☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

3 月 28 日消息,根据 lmsys org 公布的最新基准测试报告,claude-3 得分以微弱优势超越 gpt-4,成为该平台“最佳”大语言模型。
本网站首先介绍下LMSYS Org,该机构是由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创建的研究组织。
该系统推出Chatbot Arena,这是一个针对大型语言模型(LLM)的基准平台,以众包方式匿名、随机对抗测试大模型产品,其评级基于国际象棋等竞技游戏中广泛使用的Elo评分系统。
通过用户投票产生的评分结果,系统每次会随机选择两个不同的大模型机器人和用户聊天,并让用户在匿名的情况下选择哪款大模型产品的表现更好一些,整体而言相对公正。
Chatbot Arena 自去年上线以来,GPT-4 一直稳居头把交椅,甚至成为了评估大模型的黄金标准。
 豆包大模型
豆包大模型
字节跳动自主研发的一系列大型语言模型
 834 查看详情
834 查看详情 
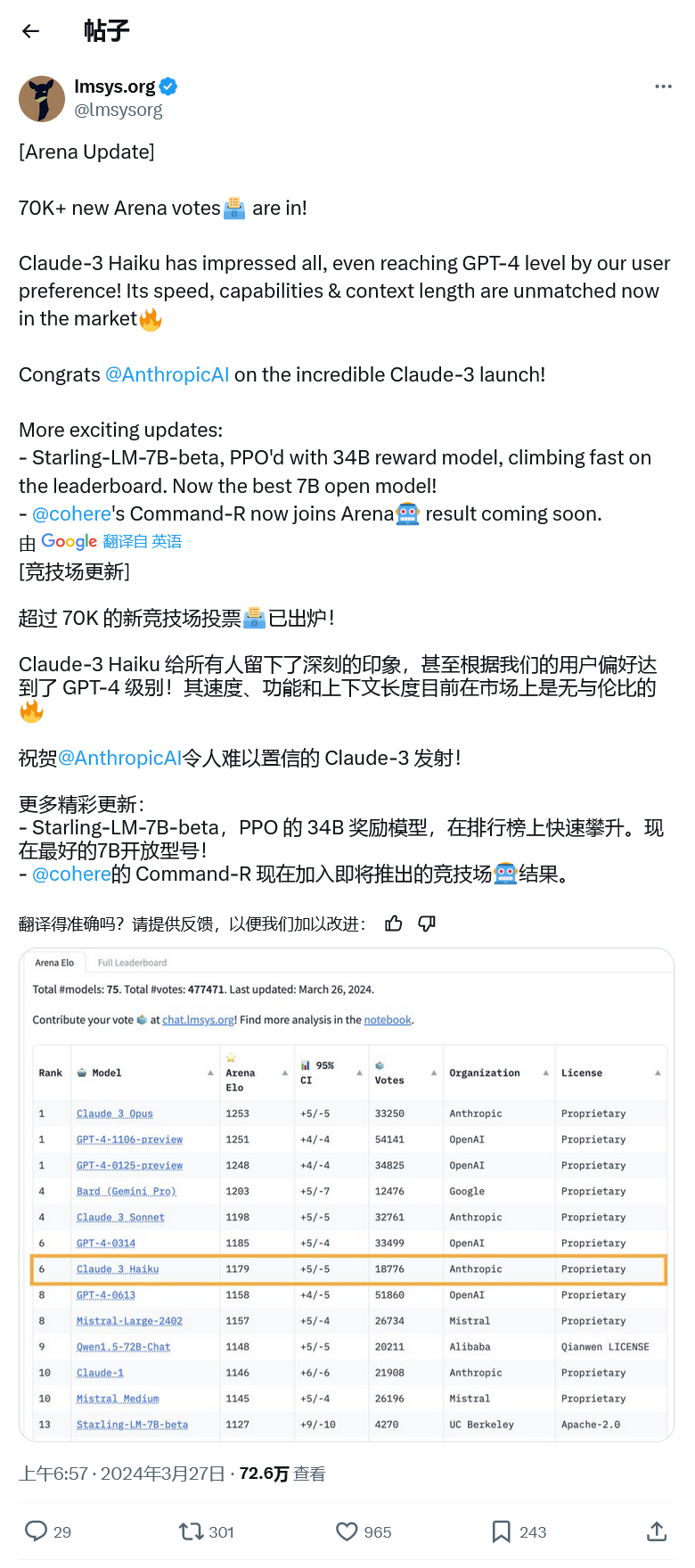
不过昨天 Anthropic 的 Claude 3 Opus 以 1253 比 1251 的微弱优势击败了 GPT-4,OpenAI 的 LLM 被挤下了榜首位置。由于比分过于接近,出于误差率方面的考量,该机构让 Claude 3 和 GPT-4 并列第一,GPT-4 的另一个预览版也并列第一。

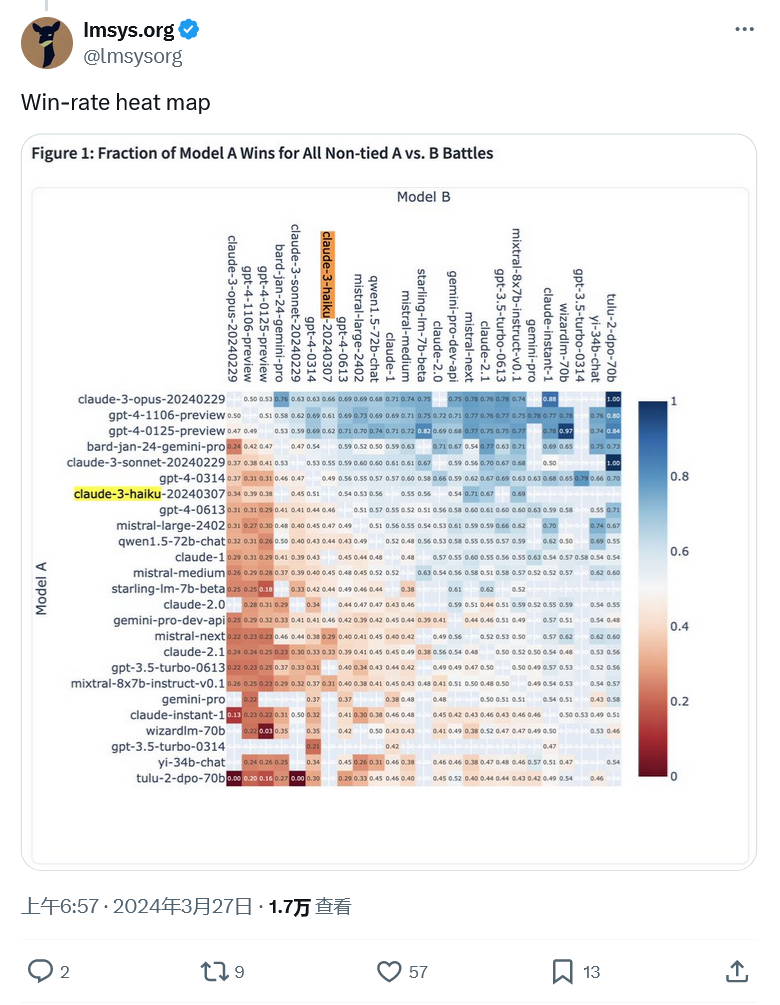
更令人印象深刻的是 Claude 3 Haiku 进入前十名。Haiku 是 Anthropic 的 local size 模型,相当于谷歌的 Gemini Nano。
它比拥有数万亿参数的 Opus 要小得多,因此相比之下速度要快得多。根据 LMSYS 的数据,Haiku 在排行榜上名列第七,有媲美 GPT-4 的表现。
以上就是和 GPT-4 并列第一,LMSYS 基准测试显示 Claude-3 模型表现优异的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/618140.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫