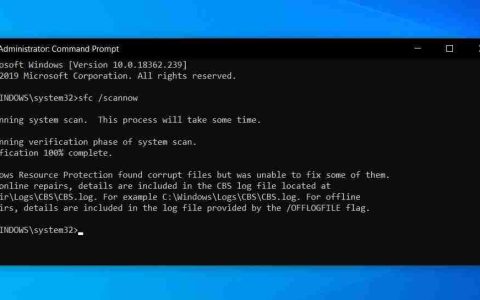
要高效发现和定位慢 sql,首先应开启数据库慢查询日志并设置合理阈值,结合 pt-query-digest 工具分析日志以识别高频高耗时语句;2. 使用 pmm、prometheus + grafana 等实时监控工具观察数据库性能指标,捕捉锁等待、连接数飙升等异常;3. 通过 explain 分析慢 sql 执行计划,重点查看 type、rows、extra 等字段判断是否全表扫描或存在 filesort、temporary 表等问题;4. 结合 show processlist 查看当前执行中处于 locked 或 waiting 状态的查询,辅助定位阻塞源头。该方法系统全面,能精准锁定问题 sql 并为后续优化提供依据,确保问题可追溯可解决。

慢 SQL 确实是系统性能的“隐形杀手”,它不仅仅是让用户多等几秒那么简单,更可能引发一系列连锁反应,比如服务器负载飙升、连接池耗尽,甚至导致整个服务崩溃。彻底解决慢 SQL,核心在于建立一套从发现、诊断、优化到预防的闭环机制,这不仅能显著提升系统响应速度,更能极大增强系统的稳定性和资源利用效率,让业务在高速发展的路上跑得更稳健。
解决方案
要彻底解决慢 SQL,我个人倾向于一个系统性的“排查-治疗-预防”三步走策略。这不像头痛医头脚痛医脚,而是深入到问题的根源。
首先,是精准定位。你得知道哪个 SQL 语句是“罪魁祸首”。这通常依赖于数据库的慢查询日志(
slow_query_log
),它记录了执行时间超过阈值的 SQL。但光有日志还不够,
pt-query-digest
这样的工具能帮你把海量的日志数据聚合分析,找出最耗时的、执行次数最多的那些语句。有些时候,慢查询不一定在日志里,它可能是一个高并发下的锁等待,或者一个偶尔出现的复杂查询,这时候就需要实时监控工具,比如
Percona Monitoring and Management (PMM)
或者云服务商提供的数据库性能分析工具,它们能帮你实时捕捉到这些“瞬时”的性能瓶颈。
接着是深入诊断。拿到慢 SQL 语句后,最关键的一步就是使用
EXPLAIN
命令去分析它的执行计划。这就像给 SQL 语句拍了个 X 光片,能看到它走了哪些索引、扫描了多少行、用了什么连接方式。这里面学问就大了,比如
type
字段是
ALL
(全表扫描)还是
ref
/
eq_ref
/
const
(走索引),
rows
字段扫描了多少行,
Extra
字段有没有
Using filesort
或
Using temporary
等效率低下的操作。通过这些信息,你基本就能判断出问题是出在索引缺失、索引失效、SQL 语句写法不当,还是数据量太大导致。
然后是对症优化。索引优化是第一位的。大部分慢 SQL 都和索引有关。你得根据
WHERE
、
JOIN
、
ORDER BY
、
GROUP BY
子句的字段来创建合适的索引,包括单列索引、联合索引,甚至是覆盖索引。但索引不是越多越好,它会增加写入的开销,所以要平衡读写需求。SQL 语句重写也是个大头。比如避免
SELECT *
,只查询需要的字段;优化
JOIN
顺序,小表驱动大表;尽量避免在
WHERE
子句中使用函数、
OR
、
LIKE '%keyword%'
这样的操作,因为它们可能导致索引失效;合理使用
UNION ALL
替代
UNION
(如果不需要去重)。有时候,一个复杂的查询可以拆分成几个简单的查询,或者使用子查询、派生表等方式来优化。数据库结构调整。比如选择合适的数据类型,避免使用过大的字段类型;适当的范式或反范式设计,根据业务场景权衡查询效率和数据冗余。数据库配置调优。这包括调整
innodb_buffer_pool_size
(InnoDB 缓冲池大小)、
tmp_table_size
(临时表大小)、
max_connections
等参数。这些参数的设置需要结合服务器硬件资源和业务负载来决定,没有一劳永逸的配置。应用层优化。有时候慢 SQL 并非数据库本身的问题,而是应用层频繁查询、N+1 问题、或者没有合理利用缓存。引入 Redis 等缓存层,或者对高频查询结果进行缓存,也能大幅减轻数据库压力。
最后,是持续监控与迭代。性能优化不是一次性的任务,业务在发展,数据在增长,新的慢 SQL 随时可能出现。建立完善的监控告警机制,定期分析慢查询日志,并把性能优化融入到开发流程中,比如代码评审时增加 SQL 审查环节,进行压力测试等,才能真正做到“彻底解决”。
如何高效地发现和定位系统中的慢 SQL?
发现和定位慢 SQL,我觉得这事儿有点像侦探破案,得有工具,还得有经验。光凭感觉那是不行的。
最直接的证据来源,肯定是数据库自带的慢查询日志(Slow Query Log)。MySQL 默认是关闭的,你需要去配置文件里把它打开,并且设置一个
long_query_time
的阈值,比如 1 秒。任何执行时间超过这个阈值的 SQL 语句都会被记录下来。但日志文件通常会非常大,人工去翻阅简直是噩梦。这时候,
pt-query-digest
这类工具就显得尤为重要了。它能帮你把海量的慢查询日志聚合、分析,输出一个非常详细的报告,告诉你哪些 SQL 语句是“大户”,它们的平均执行时间、最大执行时间、扫描行数等等,一目了然。我经常用它来快速锁定问题。
光看日志有时还不够,因为有些慢查询可能不是因为执行时间长,而是因为并发高,导致锁等待严重。这时候,实时性能监控工具就派上用场了。比如
Percona Monitoring and Management (PMM)
、
Prometheus + Grafana
搭配
mysqld_exporter
,或者各种云服务商提供的数据库性能监控平台。它们能实时展示数据库的各项指标,比如 QPS、TPS、CPU 利用率、I/O、连接数、锁等待情况等。通过这些曲线图,你能直观地看到数据库在某个时间段的压力情况,然后结合慢查询日志去进一步定位。我个人觉得,这些可视化工具比纯粹的命令行输出更直观,能更快地发现异常峰值。
拿到具体的慢 SQL 语句后,
EXPLAIN
命令就是你的“CT 扫描仪”。这是分析 SQL 执行计划的利器。你把慢 SQL 前面加上
EXPLAIN
,它就会告诉你这条语句是怎么执行的,比如:
id
:查询的序列号。
select_type
:查询类型,是简单查询、子查询还是联合查询。
table
:操作的表。
type
:这是最重要的一个字段,表示连接类型,从好到坏依次是
const
、
eq_ref
、
ref
、
range
、
index
、
ALL
。看到
ALL
(全表扫描)基本就能确定问题了。
possible_keys
:可能用到的索引。
key
:实际用到的索引。
key_len
:实际用到的索引长度。
rows
:预计扫描的行数,这个数字越小越好。
Extra
:额外信息,比如
Using filesort
(需要外部排序,效率低)、
Using temporary
(需要创建临时表,效率低)、
Using index
(覆盖索引,效率高)。
通过
EXPLAIN
的输出,你几乎能“看到”数据库是如何执行你的 SQL 的,进而找出是索引没用上、索引选择不对,还是 SQL 语句写法有问题。有时候,你甚至需要结合
SHOW PROCESSLIST
来查看当前正在执行的 SQL,特别是那些处于
Locked
或
Waiting
状态的,这往往是死锁或长时间锁等待的迹象。
针对不同类型的慢 SQL,有哪些行之有效的优化策略?
解决慢 SQL,就像医生开药方,得看病症。不同类型的慢 SQL,优化策略肯定不一样。我通常会从几个维度去思考。
 文心大模型
文心大模型
百度飞桨-文心大模型 ERNIE 3.0 文本理解与创作
 56 查看详情
56 查看详情 
索引优化:这几乎是解决慢 SQL 的第一道防线。
缺失索引: 这是最常见的。
WHERE
子句、
JOIN
条件、
ORDER BY
、
GROUP BY
中涉及的字段,如果经常作为查询条件,就应该考虑加索引。索引失效: 索引不是万能的,有些操作会导致索引失效。比如在索引列上使用函数(
DATE_FORMAT(create_time, '%Y-%m-%d') = '...'
),或者
LIKE '%keyword%'
这种前缀模糊匹配,都可能让索引形同虚设。还有隐式类型转换,比如
WHERE int_col = 'string'
。遇到这种情况,就要调整 SQL 写法,让索引能被正确利用。选择合适的索引类型: B-tree 索引最常用。对于多列查询,要考虑联合索引,并且注意“最左前缀原则”。如果查询结果的所有列都在索引中,那就是覆盖索引(
EXPLAIN
的
Extra
会显示
Using index
),这种效率极高,因为它不需要回表查询数据。索引不是越多越好: 索引会占用磁盘空间,并且在数据写入(
INSERT
、
UPDATE
、
DELETE
)时会增加维护成本。所以,要定期评估索引的使用情况,删除不常用或重复的索引。
SQL 语句优化:这是考验开发者功力的地方。
*避免 `SELECT `:** 只查询你需要的字段,减少网络传输和 I/O。优化
JOIN
操作: 大多数情况下,小结果集驱动大结果集会更高效。考虑
JOIN
的顺序,以及是否可以替换为
INNER JOIN
、
LEFT JOIN
等。避免笛卡尔积。合理使用
UNION
和
UNION ALL
: 如果不需要去重,用
UNION ALL
效率更高,因为它省去了去重的开销。子查询与
JOIN
的选择: 很多时候子查询可以用
JOIN
来替代,通常
JOIN
的性能会更好,但具体情况要具体分析。
LIMIT
优化: 对于大数据量的分页查询,
LIMIT offset, count
在
offset
很大的时候会非常慢,因为它需要扫描
offset + count
条记录。可以考虑先通过索引定位到起始 ID,再进行分页,比如
SELECT * FROM table WHERE id > (SELECT id FROM table ORDER BY id LIMIT offset, 1) LIMIT count
。避免在
WHERE
子句中使用
OR
: 很多时候
OR
会导致索引失效,可以考虑拆分成多个
UNION ALL
语句。
数据库结构优化:这需要在设计阶段就考虑。
选择合适的数据类型: 比如能用
TINYINT
就不用
INT
,能用
VARCHAR
就不用
TEXT
。这能减少存储空间,进而减少 I/O。范式与反范式的权衡: 范式设计减少数据冗余,但可能导致多表
JOIN
;反范式设计减少
JOIN
,但可能增加数据冗余和一致性维护成本。根据业务查询模式来决定。
数据库配置参数调优:这需要 DBA 或资深运维的经验。
innodb_buffer_pool_size
: 这是 InnoDB 最重要的参数,用于缓存数据和索引。设置得越大,能缓存的数据越多,减少磁盘 I/O。通常设置为物理内存的 50%-80%。
tmp_table_size
和
max_heap_table_size
: 用于内存临时表的大小。如果 SQL 查询中用到
GROUP BY
、
ORDER BY
或
UNION
导致需要创建临时表,并且临时表大小超过这两个参数的最小值,就会转为磁盘临时表,效率会降低。
query_cache_size
: 在 MySQL 8.0 中已被移除。在老版本中,查询缓存可以缓存查询结果,但并发高时可能成为瓶颈。
这些策略不是孤立的,往往需要组合使用。而且,优化是一个迭代的过程,每次调整后都要重新测试和监控,确保真的带来了性能提升。
解决慢 SQL 对系统整体性能和可维护性有何深远影响?
解决慢 SQL,这绝不仅仅是让某个页面加载快一点那么简单,它对整个系统的健康度和未来的可维护性都有着非常深远的影响,甚至可以说,它是保障业务持续增长的基石。
首先,最直接的,也是用户最能感知到的,就是用户体验的显著提升。一个响应迅速的系统,能让用户操作流畅,减少等待焦虑。这直接关系到用户留存率、转化率,甚至品牌形象。想想看,如果一个电商网站每次点击都要等好几秒,用户很快就会流失到竞争对手那里。解决慢 SQL,就是让用户每次操作都像丝滑般流畅。
其次,它能极大地优化系统资源利用率。慢 SQL 就像一个无底洞,会持续占用 CPU、内存和 I/O 资源。一个慢查询可能让 CPU 飙升到 100%,导致其他正常查询也跟着变慢,甚至引发雪崩效应,让整个数据库连接池耗尽。彻底解决这些“资源大户”,能让服务器的 CPU、内存和磁盘 I/O 得到有效释放,意味着可以用更少的硬件资源支撑更大的业务量,这直接关系到成本控制。很多时候,解决慢 SQL 比直接升级硬件性价比高得多。
再者,它显著增强了系统的稳定性和可靠性。慢 SQL 常常是系统崩溃、服务中断的导火索。长时间的慢查询可能导致数据库死锁、连接数耗尽,甚至让整个应用服务崩溃。通过优化慢 SQL,我们消除了这些潜在的“定时炸弹”,让系统在高并发、大数据量下也能保持稳定运行,大大降低了生产事故的风险。这对于任何一个追求高可用的业务来说,都是至关重要的一环。
从可维护性的角度看,解决慢 SQL 也是一种技术债务的偿还。那些低效的 SQL 语句,就像代码中的“坏味道”,不仅影响性能,也让后续的开发和维护变得困难。当一个新的需求过来,如果底层有大量慢 SQL,开发者可能需要花费大量时间去规避或优化这些历史遗留问题,而不是专注于新功能的开发。通过系统性地解决慢 SQL,我们清理了这些技术债务,让代码库更健康,未来的迭代和扩展也更加顺畅。开发者在面对一个性能良好的系统时,也能更自信地进行功能迭代,而不是战战兢兢地担心哪个改动会触发新的性能问题。
最后,它促使团队形成更好的开发习惯和规范。当慢 SQL 问题被重视并得到解决时,团队成员会自然而然地开始关注 SQL 质量、数据库设计和性能优化。这会推动代码评审时对 SQL 语句的审查,在开发阶段就进行性能测试,甚至在数据库表设计时就考虑索引和查询模式。这种“性能优先”的文化一旦建立起来,就能从源头上减少慢 SQL 的产生,形成一个良性循环,让整个开发流程更加健壮和高效。这是一种从“治标”到“治本”的转变,也是团队技术成熟度的体现。
以上就是慢 SQL 彻底解决思路全解析 慢 SQL 彻底解决思路在性能优化中的核心功能与优势的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/596198.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫