
hami 社区在 v2.7.0 版本中正式上线了面向 nvidia gpu 的 拓扑感知调度 功能。该功能旨在应对高性能计算(hpc)与 ai 大模型训练中的多卡通信瓶颈,通过智能任务调度机制,将计算负载精准部署到物理连接最优、通信延迟最低的 gpu 组合上,显著提升任务执行效率和集群整体算力利用率。本文将在介绍功能亮点的基础上,深入源码层面,全面解析 hami 实现 nvidia gpu 拓扑感知调度的设计思路与关键技术。
一、核心功能概览
动态生成拓扑通信分值:Device Plugin 利用 NVML 接口实时探测节点内各 GPU 之间的物理互联方式(如 NVLink、PCIe),并将其转化为可量化的“通信分数”,为调度器提供数据支撑。双模式防碎片化调度策略:Fit 函数内置优化逻辑,针对不同类型的 GPU 请求——无论是多卡并行任务还是单卡独立任务——自动启用“最佳匹配”与“最小破坏”两种策略,兼顾短期性能最大化与长期资源可用性。
二、设计原理剖析
HAMi 的拓扑感知调度机制遵循“先量化、再决策”的设计范式:首先在节点侧将复杂的硬件拓扑结构转化为标准化的数值评分;随后由调度系统结合这些评分做出最优分配决策。  整个流程分为两个关键阶段:拓扑注册 和 调度决策。
整个流程分为两个关键阶段:拓扑注册 和 调度决策。
阶段一:拓扑注册 —— 将物理连接数字化
目标是将隐藏于硬件层的 GPU 互连关系,转换为软件可识别的数字指标。
拓扑信息采集:每个 GPU 节点上的 Device Plugin 使用 NVIDIA 提供的 NVML 库,遍历所有 GPU 设备对,获取它们之间的直连类型(例如是否通过 NVLink 或 PCIe 相连)。建模与打分机制:构建拓扑图:代码在内存中构造一个完整的 GPU 连接图谱,记录每对设备间的链路详情。分数映射规则:依据预设评分标准(如 SingleNVLINKLink 计 100 分,P2PLinkCrossCPU 计 10 分),算法遍历该图谱,为任意两块 GPU 之间生成一个综合通信能力得分。输出结果 —— 设备通信分表:最终形成一张“设备通信分表”,其中包含每个 GPU 的 UUID 及其与其他 GPU 的通信分数,并通过 Kubernetes 节点 Annotation 上报至控制面。
阶段二:调度决策 —— 智能选择最优设备组合
当调度器需要为 Pod 分配 GPU 资源时,会将请求转发给设备端的 Fit 函数,并携带当前节点的“通信分表”进行辅助判断。
初步筛选:Fit 函数首先排除不满足显存、算力等基础条件的 GPU。智能寻优:基于剩余候选设备及其通信分数,运行融合“最佳匹配”与“最小破坏”原则的优化算法,计算出最合适的设备组合返回给调度器。
三、实现细节:源码级深度解读
1. 拓扑发现与分数生成
拓扑感知的核心在于准确捕捉设备间的真实连接状态,并将其转化为可参与调度决策的数值。整个过程由 Device Plugin 在本地完成。
拓扑图构建 ( build() function):
主要逻辑位于 pkg/device/nvidia/calculate_score.go 中的 build() 函数。它并非简单生成邻接矩阵,而是:
初始化设备列表:创建 DeviceList,每个 Device 包含一个空的 Links 映射(map[int][]P2PLink)。双重循环填充连接信息:遍历所有 GPU 对 (d1, d2),调用 GetP2PLink 与 GetNVLink(定义于 links.go)获取连接详情。聚合链路数据:将检测到的所有连接(包括 PCIe 和 NVLink)以 P2PLink 结构体形式追加至对应设备的 Links 字段中,从而在内存中构建出完整的拓扑网络。
通信分数计算 ( calculateGPUPairScore() function):
在拓扑图建立后,calculateGPUScore 调用 calculateGPUPairScore 将连接关系量化为具体分数。
函数遍历两个 GPU 之间的所有链路类型,根据 switch 分支累加得分。例如:P2PLinkSameBoard 加 60 分,SingleNVLINKLink 加 100 分,TwoNVLINKLinks 加 200 分,最终返回总和作为两者通信质量评分。
// File: pkg/device/nvidia/calculate_score.gofunc (o *deviceListBuilder) build() (DeviceList, error) { // ... // 1. 初始化扁平化 DeviceList var devices DeviceList for i, d := range nvmlDevices { // ... create device object ... devices = append(devices, device) } // 2. 遍历并填充 Links map for i, d1 := range nvmlDevices { for j, d2 := range nvmlDevices { if i != j { // 获取并追加 P2P Link 信息 p2plink, _ := GetP2PLink(d1, d2) devices[i].Links[j] = append(devices[i].Links[j], P2PLink{devices[j], p2plink}) // 获取并追加 NVLink 信息 nvlink, _ := GetNVLink(d1, d2) devices[i].Links[j] = append(devices[i].Links[j], P2PLink{devices[j], nvlink}) } } } return devices, nil
}
 度加剪辑
度加剪辑
度加剪辑(原度咔剪辑),百度旗下AI创作工具
 63 查看详情
63 查看详情 
func calculateGPUPairScore(gpu0 Device, gpu1 Device) int {score := 0for _, link := range gpu0.Links[gpu1.Index] {switch link.Type {case P2PLinkCrossCPU: score += 10// ... (etc) ...case SingleNVLINKLink: score += 100// ... (etc) ...}}return score}
2. 设备端调度逻辑:双策略优化选择
核心调度逻辑实现在 pkg/device/nvidia/device.go 的 Fit() 函数中。当检测到启用了拓扑感知策略后,会根据请求的 GPU 数量切换不同的优化路径。
// File: pkg/device/nvidia/device.gofunc (nv *NvidiaGPUDevices) Fit(...) {// ...needTopology := util.GetGPUSchedulerPolicyByPod(device.GPUSchedulerPolicy, pod) == util.GPUSchedulerPolicyTopology.String()// ... // 过滤出符合资源要求的空闲 GPU (tmpDevs) // ... if needTopology { if len(tmpDevs[k.Type]) > int(originReq) { if originReq == 1 { // 单卡任务:采用“最小破坏”策略 lowestDevices := computeWorstSignleCard(nodeInfo, request, tmpDevs) tmpDevs[k.Type] = lowestDevices } else { // 多卡任务:采用“最佳匹配”策略 combinations := generateCombinations(request, tmpDevs) combination := computeBestCombination(nodeInfo, combinations) tmpDevs[k.Type] = combination } return true, tmpDevs, "" } } // ...
}
Fit 函数的整体调度流程如下图所示:
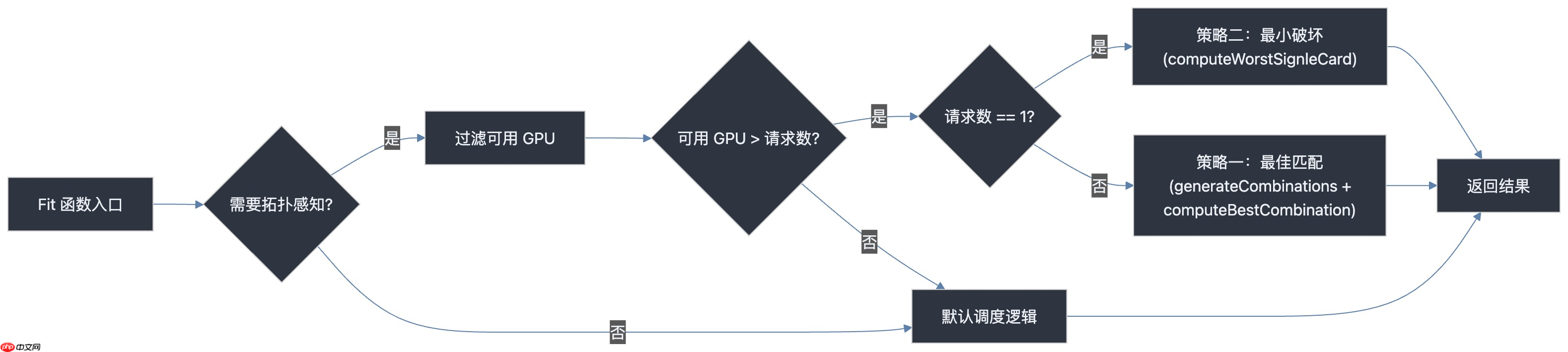
策略一:多卡任务 —— “最佳匹配”优先
对于请求多个 GPU 的任务,目标是选出内部通信总分最高的设备组合。
实现方式:先筛选出所有满足资源条件的空闲 GPU。调用 generateCombinations 枚举所有可能的设备组合。使用 computeBestCombination 遍历各组合,基于“通信分表”计算每组内所有设备对之间的分数总和。返回总分最高的组合,确保任务运行在通信效率最佳的 GPU 子集上。
其核心逻辑示意图如下:
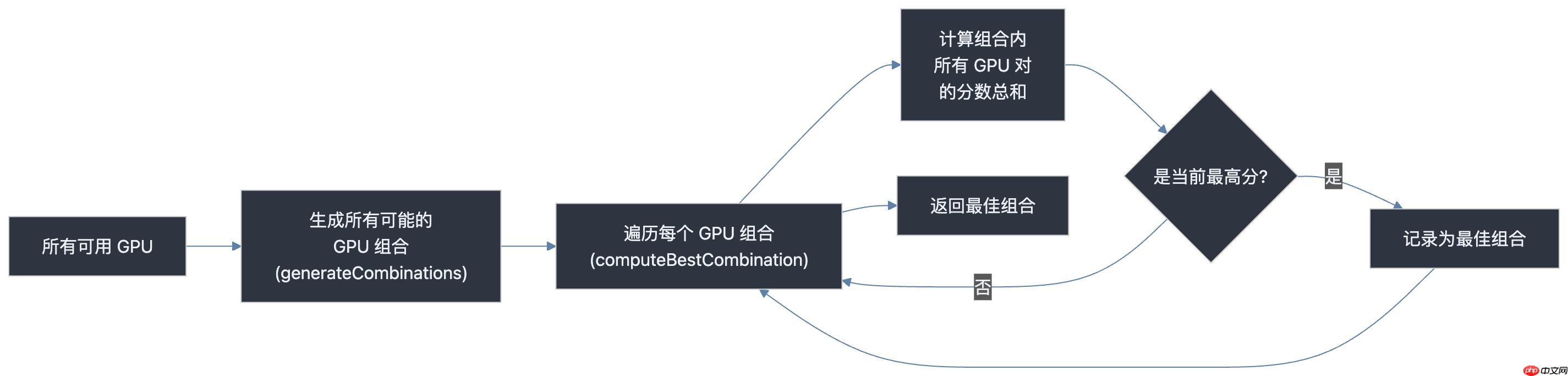
策略二:单卡任务 —— “最小破坏”优先
对于仅申请一块 GPU 的任务,策略转为保护整体拓扑完整性,避免占用关键连接节点。
实现方式:调用 computeWorstSignleCard 函数。遍历所有可用 GPU,计算每张卡与其他可用卡的通信分数总和。选择总分最低的 GPU,通常这类卡处于拓扑边缘位置,对其分配不会影响未来多卡任务的调度质量。
其核心逻辑示意如下:
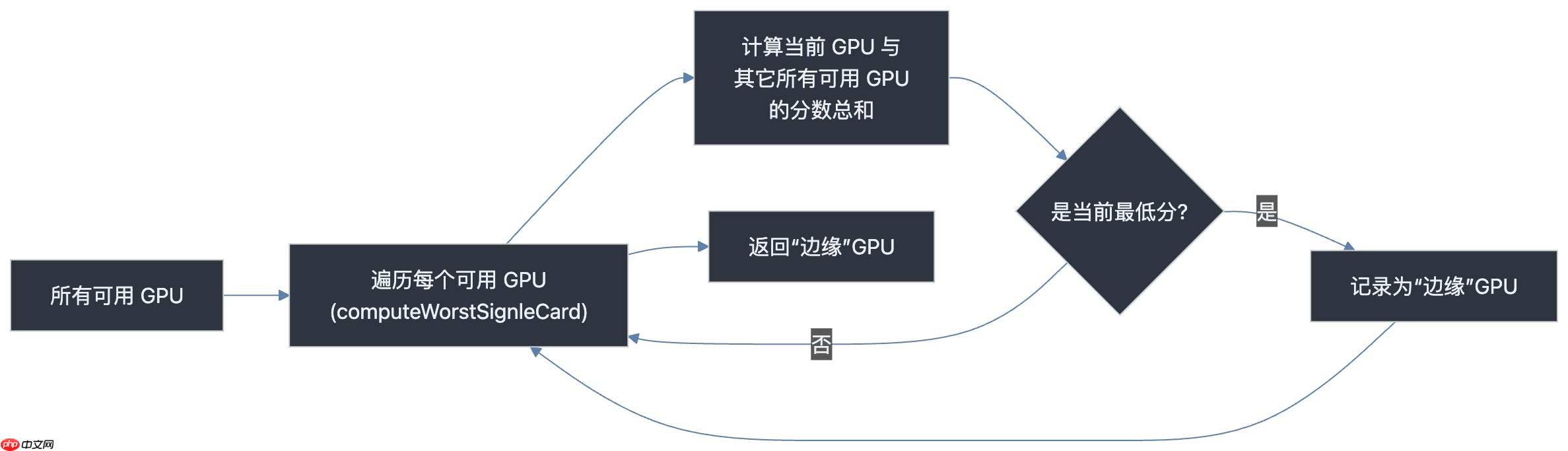
四、使用方法说明
用户只需添加一条 Annotation 即可激活拓扑感知调度功能,系统将根据请求的 GPU 数量自动应用相应策略。
apiVersion: v1kind: Podmetadata:name: gpu-topology-aware-jobannotations:启用拓扑感知调度
hami.io/gpu-scheduler-policy: "topology-aware"# 系统将自动:# - 为多卡任务选择通信最优的 GPU 组合# - 为单卡任务选择对拓扑影响最小的设备
spec:containers:
name: cuda-containerimage: nvidia/cuda:11.6.2-base-ubuntu20.04command: ["sleep", "infinity"]resources:limits:
请求4个GPU
nvidia.com/gpu: "4"
五、总结
HAMi 实现的 NVIDIA GPU 拓扑感知调度,展现了清晰而前瞻的工程设计理念:以动态感知替代静态配置,以全局优化取代局部贪心。设备端集成的双策略寻优算法,在消费预先计算的“通信分数”基础上,既保障了单个任务的极致性能表现,又维护了集群资源的长期可用性与调度灵活性。这一机制为云原生环境下大规模 AI 训练与科学计算任务提供了强有力的底层支持。
参考资料
- 设计文档:NVIDIA GPU Topology Scheduler
- 使用文档:NVIDIA GPU 拓扑调度启用指南
- 相关 PRs:
再次诚挚感谢社区贡献者 @lengrongfu、@fyp711 对本特性的开发与推动!
以上就是【原理解析】HAMi × NVIDIA | GPU 拓扑感知调度实现详解的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/604176.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















