
巧文书AI官网是https://www.qiaowenshu.com,该平台利用AI技术智能解析招标文件、一键生成标书,集成海量模板与AI绘图工具,支持全托管编写、企业知识库对接,并保障数据安全,适用于各类招投标项目。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
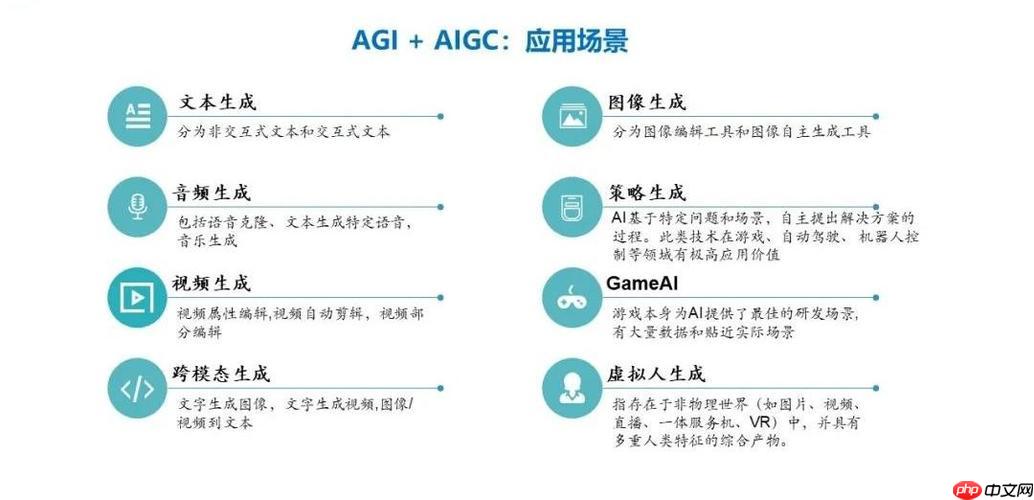
巧文书AI官方网站主页地址在哪里?这是不少网友都关注的,接下来由PHP小编为大家带来巧文书AI官网链接入口,感兴趣的网友一起随小编来瞧瞧吧!
https://www.qiaowenshu.com
平台核心功能介绍
1、支持通过自然语言处理技术快速解析招标文件内容,帮助用户精准提取关键信息点。
2、内置海量标书模板资源库,可根据不同行业与项目类型智能匹配生成初稿内容。
3、提供一键式标书生成服务,涵盖技术方案、商务条款、资质证明等多个组成部分。
4、具备企业知识库对接能力,可将过往成功案例自动归档并用于新项目的参考编写。
5、集成AI图形绘制工具,能够根据文本描述自动生成流程图、组织架构图等配套图表。

智能化操作体验优势
1、系统支持全托管模式运行,用户只需输入基础需求即可完成从框架搭建到细节填充的全过程。
2、采用深度学习算法对历史中标标书进行分析,提升新文档的逻辑性与竞争力表现。
3、允许用户自定义编写思路和结构层级,灵活调整目录顺序与段落布局以满足特定要求。
 巧文书
巧文书
巧文书是一款AI写标书、AI写方案的产品。通过自研的先进AI大模型,精准解析招标文件,智能生成投标内容。
 61 查看详情
61 查看详情 
4、配备实时问答交互模块,可在写作过程中随时提出问题并获得针对性建议与补充材料。
5、操作界面简洁直观,无需专业培训即可上手使用,大幅降低人工编标的入门门槛。

数据安全与使用范围说明
1、所有用户数据均存储于独立账户空间内,支持多重加密防护机制保障信息不外泄。
2、适用于各类工程建设、信息化项目、政府采购等领域的投标文书制作场景。
3、支持企业证书管理功能,可集中维护资质文件、人员履历、业绩清单等核心资料。
4、系统定期更新标讯数据库,覆盖全国主要公共资源交易平台发布的最新招标公告。
5、提供内容独创性检测机制,避免因重复率过高影响评标环节的合规性审查结果。
以上就是巧文书AI官方网站主页地址 巧文书AIAI文本创作官网链接入口的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/634148.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























