
ChatGPT一炮而红,彻底把openAI这个创业公司整破圈了,短短5天,全球注册用户就突破100万,至今仍热度不减。
但为什么是OpenAI做出了ChatGPT?OpenAI的员工又都是什么背景?
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

抢人大战,openAI赢麻了
根据外媒Leadgenious Punks & Pinstripes对目前736名OpenAI员工的背景进行分析后可以发现:几乎所有的 OpenAI 核心人才都来自大型科技公司。
其中有59人之前就职于谷歌,其次是Meta (34人) ,苹果(15人) ,Dropbox (14人) ,亚马逊(11人)。
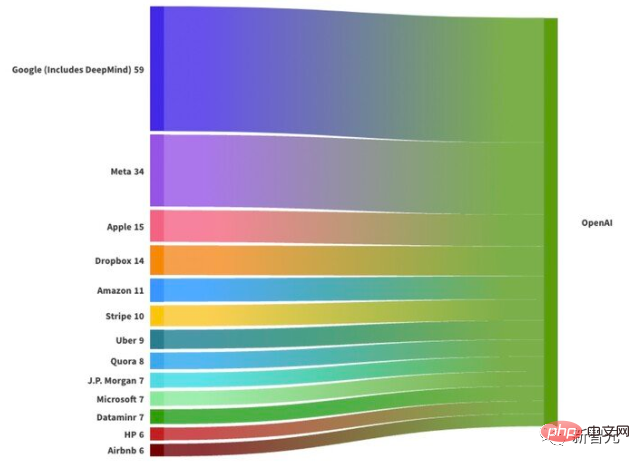
在OpenAI的员工中,有389人曾在硬件或软件公司工作;还有39人来自金融服务业,包括摩根大通(7名外籍员工)、罗宾汉(5人)和瑞银(3人)。
OpenAI在技术人才的争夺上,已经赢麻了。
LeadGenius 的研究结果也为大型科技公司敲响了「人才警钟」,那些大型科技公司,尤其是谷歌对员工的关注度并不够。
从谷歌离职的人里面,很多都是在创新实验室(如Alphabet X)中进行一些次级产品的研发,也就意味着,他们基本看不到自己的工作成果对公司的核心产品或收益产生有意义的影响。
而openAI可以给他们这个机会。
此外,OpenAI招聘了39名金融员工,远超行业预期,是否意味着OpenAI的下一步棋就是「挑战金融服务业」?
360 Digital Immersion 公司总裁兼创始人Lisa Wardlaw表示,「现在下结论还为时过早,但他们的确为寻找新选择的华尔街人才提供了一个可行的选择。」
在马克·扎克伯格创办Facebook的那个年代,只需要一间大学宿舍,或是一个车库就能开一家世界级公司;而OpenAI的成功则是从大公司「挖墙脚」。
谷歌:OpenAI的后备人才库
早在去年11月ChatGPT发布的博客文章中,致谢部分可以发现5名谷歌员工的名字:Barret Zoph, Liam Fedus, Luke Metz, Jacob Menick, Rapha Gontijo Lope

领英显示,Barret Zoph于2022年8月离职Google Brain,加入OpenAI参与打造ChatGPT,主要研究方向为训练大型稀疏语言模型和AuoML,如神经结构搜索(NAS)。

Liam Fedus于2018年入职Google Brain,2022年9月左右入职OpenAI,在蒙特利尔大学攻读博士期间导师为图灵奖得主Yoshua Bengio,研究方向横跨有监督、无监督和强化学习。
 怪兽AI知识库
怪兽AI知识库
企业知识库大模型 + 智能的AI问答机器人
 51 查看详情
51 查看详情 

Luke Metz于2016年入职Google Brain任高级研究科学家,目前在领英和推特个人主页尚未显示加入OpenAI.
Jacob Menick于2015年9月入职DeepMind,2022年9月入职OpenAI任研究员,博士毕业于伦敦大学学院,主要研究方向为机器学习、生成式模式、大规模深度学习、变分推理、信息论和稀疏模型。

Rapha Gontijo Lope于2018年6月本科毕业于佐治亚理工学院,后入职Google Brain,期间参与了为期两年的谷歌AI留居计划,2022年9月入职OpenAI

不过最大的boss还是OpenAI的联合创始人和首席科学家Ilya Sutskever,他在2005年毕业于多伦多大学,2012年获得计算机科学博士学位。

毕业至今,曾先后就职于斯坦福大学,DNNResearch,Google Brain,从事机器学习与深度学习的相关研究,并于2015年放弃谷歌的高薪职位,与Greg Brockman等人联合创建了OpenAI,在OpenAI主导了GPT-1,2,3以及DALLE系列模型的研发。
谷歌还是太怕风险了
上面提到的几位员工大多曾在Google Brain任职,有部门员工在接受采访时表示,Google Brain的工作文化让人实在打不起精神,除了有令人难受的官僚主义作风,对待新产品提议的态度也过于谨慎,很多员工都有离职的想法。
另外也有员工抱怨,曾经建议过公司应该把对话功能加入到搜索引擎里,但根本就没人重视。
不过Google Brain内部仍然人才济济,仍然有超过800位以上来自世界各地的顶尖科学家。
除此之外,AppSheet 创始人 Praveen Seshadri 在离职谷歌后也发表了一篇博客,他认为谷歌陷入了一个迷宫之中,员工浪费了大量的精力在审批、启动流程、法律评估、绩效评估、执行评估、文档、会议、错误报告、分类、 OKR、 H1计划、随后的 H2计划、全员峰会和重组上,实际能做的事非常少。

尤其是面临OpenAI和微软的围剿,谷歌不仅面临技术上的压力,还面临大裁员等问题,在某种程度上反映出管理层和员工普遍缺乏自我意识。
最大的问题还是在于谷歌的核心文化:
没有使命感(no mission)没有紧迫感(no urgency)过度审查(delusions of exceptionalism)管理不善(mismanagement)
尽管谷歌的两个核心价值观是「尊重用户」和「尊重机会」,但在实践中,这些系统和流程被有意设计为「尊重风险」。
风险缓解胜过一切,如果一切进展顺利,最重要的事情是避免出现问题,并在广告收入不断增加的情况下继续前行:
更改的每一行代码都有风险,因此需要大量的中间过程来确保每一次代码更改都能完美地避免风险;发布的任何东西都是有风险的,所以要进行大量的审查和批准,哪怕只是在一个小产品上发布一个小变化;任何不明显的决定都是风险,需要由群体共同决定;任何与过去不同的做事方式都是风险,所以要坚持原来的方式;任何对你不满意的员工都是职业风险,所以经理们的目标是100% 的员工满意度,即使对待表现最差的员工也要小心翼翼;任何与管理链的分歧都是职业风险,所以一定要应承自己的上级;
如果重点转移到价值创造上,那么一切都会变得不同,比如每天问自己「我今天为谁创造了价值」,如果能创造更多的价值,产生更大的影响,员工就会更加努力工作。
早年谷歌在「抢人大战」里疯狂挖Meta等大厂的墙角来扩充自家人才资源,现如今自己反倒成了OpenAI的后备人才库。
难怪ChatGPT爆火后谷歌要拉响「红色警报」,再不重视人才的保护,自家培养的高级研究员早晚要被挖完!
参考资料:https://www.php.cn/link/2287c6b8641dd2d21ab050eb9ff795f3
以上就是OpenAI专业挖角,近100位大佬到手!谷歌、Meta等大厂沦为「后备人才库」的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/552599.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















