
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。事件抽取是信息抽取的一种,其目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于百度自研模型ERNIE进行事件抽取任务
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。事件抽取是信息抽取的一种,其目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围。
图1展示了一个关于事件抽取的样例,可以看到原句子描述中一共计包含了2个事件类型event_type:胜负和夺冠,其中对于胜负事件类型,论元角色role包含时间,胜者,败者,赛事名称;对于夺冠事件类型,论元角色role包含夺冠事件,夺冠赛事,冠军。总而言之,事件抽取期望从这样非结构化的文本描述中,提取出事件类型和元素角色的结构化信息。
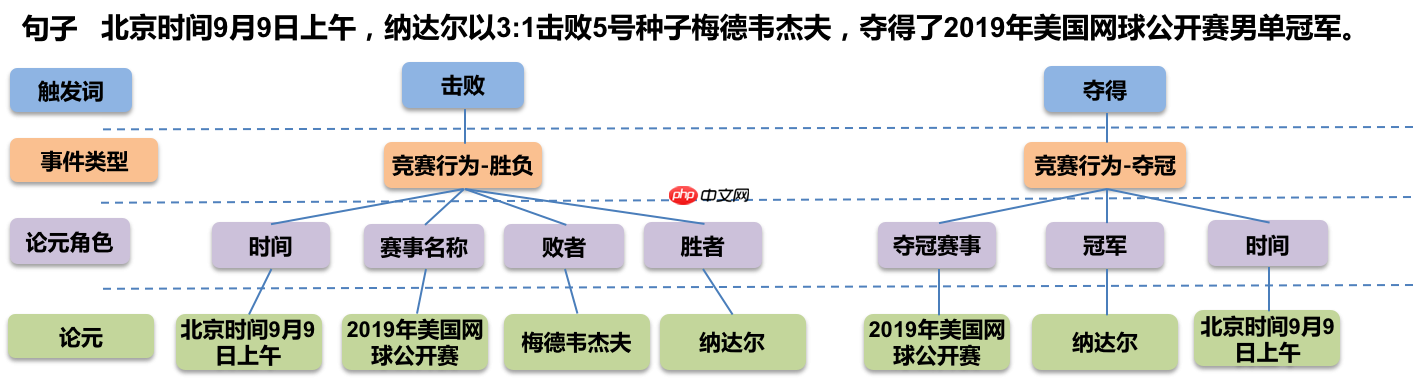 图1 事件抽取样例
图1 事件抽取样例
本案例将基于ERNIE模型,在DuEE 1.0数据集上进行事件抽取任务。
学习资源
更多的深度学习资料,比如深度学习知识,论文解读,实践案例等,请参考:awesome-DeepLearning更多飞桨框架相关资料,请参考:飞桨深度学习平台
⭐ ⭐ ⭐ 欢迎点个小小的Star,开源不易,希望大家多多支持~⭐ ⭐ ⭐

1. 方案设计
本实践设计方案如图2所示,本案例将采用分阶段地方式,分别训练触发词识别和事件元素识别两个模型去抽取对应的触发词和事件元素。模型的输入是一串描述事件的文本,模型的输出是从事件描述中提取的事件类型,事件元素等信息。
具体而言,在建模过程中,对于输入的待分析事件描述文本,首先需要进行数据处理生成规整的文本序列数据,包括语句分词、将词转换为id,过长文本截断、过短文本填充等等操作;然后,将规整的数据传到触发词识别模型中,识别出事件描述中的触发词,并且根据触发词判断该事件的类型;接下来,将规整的数据继续传入事件元素识别模型中,并确定这些事件元素的角色;最后将两个模型的输出内容进行汇总,获得最终的提取事件结果,其将主要包括事件类型,事件元素和事件角色。
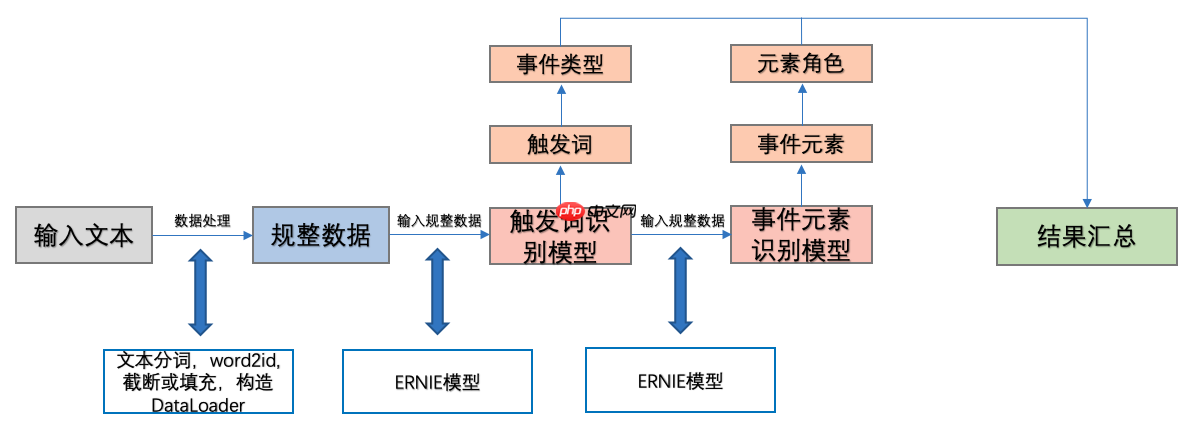 图2 事件提取设计方案
图2 事件提取设计方案
其中本案例中我们将触发词识别模型和事件元素模型定义为序列标注任务,两者均将采用ERNIE模型完成数据标注任务,从而分别抽取出事件类型和事件元素,后续会将两者的结果进行汇总,得到最终的事件提取结果。
对于触发词抽取模型,该部分主要是给定事件类型,识别句子中出现的事件触发词对应的位置以及对应的事件类别,模型原理图如下:
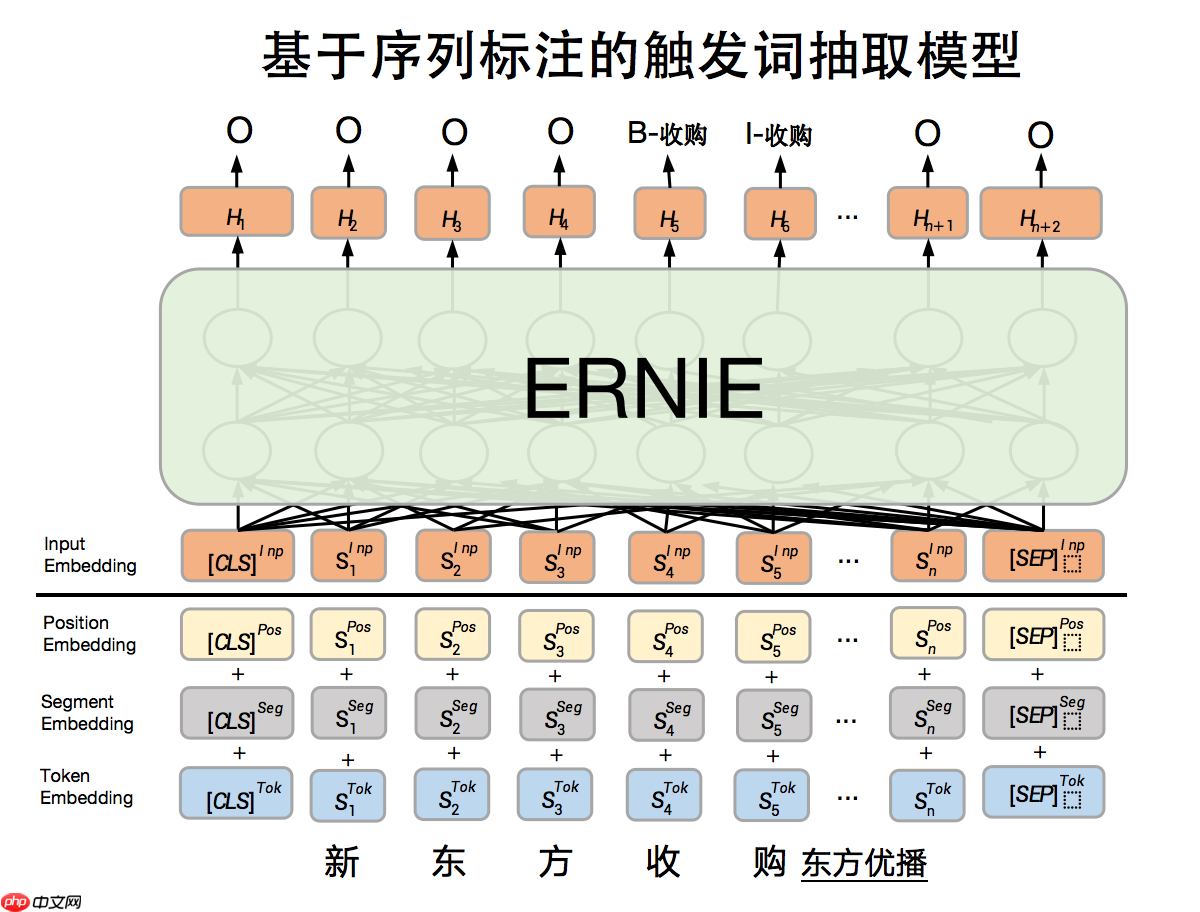 图3 触发词抽取模型图
图3 触发词抽取模型图
可以看到上述样例中通过模型识别出:1)触发词”收购”,并分配标签”B-收购”、”I-收购”。同样地,对于论元抽取模型,该部分主要是识别出事件中的论元以及对应论元角色,模型原理图如下:
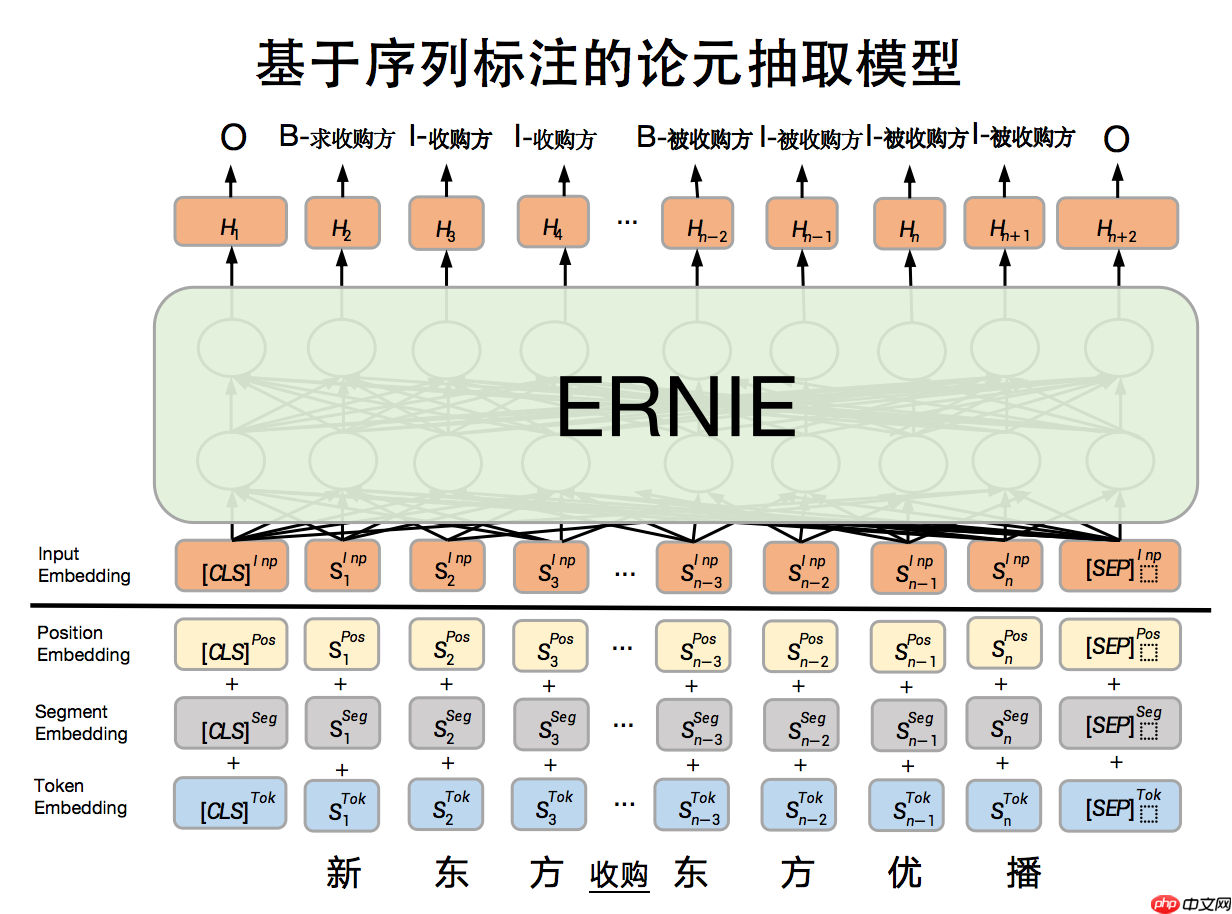 图4 论元抽取模型
图4 论元抽取模型
可以看到上述样例中通过模型识别出:1)触发词”新东方”,并分配标签”B-收购方”、”I-收购方”、”I-收购方”;2)论元”东方优播”, 并分配标签”B-被收购方”、”I-被收购方”、”I-被收购方”、”I-被收购方”。
2. 数据处理
2.1 数据集介绍
DuEE 1.0是百度发布的中文事件抽取数据集,包含65个事件类型的1.7万个具有事件信息的句子(2万个事件)。事件类型根据百度风云榜的热点榜单选取确定,具有较强的代表性。65个事件类型中不仅包含「结婚」、「辞职」、「地震」等传统事件抽取评测中常见的事件类型,还包含了「点赞」等极具时代特征的事件类型。具体的事件类型及对应角色见表3。数据集中的句子来自百度信息流资讯文本,相比传统的新闻资讯,文本表达自由度更高,事件抽取的难度也更大。
在实验之前,请确保下载DuEE1.0数据,并将其解压后的如下四个数据文件放在./dataset目录下:
duee_train.json: 原训练集数据文件duee_dev.json: 原开发集数据文件duee_test.json: 原测试集数据文件duee_event_schema.json: DuEE1.0事件抽取模式文件,其定义了事件类型和事件元素角色等内容
其中单条样本的格式如下所示:
{ "text":"华为手机已经降价,3200万像素只需千元,性价比小米无法比。", "id":"2d41b63e42127b9e8e0416484e9ebd05", "event_list":[ { "event_type":"财经/交易-降价", "trigger":"降价", "trigger_start_index":6, "arguments":[ { "argument_start_index":0, "role":"降价方", "argument":"华为", "alias":[ ] }, { "argument_start_index":2, "role":"降价物", "argument":"手机", "alias":[ ] } ], "class":"财经/交易" } ]}
2.2 数据加载
从上边展示的样例可以看到,我们无法将这样的数据直接传入模型中,这样的数据格式离我们模型的输入格式差别还比较大,因此我将基于这些原数据生成适合加载和训练的中间数据格式,如图6所示。我们将原始的数据进行处理分别生成用于触发词识别和事件元素识别的数据,分别存放于./dataset/trigger和./dataset/role目录下,同时根据duee_event_schema.json生成两种模型所用的词典,存放于./dataset/dict目录下。
 图6 数据处理成中间格式数据样例
图6 数据处理成中间格式数据样例
在将数据处理成中间格式数据之后,便可以调用数据加载函数将中间数据加载至内存之中,相关代码如下。
In [1]
import osimport randomimport numpy as npfrom functools import partialfrom seqeval.metrics.sequence_labeling import get_entitiesimport paddleimport paddle.nn.functional as Ffrom paddlenlp.datasets import load_datasetfrom paddlenlp.transformers import ErnieTokenizer, ErnieModel, LinearDecayWithWarmupfrom paddlenlp.data import Stack, Pad, Tuplefrom paddlenlp.metrics import ChunkEvaluatorfrom utils.utils import set_seed, format_printfrom utils.data import data_prepare, read, convert_example_to_features, load_dict, load_schema# convert original DuEE dataset to intermediate formatdata_prepare("./dataset")# load trigger data to memorytrigger_dict_path = "./dataset/dict/trigger.dict"trigger_train_path = "./dataset/trigger/duee_train.tsv"trigger_dev_path = "./dataset/trigger/duee_train.tsv"trigger_tag2id, trigger_id2tag = load_dict(trigger_dict_path)trigger_train_ds = load_dataset(read, data_path=trigger_train_path, lazy=False)trigger_dev_ds = load_dataset(read, data_path=trigger_dev_path, lazy=False)# load role data to memoryrole_dict_path = "./dataset/dict/role.dict"role_train_path = "./dataset/role/duee_train.tsv"role_dev_path = "./dataset/role/duee_train.tsv"role_tag2id, role_id2tag = load_dict(role_dict_path)role_train_ds = load_dataset(read, data_path=role_train_path, lazy=False)role_dev_ds = load_dataset(read, data_path=role_dev_path, lazy=False)
2.3 将数据转换成特征形式
在将数据加载完成后,接下来,我们将触发词数据和事件元素数据转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的ErnieTokenizer,其将帮助我们完成这个字符串到字典id的转换。
In [ ]
model_name = "ernie-1.0"max_seq_len = 300batch_size = 32tokenizer = ErnieTokenizer.from_pretrained(model_name)# convert trigger data to featurestrigger_trans_func = partial(convert_example_to_features, tokenizer=tokenizer, tag2id=trigger_tag2id, max_seq_length=max_seq_len, pad_default_tag="O", is_test=False)trigger_train_ds = trigger_train_ds.map(trigger_trans_func, lazy=False)trigger_dev_ds = trigger_dev_ds.map(trigger_trans_func, lazy=False)# conver role data to featuresrole_trans_func = partial(convert_example_to_features, tokenizer=tokenizer, tag2id=role_tag2id, max_seq_length=max_seq_len, pad_default_tag="O", is_test=False)role_train_ds = role_train_ds.map(role_trans_func, lazy=False)role_dev_ds = role_dev_ds.map(role_trans_func, lazy=False)
2.4 构造DataLoader
接下来,我们需要构造触发词数据和事件元素数据的DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
In [ ]
batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type Stack(), # seq len Pad(axis=0, pad_val=-1) # tag_ids ): fn(samples)# construct trigger dataloadertrigger_train_batch_sampler = paddle.io.DistributedBatchSampler(trigger_train_ds, batch_size=batch_size, shuffle=True)trigger_dev_batch_sampler = paddle.io.DistributedBatchSampler(trigger_dev_ds, batch_size=batch_size, shuffle=False)trigger_train_loader = paddle.io.DataLoader(trigger_train_ds, batch_sampler=trigger_train_batch_sampler, collate_fn=batchify_fn)trigger_dev_loader = paddle.io.DataLoader(trigger_dev_ds, batch_sampler=trigger_dev_batch_sampler, collate_fn=batchify_fn)# construct role dataloderrole_train_batch_sampler = paddle.io.DistributedBatchSampler(role_train_ds, batch_size=batch_size, shuffle=True)role_dev_batch_sampler = paddle.io.DistributedBatchSampler(role_dev_ds, batch_size=batch_size, shuffle=False)role_train_loader = paddle.io.DataLoader(role_train_ds, batch_sampler=role_train_batch_sampler, collate_fn=batchify_fn)role_dev_loader = paddle.io.DataLoader(role_dev_ds, batch_sampler=role_dev_batch_sampler, collate_fn=batchify_fn)
3 模型构建
本案例中,我们将基于ERNIE实现图5所展示的序列标注功能。具体来讲,我们将处理好的文本数据输入ERNIE模型中,ERNIE将会对文本的每个token进行编码,产生对应向量序列,然后根据每个token位置的向量进行分类以获得相应位置的序列标签。相应代码如下。
In [ ]
import paddleimport paddle.nn as nnclass ErnieForTokenClassification(paddle.nn.Layer): def __init__(self, ernie, num_classes=2, dropout=None): super(ErnieForTokenClassification, self).__init__() self.num_classes = num_classes self.ernie = ernie self.dropout = nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"]) self.classifier = nn.Linear(self.ernie.config["hidden_size"], num_classes) def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None): sequence_output, _ = self.ernie(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask) sequence_output = self.dropout(sequence_output) logits = self.classifier(sequence_output) return logits
4. 训练配置
定义触发词模型和事件元素识别模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
In [ ]
# model hyperparameter settingnum_epoch = 20learning_rate = 5e-5weight_decay = 0.01warmup_proportion = 0.1log_step = 20eval_step = 100seed = 1000save_path = "./checkpoint"use_gpu = True if paddle.get_device().startswith("gpu") else Falseif use_gpu: paddle.set_device("gpu:0")# trigger model settingtrigger_model = ErnieForTokenClassification(ErnieModel.from_pretrained(model_name), num_classes=len(trigger_tag2id))trigger_num_training_steps = len(trigger_train_loader) * num_epochtrigger_lr_scheduler = LinearDecayWithWarmup(learning_rate, trigger_num_training_steps, warmup_proportion)trigger_decay_params = [p.name for n, p in trigger_model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]trigger_optimizer = paddle.optimizer.AdamW(learning_rate=trigger_lr_scheduler, parameters=trigger_model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in trigger_decay_params)trigger_metric = ChunkEvaluator(label_list=trigger_tag2id.keys(), suffix=False)# role model settingrole_model = ErnieForTokenClassification(ErnieModel.from_pretrained(model_name), num_classes=len(role_tag2id))role_num_training_steps = len(role_train_loader) * num_epochrole_lr_scheduler = LinearDecayWithWarmup(learning_rate, role_num_training_steps, warmup_proportion)role_decay_params = [p.name for n, p in role_model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]role_optimizer = paddle.optimizer.AdamW(learning_rate=role_lr_scheduler, parameters=role_model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in role_decay_params)role_metric = ChunkEvaluator(label_list=role_tag2id.keys(), suffix=False)
5. 模型训练与评估
本节我们将定义一个通用的train函数和evaluate函数,通过指定”trigger”和”role”参数便可以训练相应的模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。
In [ ]
# start to evaluate modeldef evaluate(model, data_loader, metric): model.eval() metric.reset() for batch_data in data_loader: input_ids, token_type_ids, seq_lens, tag_ids = batch_data logits = model(input_ids, token_type_ids) preds = paddle.argmax(logits, axis=-1) n_infer, n_label, n_correct = metric.compute(seq_lens, preds, tag_ids) metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy()) precision, recall, f1_score = metric.accumulate() return precision, recall, f1_score# start to train modeldef train(model_flag): # parse model_flag assert model_flag in ["trigger", "role"] if model_flag == "trigger": model = trigger_model train_loader, dev_loader = trigger_train_loader, trigger_dev_loader optimizer, lr_scheduler, metric = trigger_optimizer, trigger_lr_scheduler, trigger_metric tag2id, num_training_steps = trigger_tag2id, trigger_num_training_steps else: model = role_model train_loader, dev_loader = role_train_loader, role_dev_loader optimizer, lr_scheduler, metric = role_optimizer, role_lr_scheduler, role_metric tag2id, num_training_steps = role_tag2id, role_num_training_steps global_step, best_f1 = 0, 0. model.train() for epoch in range(1, num_epoch+1): for batch_data in train_loader: input_ids, token_type_ids, seq_len, tag_ids = batch_data # logits: [batch_size, seq_len, num_tags] --> [batch_size*seq_len, num_tags] logits = model(input_ids, token_type_ids).reshape([-1, len(tag2id)]) loss = paddle.mean(F.cross_entropy(logits, tag_ids.reshape([-1]), ignore_index=-1)) loss.backward() lr_scheduler.step() optimizer.step() optimizer.clear_grad() if global_step > 0 and global_step % log_step == 0: print(f"{model_flag} - epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}") if global_step > 0 and global_step % eval_step == 0: precision, recall, f1_score = evaluate(model, dev_loader, metric) model.train() if f1_score > best_f1: print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1_score:.5f}") best_f1 = f1_score paddle.save(model.state_dict(), f"{save_path}/{model_flag}_best.pdparams") print(f'{model_flag} evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1_score:.5f} current best {best_f1:.5f}') global_step += 1 paddle.save(model.state_dict(), f"{save_path}/{model_flag}_final.pdparams")# train trigger modeltrain("trigger")print("training trigger end!")# train role modeltrain("role")print("training role end!")
6. 模型推理
实现一个模型预测的函数,实现任意输入一串事件描述,如:”华为手机已经降价,3200万像素只需千元,性价比小米无法比!”,期望能够输出这段描述蕴含的事件。首先我们先加载训练好的模型参数,然后进行推理。相关代码如下。
In [ ]
# load tokenizer model_name = "ernie-1.0"tokenizer = ErnieTokenizer.from_pretrained(model_name)# load schemaschema_path = "./dataset/duee_event_schema.json"schema = load_schema(schema_path)# load dict trigger_tag_path = "./dataset/dict/trigger.dict"trigger_tag2id, trigger_id2tag = load_dict(trigger_tag_path)role_tag_path = "./dataset/dict/role.dict"role_tag2id, role_id2tag = load_dict(role_tag_path)# load trigger modeltrigger_model_path = "./checkpoint/trigger_best.pdparams"trigger_state_dict = paddle.load(trigger_model_path)trigger_model = ErnieForTokenClassification(ErnieModel.from_pretrained(model_name), num_classes=len(trigger_tag2id))trigger_model.load_dict(trigger_state_dict)# load role modelrole_model_path = "./checkpoint/role_best.pdparams"role_state_dict = paddle.load(role_model_path)role_model = ErnieForTokenClassification(ErnieModel.from_pretrained(model_name), num_classes=len(role_tag2id))role_model.load_dict(role_state_dict)
In [ ]
def predict(input_text, trigger_model, role_model, tokenizer, trigger_id2tag, role_id2tag, schema): trigger_model.eval() role_model.eval() splited_input_text = list(input_text.strip()) features = tokenizer(splited_input_text, is_split_into_words=True, max_seq_len=max_seq_len, return_length=True) input_ids = paddle.to_tensor(features["input_ids"]).unsqueeze(0) token_type_ids = paddle.to_tensor(features["token_type_ids"]).unsqueeze(0) seq_len = features["seq_len"] trigger_logits = trigger_model(input_ids, token_type_ids) trigger_preds = paddle.argmax(trigger_logits, axis=-1).numpy()[0][1:seq_len] trigger_preds = [trigger_id2tag[idx] for idx in trigger_preds] trigger_entities = get_entities(trigger_preds, suffix=False) role_logits = role_model(input_ids, token_type_ids) role_preds = paddle.argmax(role_logits, axis=-1).numpy()[0][1:seq_len] role_preds = [role_id2tag[idx] for idx in role_preds] role_entities = get_entities(role_preds, suffix=False) events = [] visited = set() for event_entity in trigger_entities: event_type, start, end = event_entity if event_type in visited: continue visited.add(event_type) events.append({"event_type":event_type, "trigger":"".join(splited_input_text[start:end+1]), "arguments":[]}) for event in events: role_list = schema[event["event_type"]] for role_entity in role_entities: role_type, start, end = role_entity if role_type not in role_list: continue event["arguments"].append({"role":role_type, "argument":"".join(splited_input_text[start:end+1])}) format_print(events)text = "华为手机已经降价,3200万像素只需千元,性价比小米无法比!"predict(text, trigger_model, role_model, tokenizer, trigger_id2tag, role_id2tag, schema)
7. 更多深度学习资源
7.1 一站式深度学习平台awesome-DeepLearning
深度学习入门课 深度学习百问
深度学习百问 特色课
特色课 产业实践
产业实践
以上就是基于百度自研模型ERNIE进行事件抽取任务的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/62706.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























