
针对第九届“泰迪杯”数据挖掘挑战赛B题,本文提出岩石样本智能识别方案。对岩性识别,采用EfficientNet等深度学习模型,经数据增强处理样本,通过并行网络提升性能;对含油面积计算,基于荧光图像,利用OpenCV处理三通道像素,经阈值分割等步骤得出占比,为岩石分析提供支持。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

第九届“泰迪杯”数据挖掘挑战赛——B 题:岩石样本的智能识别
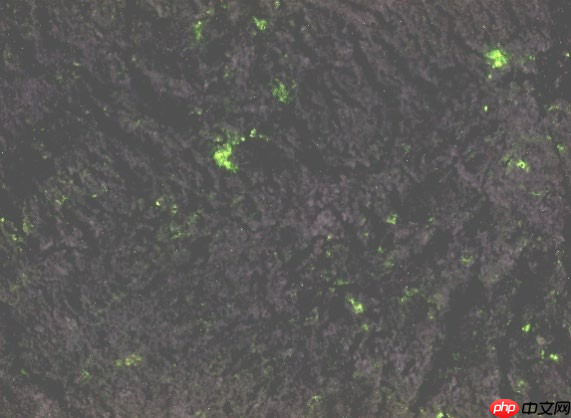
1 问题背景 在油气勘探中,岩石样本识别是一项即基础又重要的环节;在矿产资源勘探中,尤其是在固体金属矿产资源勘探中,岩石样本识别同样发挥着不可估量的作用;岩石样本的识别与分类对于地质分析极为重要。目前岩石样本识别的方法主要有重磁、测井、地震、遥感、电磁、地球化学、手标本及薄片分析方法等方法,而采用图像深度学习的方法建立岩石样本自动识别分类模型是一条新的途径。 现有样本数据是采用工业相机在录井现场对岩屑和岩心样品进行拍照,分别在暗箱内拍摄白光和荧光两种相片,如图 1 和图 2 所示。白光灯下拍摄的相片是用于提取颜色、纹理、粒度等特征识别岩性,荧光灯下拍摄的相片是用于识别含油气性(石油在紫外线照射下具有的发光特征,其中的绿色和黄色部分是含油的,见图 2)。

1 要解决的问题 数据集 rock 中,“白光/荧光”标签为“1”的数据是相同白光环境下拍摄的岩石样本图像数据,“白光/荧光”标签为“2”的数据是相同荧光环境下拍摄的岩石样本图像数据, 请利用数据集 rock 的数据完成以下问题。(1).构建岩石样本岩性智能识别模型。请设计合适的机器学习或深度学习算法,针对数据集 rock 实现岩石样本岩性智能识别与分类。(2).计算岩石含油面积百分含量。石油在紫外线照射下具有发光特征,即荧光灯下拍摄的相片中绿色或黄色部分是含油的,请设计合适的算法计算岩石的含油面积百分含量(绿色和黄色部分的面积占总岩石面积的百分比)。1.岩石含油面积占比计算2.岩石样本智能分类
解决方案
问题1的解决方案:近年来深度学习已经成为当今研究热点,深度学习方法逐渐的被用于各个领域,作为智能诊断的途径之一。岩石岩性的识别与分类对于地质分析极为重要,采用深度学习的方法,建立智能识别模型成为一种新途径。本文基于EfficientNet卷积神经网络,建立了岩石岩性的智能识别诊断模型,实现了岩石岩性的自动识别与分类,避免了手动提取待分类物体特征,节约了人力成本。同时本文对模型的性能展开了相关研究。Setp1:数据增强。分析数据,发现数据样本少、类别不均衡,由于神经网络模型的鲁棒性十分受数据的类别数量和总数量影响,因此使用一系列的数据增强方法,给我们原数据增加数据量(包括图像的旋转、裁剪、缩放、增加噪声等方式)。Step2:卷积神经网络选择。本文同时建立了ResNet50、VGG16、EfficientNet以及针对本文样本过少的数据集提出的并行网络共四种网络进行了探究实验。并行网络是由ResNet50和EfficientNetB0并行计算,然后再输出到一层的全连接层上。拥有更好的性能,同时参数量不超过EfficientNetB5。问题2的解决方案:含油部分包含绿色和黄色两种,黄色部分由红色和绿色结合而成,因此所求区域为:绿色通道(G)像素部分为255,且该像素位置对应的蓝色通道(B)像素部分为0。此时红色通道(R)为255时显示为黄色,为0时显示为绿色。Setp1:利用OpenCV以RBG三通道格式依次读取莹光下拍摄的图片,共315张。Step2:将读取后的三通道像素值进行二值化,大于阈值80的像素赋值为255(全白),小于阈值80的像素赋值为0(全黑),分别取出三个通道。Setp3:将绿色通道(G)与蓝色通道(B)的像素矩阵从0-255之间拉伸到0-1之间;即像素0改成0,像素255改成1。将拉伸后的两个像素矩阵相加,其中矩阵值为2的位置矩阵值改为1,小于2的位置矩阵值改为0,得到的交集矩阵(GB)就是绿色通道(G)和蓝色通道(B)中的像素同时为255的位置。最后将绿色通道(G)减去交集矩阵(GB),得到的区域即为所求含油区域。总结
项目说明
一.问题1的解决方案二.问题2的解决方案三.总结优点不足In [ ]
#解压数据集!unzip data/data75982/code.zip -d mydata
一.岩石含油面积占比计算
参考:OTSU算法(大津法—最大类间方差法)原理及实现
1.阈值分割一张图片,用于观察2.阈值分割计算多张,并保存到csv文件中3.OTSU算法代码,尝试寻找最优阈值,但效果不佳,最后人为手动选择80作为阈值In [1]
#导入模块import pandas as pdimport numpy as npimport osimport matplotlib.pyplot as pltimport cv2
In [ ]
#阈值分割一张图片,用于观察img = cv2.imread('/home/aistudio/mydata/Rock/330-2.jpg',1)gray = img[:,:,::-1]#BGR to RGB#cv2.threshold (源图片, 阈值, 填充色, 阈值类型)ret,thresh2 = cv2.threshold(gray, 80 ,255, cv2.THRESH_BINARY)#展示原图plt.imshow(img)plt.show()# #展示二值化后的图# plt.imshow(thresh2)# plt.show()dist_transform = np.array(thresh2)h,w,_ = dist_transform.shapeprint("维度为:",dist_transform.shape)#取出三通道img_R = dist_transform[:,:,0]img_G = dist_transform[:,:,1]img_B = dist_transform[:,:,2]#展示图片plt.axis('off')#不显示坐标轴plt.imshow(img_R)plt.show()plt.axis('off')#不显示坐标轴plt.imshow(img_G)plt.show()plt.axis('off')#不显示坐标轴plt.imshow(img_B)plt.show()#该函数是去除数组中的重复数字,并进行排序之后输出dist_transform = np.unique(dist_transform, return_index=False, return_inverse=False, return_counts=False)print(dist_transform)#要求绿色和黄色部分。黄色部分由红色和绿色结合而成#因此所求区域为:像素绿色通道部分为255,且该像素位置蓝色通道为0。此时红色通道为255时显示为黄色;为0时显示为绿色#G通道与B通道求交集。再将绿色通道减区交集,得到的区域即为所求区域img_G[img_G > 0] = 1#将255化为1img_B[img_B > 0] = 1GB = img_G + img_BGB = GB==2 #取出共同部分--交集,也就是都是G和B都是1的部分,img_final = img_G - GBresult = np.sum(img_final)/(h * w)print("百分比为:{:0.4f}%".format(result*100))#展示最后的分割图片img_final = img_final * 255#拉伸到255plt.imshow(img_final)plt.axis('off')#不显示坐标轴plt.savefig("./55252.jpg",dpi=120,transparent=True,pad_inches=0,bbox_inches='tight')plt.show()
维度为: (2048, 2448, 3)
[ 0 255]百分比为:0.0970%
In [ ]
#计算多张,并保存到csv文件中def Calculate_percentage(img_path = '/home/aistudio/mydata/Rock/330-2.jpg'): img = cv2.imread(img_path,1)#三通道读取 gray = img[:,:,::-1]#BGR to RGB #cv2.threshold (源图片, 阈值, 填充色, 阈值类型) ret,thresh2 = cv2.threshold(gray, 80 ,255, cv2.THRESH_BINARY)#小于150的像素为0,大于150的像素为255 #将二值化后的图转成numpy格式 dist_transform = np.array(thresh2) h,w,_ = dist_transform.shape#取出维度 # print("维度为:",dist_transform.shape) #取出三通道 img_R = dist_transform[:,:,0] img_G = dist_transform[:,:,1] img_B = dist_transform[:,:,2] # #展示图片 # plt.imshow(img_R) # plt.show() # plt.imshow(img_G) # plt.show() # plt.imshow(img_B) # plt.show() #该函数是去除数组中的重复数字,并进行排序之后输出 # dist_transform = np.unique(dist_transform, return_index=False, return_inverse=False, return_counts=False) # print(dist_transform) #要求绿色和黄色部分。黄色部分由红色和绿色结合而成 #因此所求区域为:像素绿色通道部分为255,且该像素位置蓝色通道为0。此时红色通道为255时显示为黄色;为0时显示为绿色 #G通道与B通道求交集。再将绿色通道减区交集,得到的区域即为所求区域 img_G[img_G > 0] = 1#将255化为1 img_B[img_B > 0] = 1 GB = img_G + img_B GB = GB==2 #取出共同部分--交集,也就是都是G和B都是1的部分 img_final = img_G - GB result = np.sum(img_final)/(h * w)#计算百分比 #print("百分比为:{:0.4f}%".format(result*100)) return resultpath = "/home/aistudio/mydata/Rock"#读取csv文件csv = pd.read_csv("/home/aistudio/mydata/result_2.csv",encoding="gbk")for i in range(len(csv["样本编号"])): id_s = csv["样本编号"][i] if id_s <= 321:#图片为.bmp格式 img_path = os.path.join(path,str(id_s) + "-2.bmp") else: img_path = os.path.join(path,str(id_s) + "-2.jpg") result = Calculate_percentage(img_path) csv["含油面积百分含量"][i] = result if i % 20 == 0: print("处理到第{}张图片".format(i))print(csv)#保存列名,不保存行索引,保留小数点后6位csv.to_csv("/home/aistudio/mydata/my_results.csv",encoding="utf-8-sig", header=True, index=False,float_format='%.6f')
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:50: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
处理到第0张图片处理到第20张图片处理到第40张图片处理到第60张图片处理到第80张图片处理到第100张图片处理到第120张图片处理到第140张图片处理到第160张图片处理到第180张图片处理到第200张图片处理到第220张图片处理到第240张图片处理到第260张图片处理到第280张图片处理到第300张图片 样本编号 含油面积百分含量0 1 0.0025531 2 0.0002112 3 0.0000973 4 0.0048704 5 0.000108.. ... ...310 346 0.003173311 347 0.002854312 348 0.000060313 349 0.000093314 350 0.000997[315 rows x 2 columns]
In [ ]
# OTSU算法代码,尝试寻找最优阈值,但无效,最后人为手动选择80作为阈值'''import mathimport numpy as npfrom matplotlib import pyplot as pltfrom PIL import Imagethreshold_values = {}h = [1]def Hist(img): row, col = img.shape y = np.zeros(256) for i in range(0,row): for j in range(0,col): y[img[i,j]] += 1 x = np.arange(0,256) plt.bar(x, y, color='b', width=5, align='center', alpha=0.25) plt.show() return ydef regenerate_img(img, threshold): row, col = img.shape y = np.zeros((row, col)) for i in range(0,row): for j in range(0,col): if img[i,j] >= threshold: y[i,j] = 255 else: y[i,j] = 0 return y def countPixel(h): cnt = 0 for i in range(0, len(h)): if h[i]>0: cnt += h[i] return cntdef wieght(s, e): w = 0 for i in range(s, e): w += h[i] return wdef mean(s, e): m = 0 w = wieght(s, e) for i in range(s, e): m += h[i] * i return m/float(w)def variance(s, e): v = 0 m = mean(s, e) w = wieght(s, e) for i in range(s, e): v += ((i - m) **2) * h[i] v /= w return v def threshold(h): cnt = countPixel(h) for i in range(1, len(h)): vb = variance(0, i) wb = wieght(0, i) / float(cnt) mb = mean(0, i) vf = variance(i, len(h)) wf = wieght(i, len(h)) / float(cnt) mf = mean(i, len(h)) V2w = wb * (vb) + wf * (vf) V2b = wb * wf * (mb - mf)**2 fw = open("/home/aistudio/mydata/trace.txt", "a") fw.write('T='+ str(i) + "n") fw.write('Wb='+ str(wb) + "n") fw.write('Mb='+ str(mb) + "n") fw.write('Vb='+ str(vb) + "n") fw.write('Wf='+ str(wf) + "n") fw.write('Mf='+ str(mf) + "n") fw.write('Vf='+ str(vf) + "n") fw.write('within class variance='+ str(V2w) + "n") fw.write('between class variance=' + str(V2b) + "n") fw.write("n") if not math.isnan(V2w): threshold_values[i] = V2wdef get_optimal_threshold(): max_V2w = max(threshold_values.values())#itervalues()) optimal_threshold = [k for k, v in threshold_values.items() if v == max_V2w]# print('optimal threshold', optimal_threshold[0]) return optimal_threshold[0]# image = Image.open('/home/aistudio/mydata/image/341-2.jpg').convert("L")# img = np.asarray(image)img = cv2.imread('/home/aistudio/mydata/image/323-2.jpg')img = np.asarray(img)plt.imshow(img)plt.show()gray = img[:,:,::-1]#BGR to RGB# ret,thresh = cv2.threshold(gray, 150 ,150, cv2.THRESH_BINARY)new_img = gray[:,:,1]#RGB中的Gold_img = regenerate_img(new_img,150)plt.imshow(old_img)plt.show()# h = Hist(new_img)# # print(h)# threshold(h)# op_thres = get_optimal_threshold()# res = regenerate_img(new_img, op_thres)# plt.imshow(res)# plt.show()# plt.savefig("/home/aistudio/mydata/otsu_341-2.jpg")'''
二.岩石样本智能分类
1.数据预处理根据标注csv文件处理好类别,共7类,分别为0-6选取白光下拍摄的图片作为数据集,共315张。分为两种格式数据,.bmp格式图片289张,.jpg格式图片26张。经观察,其中.bmp格式图片拍摄到的岩石为近距离拍摄,.jpg格式图片为远距离拍摄。裁剪所有.jpg格式图片的边界空白部分,得到预处理后与.bmp格式类型相近的图片接着对这些图片进行数据增强,增加数据量,并且使每一个类别的样本数量大致均衡。数据增强包括对图像的左上角随机裁剪、右下角随机裁剪、随机90度旋转、随机180度旋转、随机270度旋转、随机的镜面翻转、随机添加高斯模糊、随机平移、随机增强亮度、随机增强色度、随机增强对比度、随机增强锐度等。2.定义数据读取器3.模型组网FusionModel(效果最佳)mobilenet_v2resnet50(尝试了预训练模型和非预训练模型)EfficientNet系列VGG164.模型训练、评估尝试了多种网络结构,以及数据预处理方法,但效果都不佳,acc都较低。FusionModel效果最好,resnet50效果也差不多,但EfficientNet系列的网络acc非常低(efficient网络结构源码是PaddleClas中copy过来的)。原数据315张,不使用数据增强加数据,直接划分出9:1的训练集和验证集,训练出来的验证集acc是在到处摆动,随机性太强。数据增强加了数据量之后,验证集数量达到300多张,模型评估出的acc倒是变得比较稳定,但不知道为什么还是很低。如果训练集acc达到0.9以上,验证集acc只有0.4作用,严重过拟合。要么训练集acc和验证集acc都是0.5到0.6都很低。感觉是数据标注有问题,有的数据类别标注错错误,导致模型非常难学习。In [3]
import paddleimport paddle.nn as nnimport pandas as pdimport numpy as npimport randomimport shutilimport osimport matplotlib.pyplot as pltimport cv2import mathfrom paddle.static import InputSpecfrom visualdl import LogWriterfrom paddle.nn import ReLU, Linear, Conv2D, MaxPool2D, Softmaxfrom PIL import Imagefrom PIL import ImageEnhancefrom PIL import ImageChopsfrom paddle.vision.transforms import functional as Ffrom paddle.vision.transforms import Compose, ColorJitter, Resize,RandomHorizontalFlip,RandomVerticalFlip,RandomResizedCrop,Normalize
1.数据预处理
In [4]
#读取标注文件,但样本类别是中文。生成一个字典,存储中文类别对应的数字标签label_dict = dict()csv = pd.read_csv("/home/aistudio/mydata/rock_label.csv",encoding="gbk")#文件中出现中文时,用gbk读取print(csv)#查看csv文件内容num = 0for i in range(len(csv)): ids = csv["样本编号"][i] labels = csv["样本类别"][i] if i % 20 == 0: print(ids,labels) if labels not in label_dict: label_dict[labels] = len(label_dict)files = open("/home/aistudio/mydata//label_dict.dict","w",encoding="utf-8")files.write(str(label_dict))print(label_dict)
样本编号 样本类别0 1 深灰色泥岩1 2 黑色煤2 3 深灰色泥岩3 4 灰色细砂岩4 5 浅灰色细砂岩.. ... ...310 346 浅灰色细砂岩311 347 深灰色泥岩312 348 深灰色泥岩313 349 浅灰色细砂岩314 350 浅灰色细砂岩[315 rows x 2 columns]1 深灰色泥岩23 灰色细砂岩45 深灰色泥岩66 黑色煤87 深灰色粉砂质泥岩107 浅灰色细砂岩132 深灰色泥岩153 深灰色粉砂质泥岩174 灰黑色泥岩196 浅灰色细砂岩218 浅灰色细砂岩238 深灰色泥岩261 深灰色粉砂质泥岩284 深灰色粉砂质泥岩310 深灰色泥岩335 深灰色泥岩{'深灰色泥岩': 0, '黑色煤': 1, '灰色细砂岩': 2, '浅灰色细砂岩': 3, '深灰色粉砂质泥岩': 4, '灰黑色泥岩': 5, '灰色泥质粉砂岩': 6}
In [ ]
#将白光下拍摄到的数据放到新文件夹下,同时对.jpg格式图片进行裁剪边框,使其分布与.bmp格式数据分布相似from sklearn.utils import shuffleimg_h,img_w = 896,896files = open("/home/aistudio/mydata/label_dict.dict","r",encoding="utf-8")label_dict = eval(files.read())#读取字典#读取标注文件,但样本类别是中文,按照字典来更改标注csv = pd.read_csv("/home/aistudio/mydata/rock_label.csv",encoding="gbk")#文件中出现中文时,用gbk读取# print(dict(csv.loc[:,"样本类别"]))path2 = "/home/aistudio/mydata/Rock"path2 = "/home/aistudio/mydata/data"if not os.path.exists(path2): os.mkdir(path2)for i in range(len(csv["样本类别"])): if csv["样本编号"][i] <= 321:#图片为.bmp格式 img_path = os.path.join(path2,str(csv["样本编号"][i]) + "-1.bmp") new_path = os.path.join(path2,str(csv["样本编号"][i]) + "-1.png") img = cv2.imread(img_path,1) #gray = img[:,:,::-1]#BGR to RGB gray = cv2.resize(img,(img_h,img_w)) cv2.imwrite(new_path,gray) else: # print(csv["样本编号"][i]) img_path = os.path.join(path2,str(csv["样本编号"][i]) + "-1.jpg") new_path = os.path.join(path2,str(csv["样本编号"][i]) + "-1.png") img = cv2.imread(img_path,1) #gray = img[:,:,::-1]#BGR to RGB h,w,_ = img.shape gray = img[int(h/5):int(4*h/5),int(h/5):int(4*h/5),:]#裁剪边框 gray = cv2.resize(gray,(img_h,img_w)) cv2.imwrite(new_path,gray) csv["样本编号"][i] = new_path csv["样本类别"][i] = label_dict[csv["样本类别"][i]] if i % 20 == 0: print("处理到:第{}张".format(i))csv.to_csv("/home/aistudio/mydata/data.csv",index=False)# # print(csv)# csv = csv.sample(frac=1,random_state=100)#共315张图片# train_csv = csv.head(int(len(csv) * 0.9))#取283张作为训练集# val_csv = csv.tail(int(len(csv) * 0.1)+1)#取32张作为验证集# val_csv = val_csv.reset_index(drop=True)#删除之前索引,重新排序# train_csv.to_csv("/home/aistudio/mydata/old_train.csv",index=False)# val_csv.to_csv("/home/aistudio/mydata/old_val.csv",index=False)# print(len(train_csv))# print(val_csv)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:36: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy iloc._setitem_with_indexer(indexer, value)
处理到:第0张处理到:第20张处理到:第40张处理到:第60张处理到:第80张处理到:第100张处理到:第120张处理到:第140张处理到:第160张处理到:第180张处理到:第200张处理到:第220张处理到:第240张处理到:第260张处理到:第280张处理到:第300张
In [4]
#统计类别数,发现类别不均衡,用数据增强增加数据量csv = pd.read_csv("/home/aistudio/mydata/data.csv",encoding="utf-8")#文件中出现中文时,用gbk读取dic = dict()for i in range(len(csv)): if csv["样本类别"][i] not in dic: dic[csv["样本类别"][i]] = 1 else: dic[csv["样本类别"][i]] = 1 + dic[csv["样本类别"][i]]print(dic)
{0: 75, 1: 21, 2: 18, 3: 85, 4: 40, 5: 30, 6: 46}
In [ ]
#数据增强img_h, img_w = 896, 896 def rotate(src_img, angle): """ 旋转 """ src_img = cv2.resize(src_img,(img_h,img_w)) M_rotate = cv2.getRotationMatrix2D((img_h/2, img_w/2), angle, 1)#第一个参数旋转中心,第二个参数旋转角度,第三个参数:缩放比例 src_img = cv2.warpAffine(src_img, M_rotate, (img_h, img_w)) #第三个参数:变换后的图像大小 #src_img = src_img[int(img_h/20):int(19*img_h/20),int(img_w/20):int(19*img_w/20),:] # label_img = cv2.warpAffine(label_img, M_rotate, (img_h, img_w)) return cv2.resize(src_img,(img_h,img_w))def blur(src_img): """ 模糊--均值滤波 """ src_img = cv2.blur(src_img, (3, 3)); return src_img def randomShift(image): #def randomShift(image, xoffset, yoffset=None): """ 对图像进行平移操作 :param image: PIL的图像image :param xoffset: x方向向右平移 :param yoffset: y方向向下平移 :return: 翻转之后的图像 """ random_xoffset = np.random.randint(0, math.ceil(image.size[0]*0.1)) random_yoffset = np.random.randint(0, math.ceil(image.size[1]*0.1)) return ImageChops.offset(image,random_xoffset)def image_brightened(image): #增强亮度 enh_bri = ImageEnhance.Brightness(image) brightness = random.uniform(0.5,1.5) # brightness = 1.5 image_brightened = enh_bri.enhance(brightness) return image_brighteneddef image_colored(image): # 色度增强 enh_col = ImageEnhance.Color(image) color = random.uniform(0.5,1.5) # color = 1.5 image_colored = enh_col.enhance(color) return image_coloreddef image_contrasted(image): # 对比度增强 enh_con = ImageEnhance.Contrast(image) contrast = random.uniform(0.5,1.5) image_contrasted = enh_con.enhance(contrast) return image_contrasteddef image_sharped(image): # 锐度增强 enh_sha = ImageEnhance.Sharpness(image) sharpness = random.uniform(0.5,1.5) image_sharped = enh_sha.enhance(sharpness) return image_sharpeddef image_crop_left(img): ratio1 = int(random.uniform(img_h/20,img_h/8)) ratio2 = int(random.uniform(img_w/20,img_w/8)) img = img[ratio1:,ratio2:,:] return imgdef image_crop_right(img): ratio1 = img_h - int(random.uniform(img_h/20,img_h/8)) ratio2 = img_w - int(random.uniform(img_w/20,img_w/8)) img = img[:ratio1,:ratio2,:] return imgdef data_augment(src_img): # plt.imshow(src_img) # plt.show() # print(src_img.shape) #裁剪 if np.random.random() < 0.4: src_img = image_crop_left(src_img) if np.random.random() < 0.4: src_img = image_crop_right(src_img) # 旋转 if np.random.random() < 0.25: src_img = rotate(src_img,90) if np.random.random() < 0.25: src_img = rotate(src_img,180) if np.random.random() 0:沿 y 轴翻转 if np.random.random() < 0.5: src_img = cv2.flip(src_img, 1) # 模糊 if np.random.random() < 0.2: src_img = blur(src_img) #转换数据类型 src_img = Image.fromarray(np.uint8(src_img)) #平移 if np.random.random() < 0.3: src_img = randomShift(src_img) #增强亮度 if np.random.random() < 0.3: src_img = image_brightened(src_img) # 色度增强 if np.random.random() < 0.3: src_img = image_colored(src_img) # 对比度增强 if np.random.random() < 0.3: src_img = image_contrasted(src_img) # 锐度增强 if np.random.random() < 0.3: src_img = image_sharped(src_img) src_img = np.asarray(src_img).astype('float32') # plt.imshow(src_img) # plt.show() return src_imgimg = cv2.imread("mydata/Rock/327-1.jpg",1).astype('int16')img = img[:,:,::-1]#bgr变成rgbimg = cv2.resize(img,(img_w,img_h))plt.imshow(img)plt.show()img1 = data_augment(img).astype('int16')plt.imshow(img1)plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
In [ ]
#使用数据增强加数据,并放到新文件夹下,每一个类别各400张左右num_class_list = [6,20,20,6,12,14,10]#0-6共7种类别需要的加的数据倍数train_csv = pd.read_csv("/home/aistudio/mydata/data.csv",encoding="utf-8")#文件中出现中文时,用gbk读取# print(dict(csv.loc[:,"样本类别"]))path2 = "/home/aistudio/mydata/data"path3 = "/home/aistudio/mydata/new_data"if not os.path.exists(path3): os.mkdir(path3)new_csv_list = []for i in range(len(train_csv["样本类别"])): img_pth = train_csv["样本编号"][i] img_class = train_csv["样本类别"][i] multiple = num_class_list[img_class]#增强的倍数 for ids in range(multiple): new_img_path = os.path.join(path3,str(ids)+"-"+img_pth.split("/")[-1]) new_csv_list.append({"样本编号":new_img_path,"样本类别":img_class}) if ids == 0: shutil.copy(img_pth,new_img_path) else: img = cv2.imread(img_pth,1).astype('float32') #img = img[:,:,::-1]#bgr变成rgb img = data_augment(img) img = cv2.resize(img,(img_h,img_w)) cv2.imwrite(new_img_path,img) if i % 10 == 0: print("处理到:第{}张".format(i))new_csv = pd.DataFrame(new_csv_list,columns=["样本编号","样本类别"])new_csv.to_csv("/home/aistudio/mydata/new_data.csv",index=False)# #将验证集放到新文件夹下# val_csv = pd.read_csv("/home/aistudio/mydata/old_val.csv",encoding="utf-8")#文件中出现中文时,用gbk读取# # print(dict(csv.loc[:,"样本类别"]))# path2 = "/home/aistudio/mydata/data"# path3 = "/home/aistudio/mydata/val"# if not os.path.exists(path3):# os.mkdir(path3)# for i in range(len(val_csv["样本类别"])):# img_pth = val_csv["样本编号"][i]# #img_class = val_csv["样本类别"][i]# new_img_path = os.path.join(path3,img_pth.split("/")[-1])# #移动图片# val_csv["样本编号"][i] = new_img_path# shutil.move(img_pth,new_img_path)# val_csv.to_csv("/home/aistudio/mydata/val.csv",index=False)
处理到:第0张处理到:第10张处理到:第20张处理到:第30张处理到:第40张处理到:第50张处理到:第60张处理到:第70张处理到:第80张处理到:第90张处理到:第100张处理到:第110张处理到:第120张处理到:第130张处理到:第140张处理到:第150张处理到:第160张处理到:第170张处理到:第180张处理到:第190张处理到:第200张处理到:第210张处理到:第220张处理到:第230张处理到:第240张处理到:第250张处理到:第260张处理到:第270张处理到:第280张处理到:第290张处理到:第300张处理到:第310张
In [ ]
#划分训练集和验证集,按照9:1csv = pd.read_csv("/home/aistudio/mydata/new_data.csv",encoding="utf-8")#文件中出现中文时,用gbk读取# print(csv)csv = csv.sample(frac=1,random_state=100)#共315张图片train_csv = csv.head(int(len(csv) * 0.9))#取283张作为训练集val_csv = csv.tail(int(len(csv) * 0.1)+1)#取32张作为验证集val_csv = val_csv.reset_index(drop=True)#删除之前索引,重新排序train_csv.to_csv("/home/aistudio/mydata/train.csv",index=False)val_csv.to_csv("/home/aistudio/mydata/val.csv",index=False)print(len(train_csv))print(val_csv)
2790 样本编号 样本类别0 /home/aistudio/mydata/new_data/8-74-1.png 61 /home/aistudio/mydata/new_data/3-266-1.png 62 /home/aistudio/mydata/new_data/7-85-1.png 13 /home/aistudio/mydata/new_data/2-228-1.png 34 /home/aistudio/mydata/new_data/7-40-1.png 5.. ... ...306 /home/aistudio/mydata/new_data/2-211-1.png 4307 /home/aistudio/mydata/new_data/3-10-1.png 0308 /home/aistudio/mydata/new_data/11-204-1.png 5309 /home/aistudio/mydata/new_data/2-314-1.png 6310 /home/aistudio/mydata/new_data/2-167-1.png 3[311 rows x 2 columns]
In [4]
#再次统计统计类别数,类别大致均衡csv = pd.read_csv("/home/aistudio/mydata/new_data.csv",encoding="utf-8")#文件中出现中文时,用gbk读取dic = dict()for i in range(len(csv)): if csv["样本类别"][i] not in dic: dic[csv["样本类别"][i]] = 1 else: dic[csv["样本类别"][i]] = 1 + dic[csv["样本类别"][i]]print(dic)
{0: 450, 1: 420, 2: 360, 3: 510, 4: 480, 5: 420, 6: 460}
2.定义数据读取器
In [ ]
#img_h,img_w = 896,896img_h,img_w = 448,448#读取白光下拍摄的图片作为训练集图片class MyDataset(paddle.io.Dataset): def __init__(self, path = "/home/aistudio/mydata/image", is_model = "train" ): self.path = path self.is_model = is_model self.transform = Compose([Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'), Resize(size=(img_h,img_w))]) self.val_transform = Compose([Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'), Resize(size=(img_h,img_w))]) if self.is_model is 'train': self.df = pd.read_csv("/home/aistudio/mydata/train.csv",encoding="utf-8") # self.df = csv = pd.concat([self.df,self.df],axis=0) self.df = self.df.sample(frac=1,random_state=100)#固定随机种子打乱 self.df = self.df.reset_index(drop=True)#删除之前索引,重新排序 # self.df = self.df.head(int(len(self.df) * 0.9))#取部分数据作为训练集 #print(self.df) elif self.is_model is "val": self.df = pd.read_csv("/home/aistudio/mydata/val.csv",encoding="utf-8") # self.df = self.df.tail(int(len(self.df) * 0.1)) # self.df=self.df.reset_index(drop=True)#删除之前索引,重新排序 #print(self.df) else: raise Exception("模型的状态错误") def __getitem__(self, idx): img_path = self.df["样本编号"][idx] #print(img_path) label = np.array([self.df["样本类别"][idx]]).astype('int64') img = cv2.imread(img_path,1).astype('float32') img = img[:,:,::-1]#bgr变成rgb img = Image.fromarray(img.astype(np.uint8)) #print(img) if self.is_model is "train": img = self.transform(img) else: img = self.val_transform(img) img = np.array(img).astype('float32') img = img.reshape(3,img_h,img_w) if self.is_model is 'test': return img return img, label def __len__(self): return len(self.df)train_dataset = MyDataset(is_model="train")# for img,label in train_dataset:# print(img.shape,label)for i in range(len(train_dataset)): img,label = train_dataset[i] print(img.shape,label) break #print(train_data[i])val_dataset = MyDataset(is_model="val")for i in range(len(val_dataset)): img,label = val_dataset[i] print(img.shape,label) breakprint(len(train_dataset))print(len(val_dataset))
(3, 448, 448) [4](3, 448, 448) [6]2790311
3.模型组网
并行网络 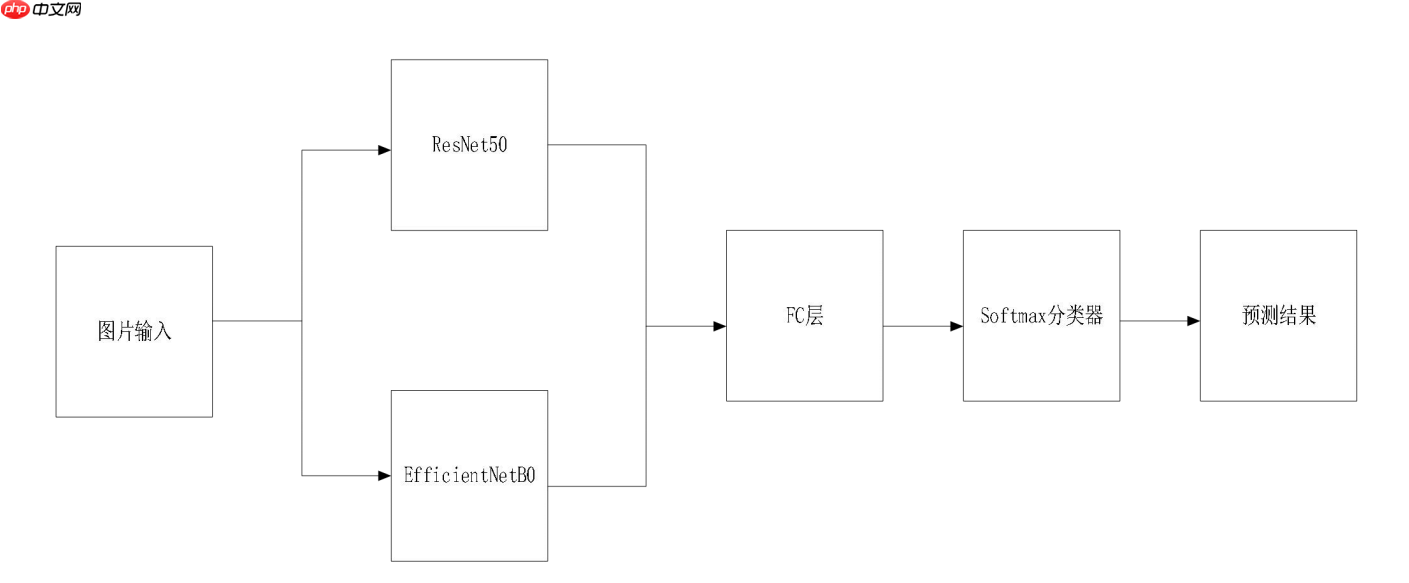 In [ ]
In [ ]
from work.myEfficientNet import *from work.FusionNet import FusionModelmymodel = FusionModel(class_dim = 7)#使用并行网络#mymodel = paddle.vision.models.mobilenet_v2(pretrained=False,num_classes=7)#使用框架内置mobilenet_v2网络#mymodel = paddle.vision.models.resnet50(pretrained=False,num_classes=7)#使用框架内置ResNet50网络#mymodel = paddle.vision.models.resnet50(pretrained=True,num_classes=7)#使用框架内置ResNet50网络,并且使用预训练模型#mymodel = EfficientNetB5(class_dim=7)#使用Efficient网络## 查看模型结构model = paddle.Model(mymodel)print('飞桨框架内置模型:', paddle.vision.models.__all__)model.summary((-1, 3, img_h, img_w))
4.模型训练、验证
In [ ]
#定义数据读取器batch_size = 16#train_loder = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=batch_size, shuffle=True)#使用cpu训练train_loder = paddle.io.DataLoader(train_dataset, places=paddle.CUDAPlace(0), batch_size=batch_size, shuffle=True)#使用gpu训练# 加载验证数据集val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CUDAPlace(0), batch_size=8, shuffle=False)#设置epoch数epochs = 25step = 0lr = paddle.optimizer.lr.PiecewiseDecay(boundaries=[5, 10], values=[0.001, 0.0001, 0.00001], verbose=True)#,last_epoch = 6)#接着训练# lr = paddle.optimizer.lr.LambdaDecay(learning_rate=0.0001, lr_lambda=lambda x:0.95**x, verbose=True)#,last_epoch = 1)#接着训练#恢复训练# state_dict = paddle.load("/home/aistudio/work/save_model/5/5.pdparams")# mymodel.set_state_dict(state_dict)# 定义优化器opt = paddle.optimizer.Adam(learning_rate=lr, parameters = mymodel.parameters())#定义损失函数loss_fn = paddle.nn.CrossEntropyLoss()for epoch in range(1,epochs+1): mymodel.train()#开启训练 all_loss = 0 all_acc = 0 for batch_id, data in enumerate(train_loder()): #分出img和label x_data = data[0] y_data = data[1] #预测结果 predict = mymodel(x_data) #传入损失函数 loss = loss_fn(predict, y_data) #loss_sum += loss.numpy().sum() #查看acc acc = paddle.metric.accuracy(predict, y_data) #acc_sum += acc.numpy().sum() #反向传播 loss.backward() #打印输出 all_loss += loss.numpy() all_acc += acc.numpy() if batch_id % 2 is 0: print("epoch:{}, batch:{}, loss:{}, acc:{}".format(epoch, batch_id, loss.numpy(), acc.numpy())) # #生成VDL日志 # step += 1 # if step % 20 is 0: # #添加acc # writer.add_scalar(tag="train/acc", step=step, value=float(acc.numpy())) # #添加loss # writer.add_scalar(tag="train/loss", step=step, value=float(loss.numpy())) # #记录每一个批次第一张图片 # img = np.reshape(np.array(data[0][0].numpy()), [448, 448, 3]) # writer.add_image(tag="train/input", step=step, img=img) #更新梯度 opt.step() #清除梯度 opt.clear_grad() print("epoch:{},loss:{},acc:{}".format(epoch,all_loss/len(train_loder()),all_acc/len(train_loder()))) lr.step() if epoch % 1 == 0: ## 模型在验证集上评估 # #模型载入 # opt = paddle.optimizer.Adam(learning_rate=0.00001, parameters = mymodel.parameters()) # state_dict = paddle.load("/home/aistudio/work/save_model/5/5.pdparams") # mymodel.set_state_dict(state_dict) # opt_state_dict = paddle.load("/home/aistudio/work/save_model/36/36.pdopt") # opt.set_state_dict(opt_state_dict) mymodel.eval() all_acc = 0 for batch_id, data in enumerate(val_loader()): x_data = data[0] # 数据 y_data = data[1] # 数据标签 predicts = mymodel(x_data) # 预测结果 # 计算损失与精度 loss = loss_fn(predicts, y_data) acc = paddle.metric.accuracy(predicts, y_data) all_acc += acc.numpy() # # 打印信息 # if (batch_id+1) % 1 == 0: # print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id, loss.numpy(), acc.numpy())) print("acc is: {}".format(all_acc/len(val_loader()))) #保存模型参数和优化器参数 if not os.path.exists(os.path.join("/home/aistudio/work/save_model")): os.mkdir(os.path.join("/home/aistudio/work/save_model")) if not os.path.exists(os.path.join("/home/aistudio/work/save_model", str(epoch))): os.mkdir(os.path.join("/home/aistudio/work/save_model", str(epoch))) paddle.save(mymodel.state_dict(), os.path.join("work/save_model", str(epoch), str(epoch) + ".pdparams")) paddle.save(opt.state_dict(), os.path.join("work/save_model", str(epoch), str(epoch) + ".pdopt")) #保存模型结构 #fluid.io.save_inference_model(dirname=os.path.join("work/save_model", str(epoch)), feeded_var_names=['img'],target_vars=[predictions], executor=exe)
In [ ]
## 模型在验证集上评估#模型载入opt = paddle.optimizer.Adam(learning_rate=0.00001, parameters = mymodel.parameters())state_dict = paddle.load("/home/aistudio/work/save_model/17/17.pdparams")mymodel.set_state_dict(state_dict)# opt_state_dict = paddle.load("/home/aistudio/work/save_model/36/36.pdopt")# opt.set_state_dict(opt_state_dict)# 加载验证数据集val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CUDAPlace(0), batch_size=8, shuffle=False)loss_fn = paddle.nn.CrossEntropyLoss()mymodel.eval()all_acc = 0for batch_id, data in enumerate(val_loader()): x_data = data[0] # 数据 y_data = data[1] # 数据标签 predicts = mymodel(x_data) # 预测结果 # 计算损失与精度 loss = loss_fn(predicts, y_data) acc = paddle.metric.accuracy(predicts, y_data) all_acc += acc.numpy() # # 打印信息 # if (batch_id+1) % 1 == 0: # print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id, loss.numpy(), acc.numpy()))print("acc is: {}".format(all_acc/len(val_loader())))
acc is: [0.54716116]
可以使用飞桨高层api训练(用于调试)
In [ ]
# 为模型训练做准备,设置优化器,损失函数和精度计算方式model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=paddle.optimizer.lr.PiecewiseDecay(boundaries=[5, 10], values=[0.001, 0.0001, 0.00001]),parameters=model.parameters()), loss=paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())
In [ ]
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式model.fit(train_dataset, val_dataset, epochs=20, batch_size=16, verbose=1)
The loss value printed in the log is the current step, and the metric is the average value of previous step.Epoch 1/20
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
In [ ]
# 用 evaluate 在测试集上对模型进行验证eval_result = model.evaluate(val_dataset, verbose=1)
以上就是第九届“泰迪杯”数据挖掘挑战赛:岩石样本的智能识别分享的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/57423.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























