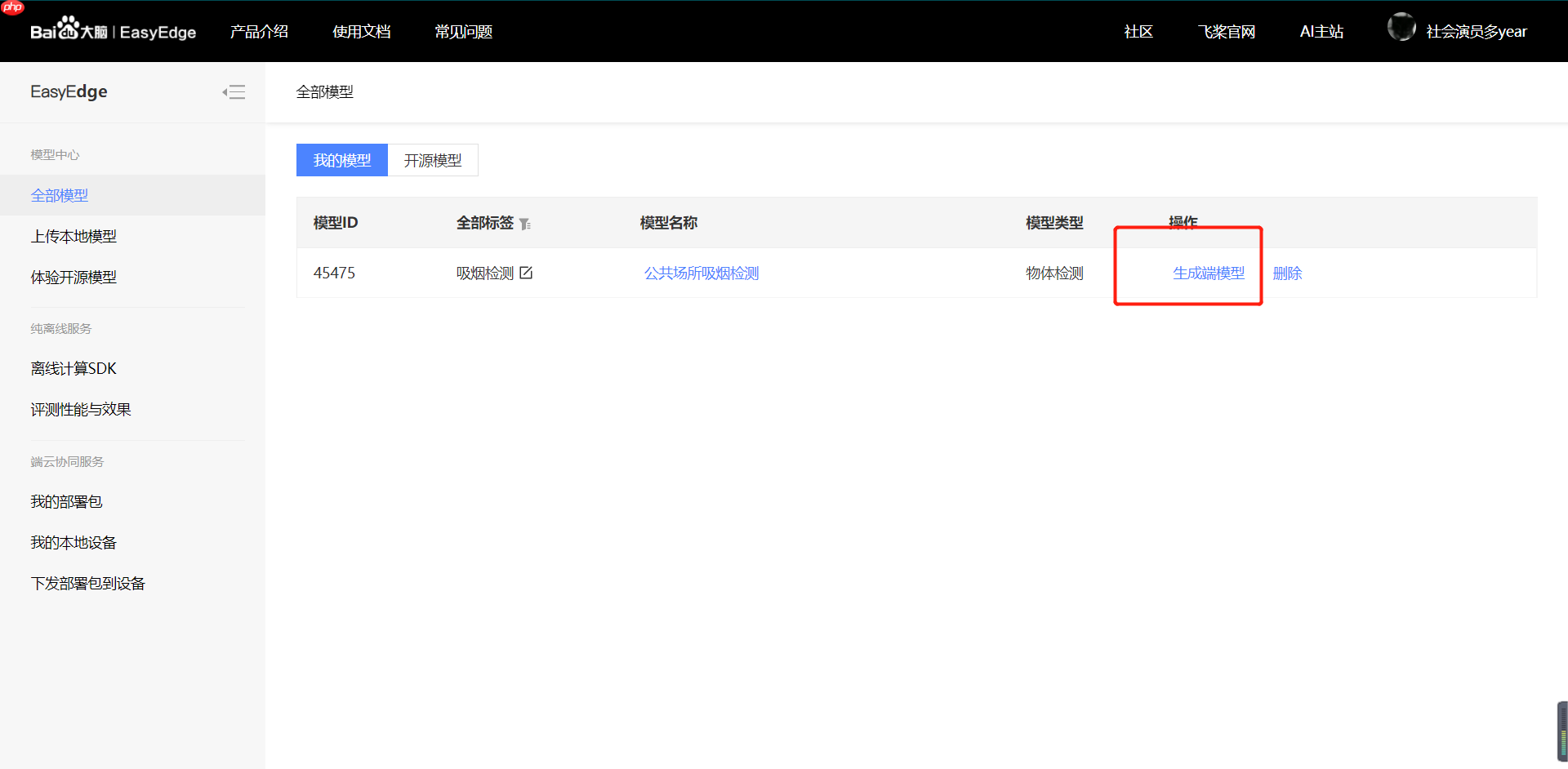
【第四步】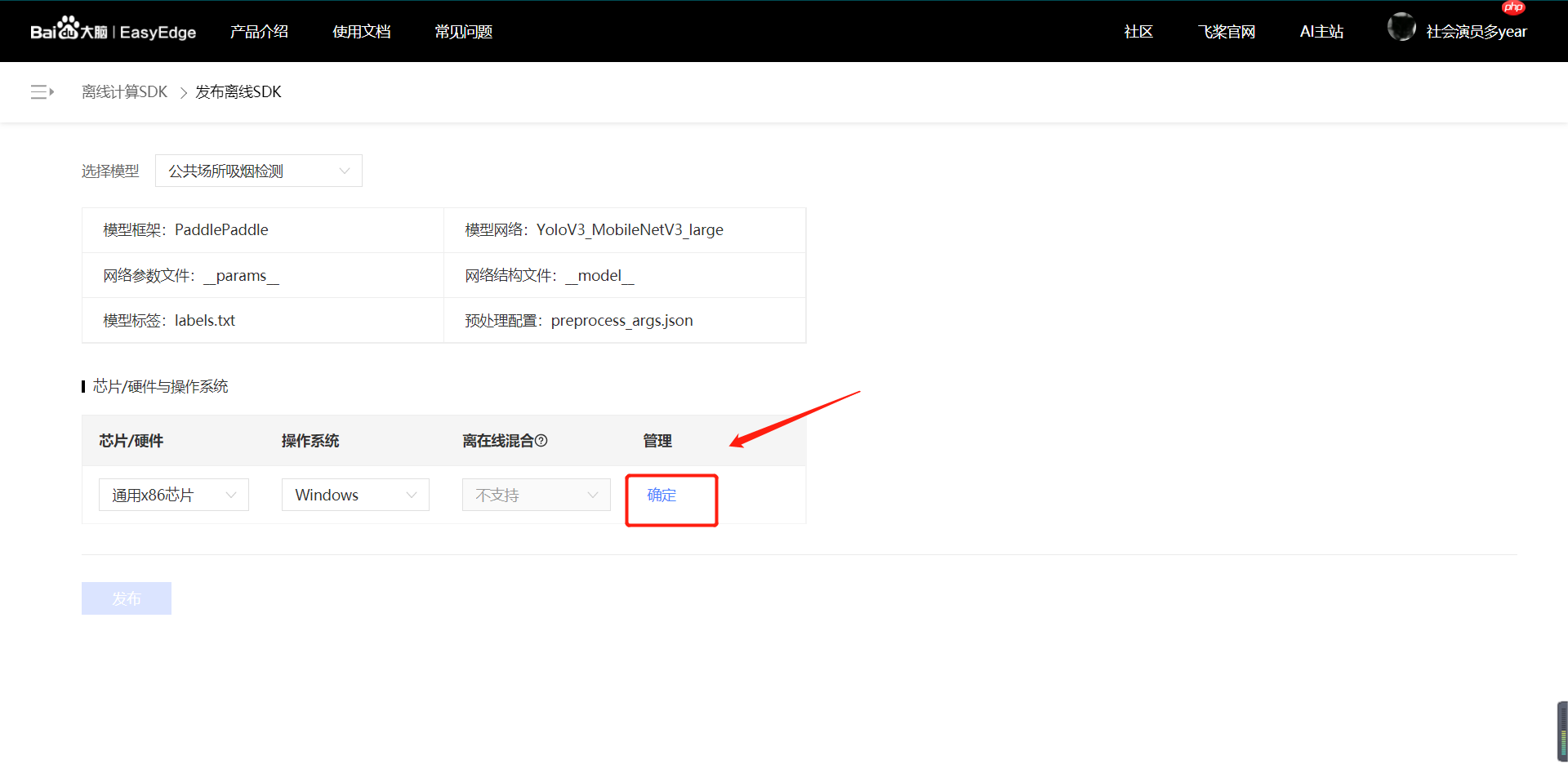
【第五步】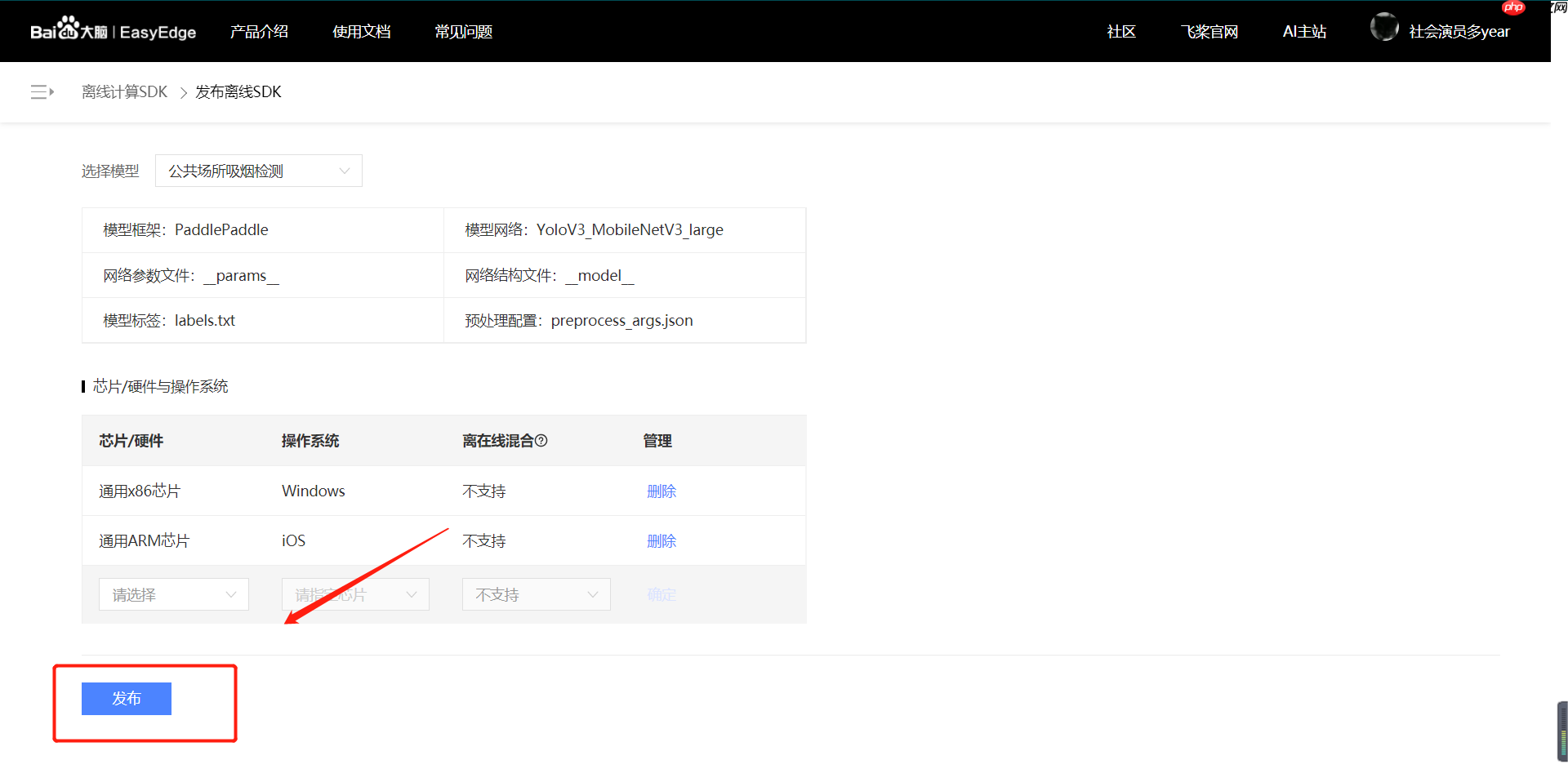
【第六步】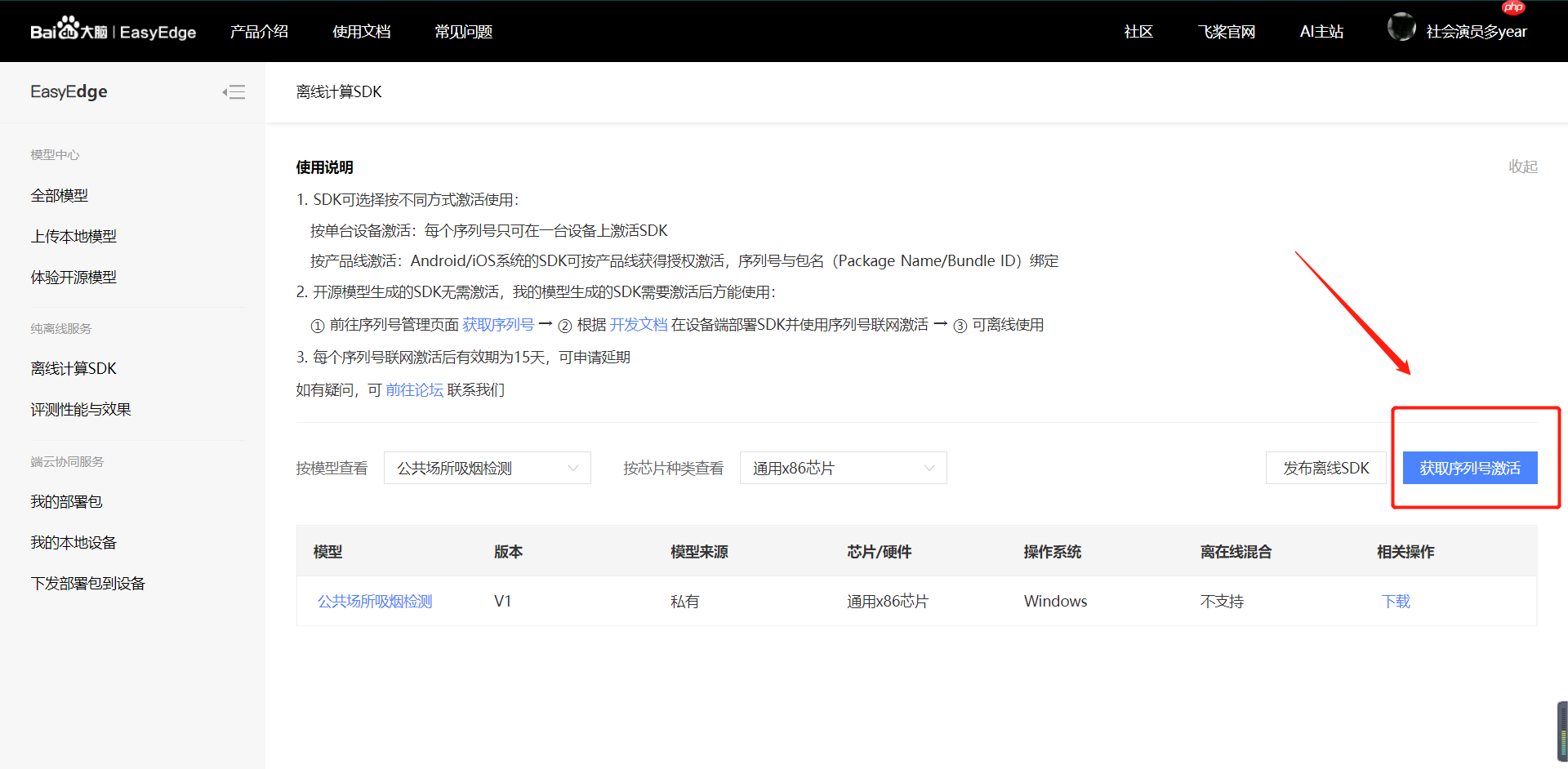
【第七步】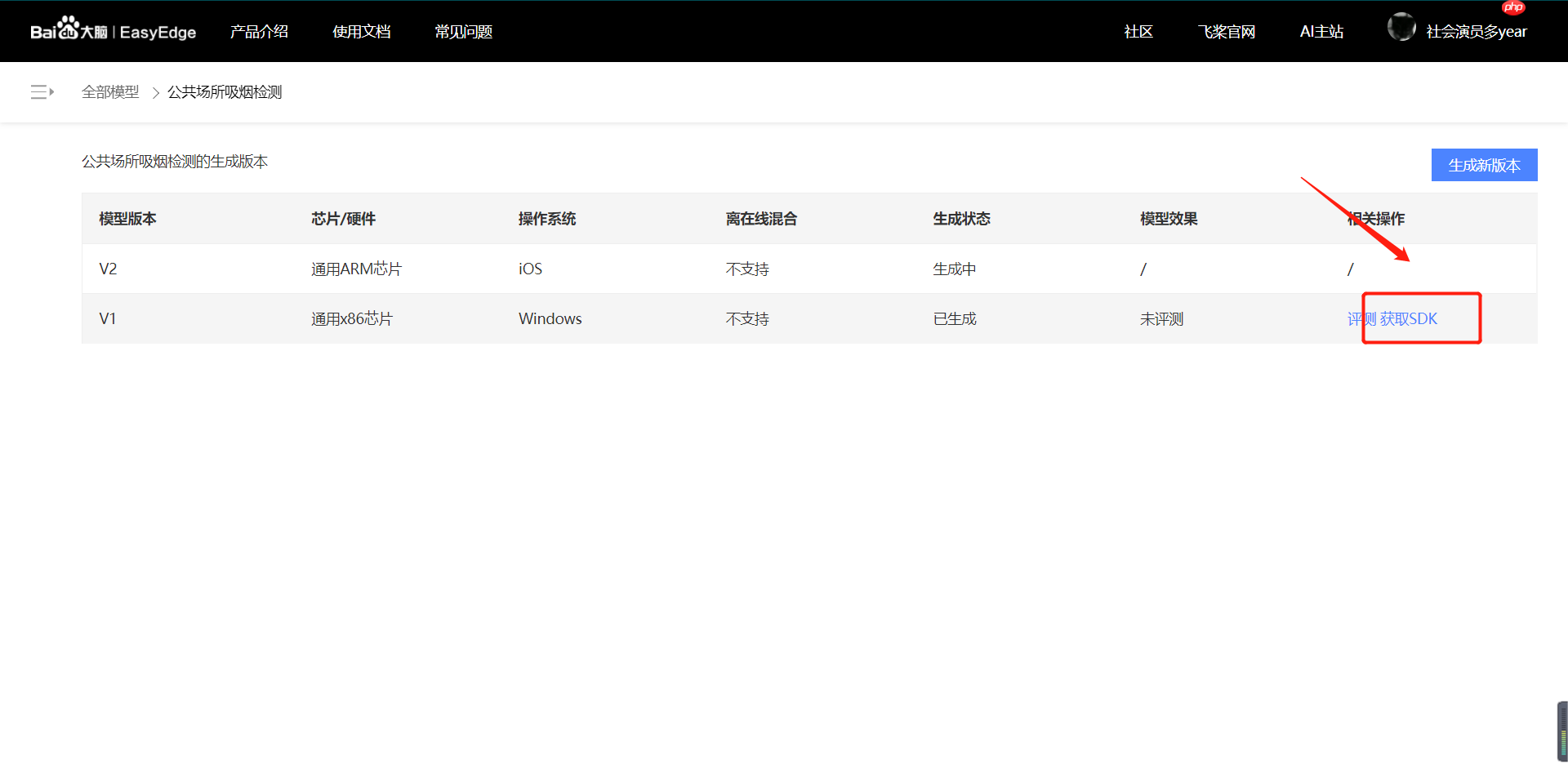
【第八步】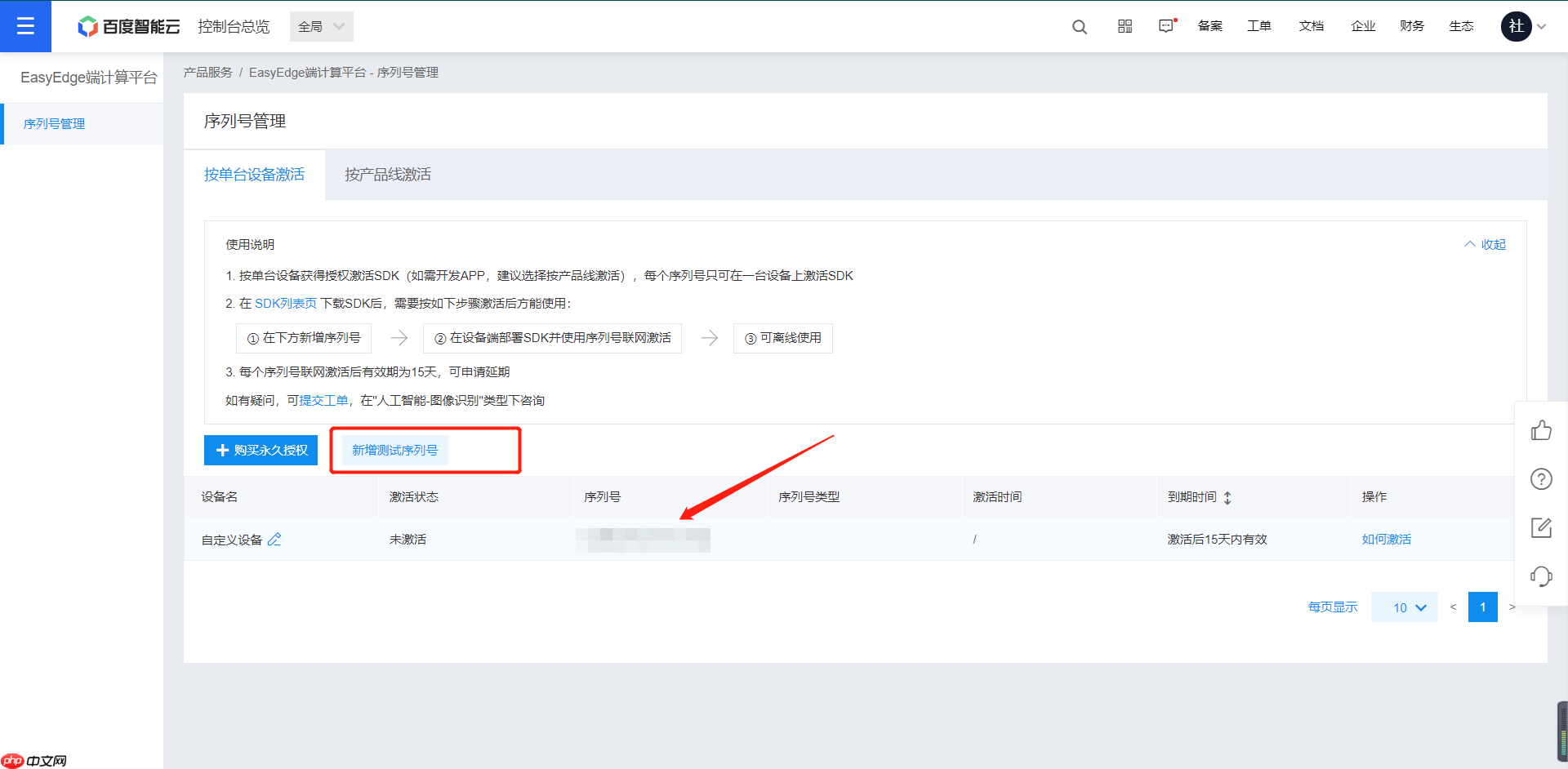
【第九步】 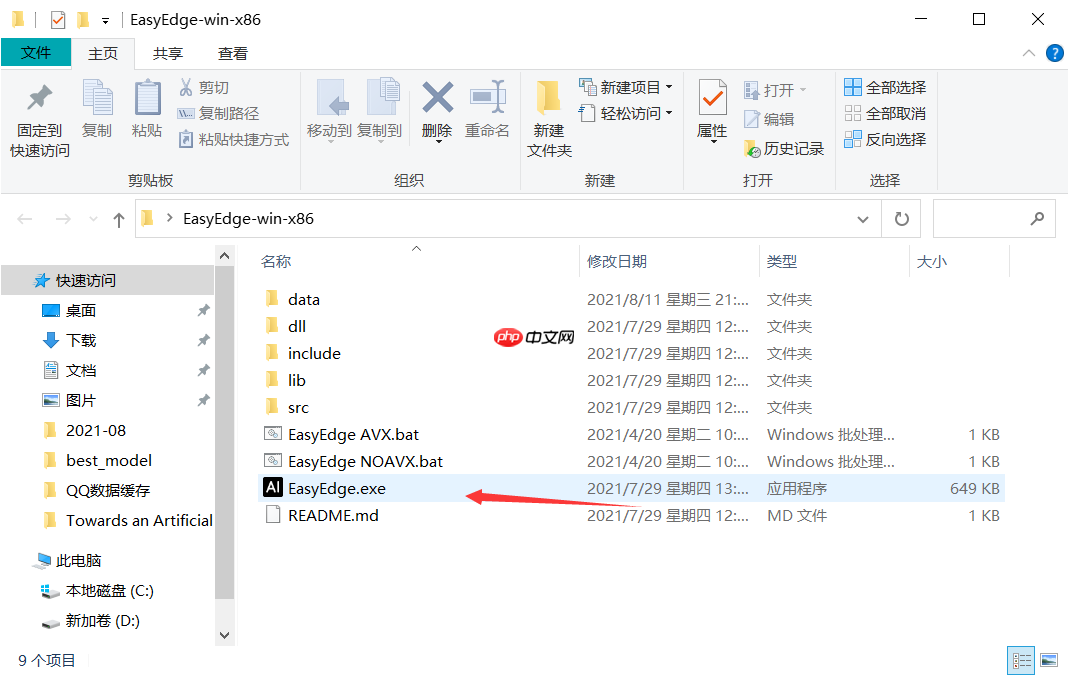
【第十步】 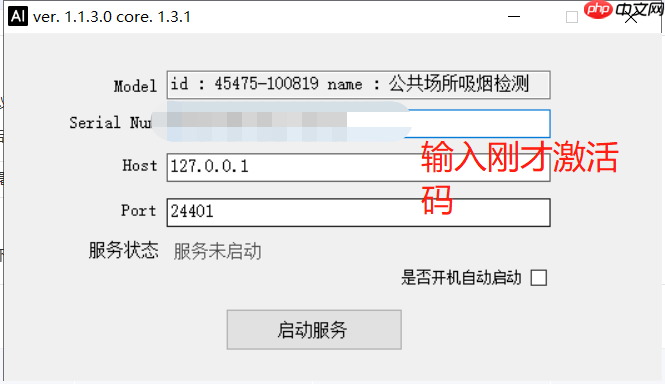
【第十一步】
APP端同样,按操作就可以了
以上就是公共场所吸烟检测与EasyEdge部署的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/54686.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























