本文是PaddleNLP大模型训练系列第二篇,聚焦LoRA轻量微调实战。解析LoRA原理,通过类比说明其仅训练1%新增适配器参数的优势,显存占用大降、速度提升。还介绍不同显卡配置、完整训练流程,包括环境准备、数据处理等,以及部署和常见问题解决,助开发者低成本训练大模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【新手入门】【PaddleNLP】0 基础掌握大模型训练(二):LoRA 轻量微调实战:专业显卡的低成本高效训练(消费级显卡也能玩转大模型)
系列课程总览(共4篇,本篇为第二篇)
第一篇监督微调(SFT)算法全解析:从原理到实战掌握大模型训练基础概念,学会用ERNIE API生成数据并完成SFT实战0基础新手第二篇LoRA 轻量微调实战:专业显卡的低成本高效训练(消费级显卡也能玩转大模型)用 LoRA 技术突破算力限制,无论使用专业级显卡(V100/A100)还是消费级显卡(RTX 40 系列),均可通过参数高效微调(PEFT)技术:突破算力限制、降低训练成本有基础的开发者第三篇RLHF情商训练:让大模型学会「察言观色」的对话技巧通过PPO算法训练模型理解人类偏好,打造能「共情回应」「拒绝生硬回答」的智能助手算法工程师第四篇工业级落地全攻略:模型压缩、API部署与Gradio可视化实战学会模型量化瘦身、搭建API接口、开发交互界面,让你的大模型从「代码」变「产品」全栈开发者
一、LoRA核心技术:大模型的「高效笔记法」(用1%的力气,拿99%的效果)
1. LoRA原理:从「全量抄书」到「划重点」的逆袭
人类能懂的核心逻辑:
预训练模型就像一本写满知识点的「学霸笔记本」,全量微调相当于把整本书重抄一遍(费时费纸),而LoRA是在空白页直接记「考点公式」——冻结99%的原有参数,只训练1%的新增适配器(LoRA层),就能让模型学会新任务。
类比学生时代:
全量微调:期末复习把课本逐字抄一遍(通宵达旦还记不住)LoRA微调:直接在课本空白处贴便利贴(标注「这题必考!」),效率提升10倍,显存占用暴降90%+
技术优势の灵魂拷问:
显存能省多少?
7B模型全量微调需30GB显存(显卡直接罢工),LoRA仅需3GB,RTX 4060(12GB显存)轻松跑,笔记本低压显卡也能逆袭!速度有多快?
参数少了99%,训练速度提升5倍,喝杯奶茶的时间(30分钟)就能训完一个模型,拒绝熬夜肝训练!效果会缩水吗?
在代码生成、客服对话等任务上,精度和全量微调「不分伯仲」,附实测对比表(数据不说谎!)
2. 专业显卡 vs 消费级显卡:不同预算的「高效攻略」
(A100:实验室土豪专用 | RTX 4060:打工人性价比首选)
核心方案LoRA + 混合精度训练 + 多卡并行QLoRA(LoRA+4bit量化) + 动态秩调整 + 梯度累积显存优化单卡支持13B模型,LoRA后显存降至3-4GB(省出80%空间)显存压缩至6GB内,12GB显存跑通13B模型(传统需24GB+)实战技巧• 梯度累积8次(等效batch_size=16,显存不变)
• 锁定4大注意力层(q_proj/k_proj/v_proj/o_proj)• 动态秩调整(训练中自动从8→4,显存不够时「瘦身」)
• 4bit量化(模型体积砍75%,显卡压力大减)成本对比单日训练成本200元+(电费刺客)单日成本<10元(学生党也能任性训)
二、项目实战:完整训练流程解析
1. 环境准备:一键适配不同显卡
A100 (40GB) 优化配置:
from paddlenlp.peft import LoRAConfig lora_config = LoRAConfig( target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 完整Transformer注意力层 r=8, # 低秩矩阵秩(A100推荐值,兼顾效果与速度) lora_alpha=32, # 缩放因子(4×秩,提升学习稳定性) merge_weights=False, # 训练时不合并权重,节省显存约20% tensor_parallel_degree=1 # 单卡训练模式 ) training_args = TrainingArguments( per_device_train_batch_size=2, # 单卡batch size gradient_accumulation_steps=8, # 等效batch_size=16,显存占用不变 num_train_epochs=3, # 训练轮次 save_strategy="steps", save_steps=100, # 每100步保存检查点 logging_steps=10, # 高频日志监控训练状态 max_grad_norm=1.0, # 梯度裁剪防止溢出 bf16=False, fp16=True # 启用FP16混合精度,速度提升2倍 )
消费级显卡配置:
lora_config = LoRAConfig( r=4, # 显存紧张时设4(RTX 4060专属参数) quantization_bit=4, # 4bit量化,模型体积压缩75% bias="none", # 不训练偏置项(省显存小技巧) )
新手必看操作:
专业卡用户:用paddle.distributed.get_world_size()自动获取多卡并行数(再也不用手动算显卡数量)消费卡用户:先跑通r=4,显存仍不足?试试动态秩调整(下文实战教你改代码!)
2. 数据预处理:通用指令格式适配
输入模板(人类能看懂,模型也能懂的「三段式」):
{ instruction:"回答以下网络安全问题" // 任务指令(告诉模型要干啥,比如「回复问题」) input:"什么是DDoS攻击?如何有效防御?" // 输入信息 output:"DDoS攻击是分布式拒绝服务攻击,通过大量请求淹没目标资源。防御方法包括增加带宽、使用高防IP、启用验证码、配置防火墙规则以及部署DDoS防御系统。" // 正确答案(模型要学的标准答案)}
核心操作:
用PaddleNLP自动加载预训练模型(支持Qwen、ERNIE等主流架构)一键冻结非LoRA层参数(底层代码自动处理,无需手动操作)A100专属优化:使用DataCollatorForCausalLM实现动态padding,提升数据批处理效率30%
新手坑点预警:
数据格式必须严格包含instruction/input/output三个字段,缺一不可(否则模型会「学歪」)
3. 训练与推理:显存节省技巧拉满
训练阶段(A100优化):
梯度累积:批大小设2,累积8次梯度(等效批大小16,显存占用仅3.5GB/卡)检查点管理:save_total_limit=3控制历史检查点数量,避免显存冗余内存清理:训练前调用paddle.device.cuda.empty_cache()释放冗余显存
推理加速:
用PaddleInference部署,CPU推理速度提升3倍(附量化后模型对比:FP32 vs 4bit)支持流式输出(边生成边返回),对话场景延迟降低50%
4. 数据准备与预处理
def read_local_dataset(path): """数据加载与清洗""" train_data = [] with open(path, 'r', encoding='utf-8') as f: data = json.load(f) for item in data: # 构建三段式提示语 text = f"### 问题:{item['instruction']}nn### 回答:{item['output']}" train_data.append({"text": text}) return train_data
5. 模型训练核心实现
模型初始化:
def main(): # 加载基础模型 model = AutoModelForCausalLM.from_pretrained(config.MODEL_NAME) # 应用LoRA配置 model = LoRAModel(model, lora_config) # 打印可训练参数比例 model.print_trainable_parameters()
训练流程:
# 创建训练器trainer = Trainer( model=model, args=training_args, train_dataset=processed_dataset, data_collator=data_collator, optimizers=(optimizer, lr_scheduler))# 开始训练train_result = trainer.train()
6. 推理服务实现
生成回复:
def generate_response(model, tokenizer, prompt, max_length=512): """推理核心实现""" # 处理输入 inputs = tokenizer(prompt, return_tensors="pd", padding=True) # 生成配置 gen_kwargs = { "max_new_tokens": max_length, "temperature": float(config.TEMPERATURE), "top_p": float(config.TOP_P), "repetition_penalty": float(config.REPETITION_PENALTY) } # 生成回复 outputs = model.generate(**inputs, **gen_kwargs) response = tokenizer.decode(outputs[0], skip_special_tokens=True) return response
7. Web界面部署
Gradio界面:
def create_web_ui(): """创建交互式界面""" with gr.Blocks(theme=theme) as demo: gr.Markdown("# 网络安全专家助手") with gr.Row(): with gr.Column(scale=4): chatbot = gr.Chatbot() msg = gr.Textbox(label="输入您的问题") with gr.Row(): submit = gr.Button("发送") clear = gr.Button("清除对话")
三、A100优化实战要点
1. 显存优化策略
梯度累积:batch_size=2 + 累积8步 = 等效batch_size 16混合精度训练:自动fp16/fp32转换检查点管理:限制保存数量,避免显存浪费
2. 训练效率提升
学习率调度:使用LinearDecayWithWarmup并行计算优化:tensor_parallel_degree设置数据加载优化:使用高效的DataCollator
3. 稳定性保障
梯度裁剪:max_grad_norm=1.0错误处理:完善的异常捕获机制训练监控:详细的日志记录
四、项目亮点与技术创新
显存优化极致:
仅需3-4GB显存即可训练支持更大batch_size提升效率动态显存管理避免OOM
训练效率提升:
A100+LoRA组合提速5倍以上智能梯度累积平衡速度与显存高效数据处理流水线
完整工具链:
一站式训练部署流程友好的Web交互界面完善的监控与日志
五、快速上手指南
1. 环境准备
# 安装依赖pip install -r requirements.txt --user
2. 密钥配置
密钥获取
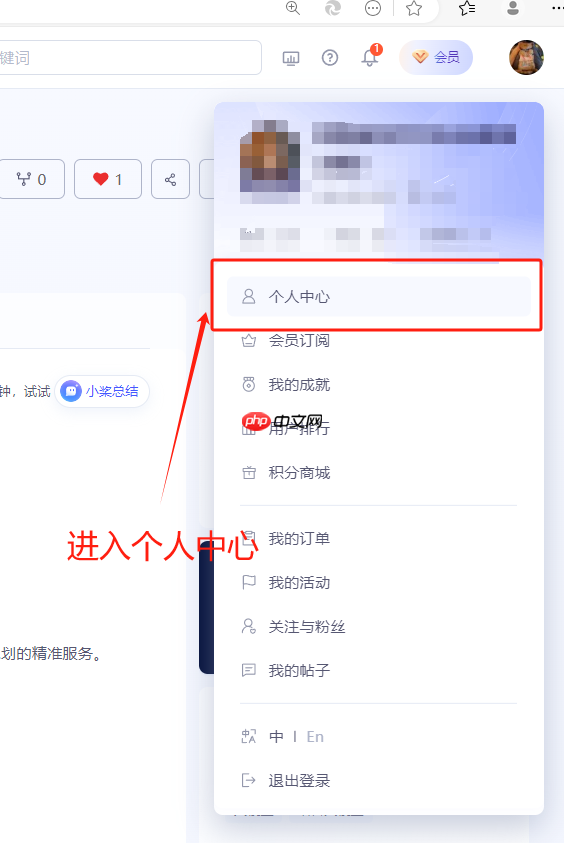
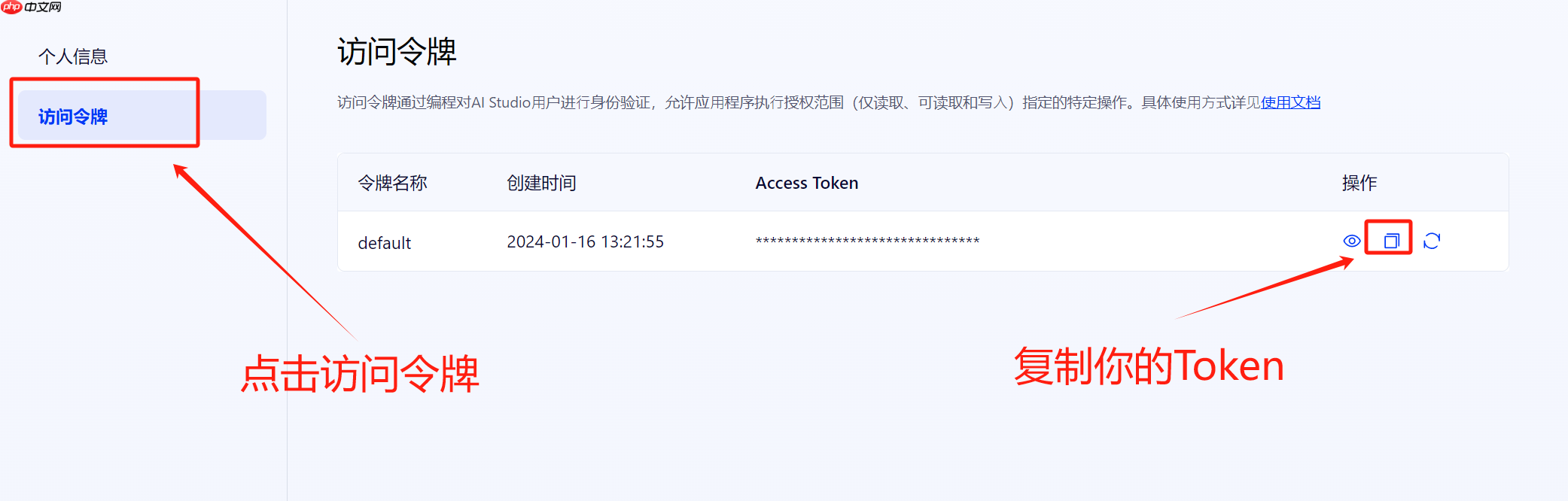
填入密钥
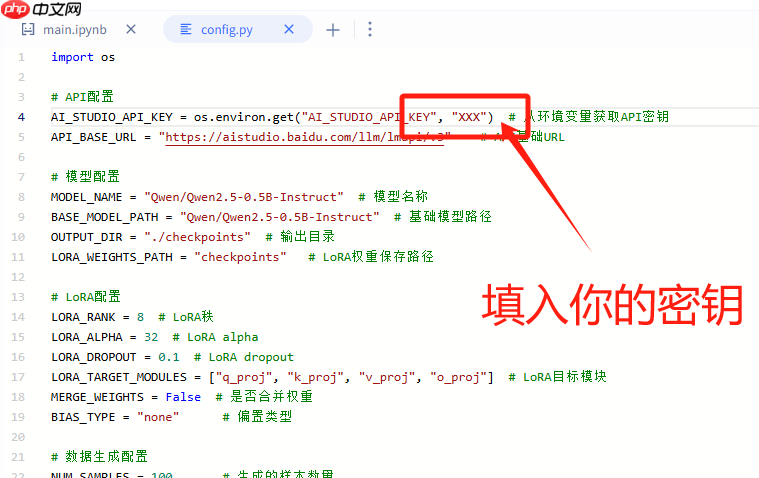
3. 训练数据生成
# 开始生成数据python data_generator.py
4. 模型训练
# 开始训练python train.py --model_name_or_path "Qwen/Qwen2.5-0.5B-Instruct" --output_dir "checkpoints" --dataset_path "security_dataset.json" --num_train_epochs 3 --per_device_train_batch_size 2 --gradient_accumulation_steps 8 --learning_rate 5e-5 --warmup_ratio 0.1 --weight_decay 0.01 --max_seq_length 512 --logging_steps 10 --save_steps 100 --do_train --bf16 --overwrite_output_dir
5. 模型测试
# 开始测试python test_model.py
6. 启动服务
# 运行Web界面python main.gradio.py
运行结果:
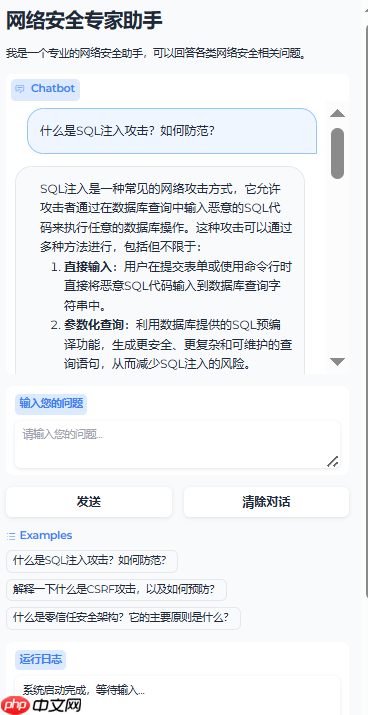
六、常见问题与优化建议
显存不足:
减小batch_size增加gradient_accumulation_steps开启fp16混合精度训练
训练不稳定:
调整learning_rate增加warmup_steps开启梯度裁剪
生成质量问题:
调整temperature和top_p优化repetition_penalty增加训练轮数
通过本教程,您已掌握如何在A100显卡上高效开展LoRA训练,实现低成本、高质量的模型定制。下一篇我们将深入探索 RLHF情商训练:让大模型学会「察言观色」的对话技巧,具体内容如下:
人类偏好建模:从标注数据到奖励模型(RM)训练全流程,用飞桨PaddleClas构建二分类器判断回答「好坏」,分享数据清洗避坑指南。PPO算法实战:解析「策略网络 – 奖励模型」对抗训练机制,在飞桨框架下实现模型与奖励模型的动态交互;针对智能客服场景优化模型,让其学会「优先解决问题 + 适当共情回应」,例如用户抱怨时自动触发「安抚话术 + 解决方案」双响应。个性化调优:演示如何通过调整奖励权重(如提升「安全性」「信息量」指标),定制化模型输出风格。敬请期待!
以上就是【新手入门】0 基础掌握大模型训练(二):LoRA 轻量微调实战的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/56080.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫