程序在多线程环境下,并非线程开得越多运行得越快,当线程数量超过某个临界点后,其性能之所以会不升反降,甚至变得更慢,其根源在于线程的“管理成本”超过了其“并行计算”所带来的收益。这背后,隐藏着一系列复杂的系统性开销和理论限制,主要涵盖五个方面:高昂的“线程上下文切换”开销、过度的“锁竞争”与“同步”等待、任务中“无法并行”部分的限制(阿姆达尔定律)、共享硬件资源(如缓存、内存带宽)的争抢、以及线程数量超过“物理核心”数导致的“空转”。
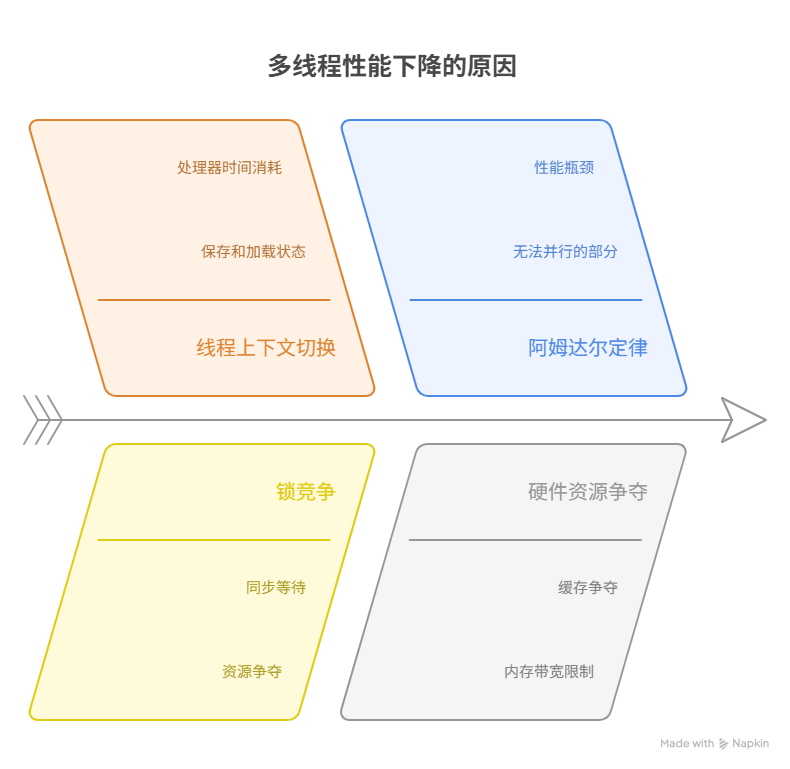

其中,高昂的“线程上下文切换”开销,是导致性能下降的最直接、最普遍的原因。操作系统在切换不同线程时,需要保存当前线程的完整运行状态,并加载下一个线程的状态,这个过程本身,并不执行任何有价值的业务计算,却消耗着宝贵的中央处理器时间。当大量线程,在远少于其数量的处理器核心上,进行频繁切换时,系统,就会将越来越多的时间,浪费在这种“切换”的“行政工作”上,而非“执行”真正的“业务工作”,从而导致了“线程越多,程序越慢”的悖论。
一、美好的“初衷”:并行的“理想国”
在探讨“为何会变慢”之前,我们必须首先理解,多线程编程的“美好初衷”——我们为何要,以及在何种理想情况下,它能够,让我们的程序变得更快。
1. 利用“多核”处理器
现代的中央处理器,早已进入“多核心”时代。一个拥有8个核心的中央处理器,可以被理解为,一个拥有“八个独立大脑”的计算中心。而“线程”,则是我们应用程序,利用这些“独立大脑”的、最基本的“软件执行单元”。一个单线程的程序,无论你的中央处理器有多强大,它在同一时刻,都只能使用其中的“一个大脑”。而一个设计良好的多线程程序,则可以将一个庞大的任务,拆分为多个子任务,并交由这“八个大脑”,在同一时刻,并行地进行处理,从而,理论上,能够极大地,缩短任务的总耗时。
2. “并发”与“并行”的区分
并发:指的是,我们的程序,在结构上,被设计为,可以处理多个独立的、可交错执行的任务。
并行:指的是,我们的程序,在运行时,真真切切地,在同一物理时刻,同时地,在多个处理器核心上,执行着多个任务。
并行,是实现程序“加速”的物理基础;而并发,则是实现“并行”的软件设计模式。
3. 理想的“加速比”
在一个绝对理想化的“真空”实验中,一个可以被完美地、100%地,拆分为N个独立子任务的工作,如果运行在一个拥有N个核心的处理器上,并使用N个线程来执行,那么,其理论上的“加速比”,应该是**N倍**。然而,现实世界,远比这个“理想国”,要复杂得多。
二、致命的“开销”之一:线程上下文切换
线程,并非一种“免费”的资源。每创建一个线程,以及,每在多个线程之间,进行一次“切换”,操作系统,都需要付出一定的“管理成本”。当线程数量过多时,这个“管理成本”,就会成为拖垮程序性能的“第一座大山”。
1. 什么是上下文切换?
在一个只有4个核心的中央处理器上,如果你启动了100个线程,那么,在任何一个微秒,都只有4个线程,是真正处于“运行中”的状态。其余的96个线程,都处于“等待”或“就绪”状态。操作系统的“线程调度器”,为了实现“雨露均沾”的公平性,会以极高的频率(通常是毫秒级),在这些线程之间,进行“切换”。
这个“上下文切换”的过程,如同一次精密的“交接班”:
保存现场:调度器,决定,暂停“线程A”的执行。它必须,将线程A,在当前这一刻的、所有的“工作记忆”(包括所有中央处理器寄存器的值、程序计数器的位置、栈指针等),都完整地,保存到内存中。
加载现场:然后,调度器,决定,让“线程B”接班。它需要,从内存中,找到线程B,上一次被暂停时,所保存的那个“工作记忆”,并将其,重新加载回中央处理器的各个寄存器中。
恢复执行:最后,程序计数器,跳转到线程B被保存的位置,线程B,才得以,继续执行。
2. 为何“开销”高昂?
这个“保存-加载”的上下文切换过程,本身,是纯粹的“行政开销”。在此期间,中央处理器,没有执行任何一行,与我们业务逻辑相关的、有价值的代码。当线程的数量,远远超过了物理核心的数量时(例如,在4核的机器上,运行数百个计算密集型线程),线程调度器,就会被迫地,进行“疯狂”的、高频的上下文切换。其最终结果是,中央处理器,将大量的时间,都消耗在了“切换”这个动作本身,而非“执行”我们真正的任务,程序的总吞吐量,因此,不升反降。
三、致命的“开销”之二:同步与锁竞争
多线程,带来了“并行”的可能,但也引入了“竞态条件”的风险。为了解决这个风险,我们,必须引入“锁”等同步机制。然而,“锁”,在保障了数据“一致性”的同时,也带来了新的“性能开销”。
1. “锁”的“代价”
获取和释放一把“锁”,并非一个简单的内存读写操作。它通常,需要通过“系统调用”,陷入到“操作系统内核”,来进行一次“原子操作”。这个过程,相比于一次普通的加法或赋值,其开销,要高出数个数量级。
2. “锁竞争”的“放大效应”
当线程数量,不断增加时,多个线程,在同一时刻,试图去获取“同一把锁”的概率,就会急剧地增加。这个现象,被称为“锁竞争”。
当“锁竞争”发生时,只有一个线程,能够“幸运地”获取到锁,并继续执行。而所有其他“失败”的线程,都将被迫地,进入“阻塞”或“自旋等待”的状态,放弃中央处理器的使用权。
这意味着,一把被激烈竞争的“锁”,会像一个“收费站”的唯一一个人工窗口一样,将原本可以“并行”的多条车道,强行地,收窄为一条“串行”的、需要排队等待的单行道。
当线程数量,增加到某个临界点之后,因为“锁竞争”而导致的“排队等待”时间,其增加的幅度,会超过,因增加线程而带来的“并行计算”收益。此时,程序的整体性能,就会开始下降。
四、理论的“天花板”:阿姆达尔定律
除了上述的“系统开销”,多线程的性能提升,还受限于一个根本的、数学上的“理论天花板”——阿姆达尔定律。
1. 并非所有代码都能“并行”
这个定律的核心洞察在于:任何一个程序,其所有的代码,都可以被划分为两个部分:一部分,是可以被完美“并行化”的;而另一部分,则是无论如何,都必须“串行”执行的。
串行部分:例如,程序的初始化、从单个文件中读取输入、以及,将所有并行计算的结果,进行最终的“汇总”等。
2. 阿姆达尔定律的“公式”与“洞察”
阿姆达尔定律,给出了一个计算“理论最大加速比”的公式。其简化后的洞察是:一个程序,其最终的加速比,将受限于其“串行”部分所占的比例。
一个具体的例子:
假设,一个程序,其总执行时间中,有90%,是可以被完美并行的,而有10%,是必须串行的。
那么,即便我们,拥有一个拥有“无穷多”个核心的、神一般的计算机,我们将N(核心数)代入公式,其最终的、理论上的“最大加速比”,也永远不可能超过10倍(即 1 / 0.1)。
这个定律,以一种无可辩驳的、数学上的优雅,告诉我们:在一个包含了任何“串行”成分的程序中,无限制地,增加线程(或处理器核心),其所能带来的性能收益,是存在一个“硬性上限”的,并且,这个收益,的增长,是“边际效用递减”的。
五、如何找到“最佳”线程数
既然“越多越好”是一个谬论,那么,在实践中,我们该如何,为一个特定的任务,找到一个“最佳”的线程数呢?
1. 区分“计算密集型”与“输入输出密集型”
这是进行决策的、最重要的“第一性原理”。
计算密集型:指的是,一个任务,其绝大部分时间,都在进行纯粹的中央处理器计算(例如,视频编解码、大规模的数学运算)。
对于这类任务,任何超过“物理核心数”的、多余的线程,都只会,带来不必要的“上下文切换”开销。
因此,其“最佳线程数”,通常,就等于“中央处理器的核心数”,或者,“核心数 + 1”(以允许某个线程,在偶尔的缺页中断等情况下,其他线程能补上)。
输入输出密集型:指的是,一个任务,其绝大部分时间,都在等待“输入输出”操作的完成(例如,等待数据库的查询返回、等待对远程应用程序接口的调用、等待对磁盘文件的读写)。
对于这类任务,我们可以,也应该,创建远超“物理核心数”的线程。
其背后的逻辑是,当线程A,因为等待网络数据,而进入“阻塞”状态时,它会主动地,让出中央处理器的使用权。此时,调度器,就可以,让线程B、C、D等,上来,使用这个“空闲”的中央处理器。
这种模式,能够将中央处理器的“计算时间”和网络的“等待时间”,进行“重叠”,从而,极大地,提升系统的总吞吐量。其最佳线程数,可以通过一个经验公式来估算,但更可靠的,是通过“性能测试”来获得。
2. 性能测试与“拐点”分析
要找到一个任务的“最佳线程数”,唯一科学、可靠的方法,就是进行“性能测试”。
做法:将你的应用程序,部署在一个与生产环境,配置相同的服务器上。然后,使用压力测试工具,分别,在1, 2, 4, 8, 16, 32, 64…等不同的线程数配置下,运行相同的任务,并精确地,测量其“总吞吐量”(例如,每秒完成的请求数)。
分析:将“线程数”作为横轴,“吞吐量”作为纵轴,绘制一条曲线。你通常会看到,在初始阶段,吞吐量,会随着线程数的增加而快速上升;然后,达到一个“峰值”;在越过这个峰值之后,吞吐量,反而会,随着线程数的继续增加,而开始“下降”。
结论:那个让吞吐量,达到“峰值”的线程数,就是你的应用程序,在该特定硬件和任务模型下的“最佳线程数”。
六、在流程与实践中“管理”并发
并发设计作为“架构”决策:一个应用的并发模型,应在架构设计阶段,就被明确地定义和文档化,并存放在知识库中,作为后续开发的基础。
代码审查中的“并发”视角:在进行代码审查时,审查者,必须,对所有涉及到“多线程”、“锁”、“共享资源”的代码,进行最高级别的、最审慎的检查。
利用现代并发模型:鼓励开发者,优先使用像“线程池”、“消息队列”、“异步函数”等更高级、更安全的并发抽象,而非直接地,去操作底层的、原始的线程。
常见问答 (FAQ)
Q1: “并发”和“并行”到底有什么区别?
A1: 并发,是关于“设计”的,指程序,被设计为,可以交错地处理多个任务。并行,是关于“执行”的,指程序,在同一时刻,真真切切地,在多个处理器核心上,同时地,执行多个任务。并行,是实现并发的一种方式,但并发,不一定,就意味着并行。
Q2: 我的电脑有8个核心,是不是开8个线程,程序就一定最快?
A2: 不一定。只有当你的任务,是“纯计算密集型”的,并且,可以被完美地、无锁地,分解为8个独立部分时,这个结论,才基本成立。对于包含了“输入输出等待”或“锁竞争”的任务,其最佳线程数,可能会大于8,也可能会小于8,唯一可靠的确定方法,是进行性能测试。
Q3: 什么是“上下文切换”?
A3: “上下文切换”,是操作系统,为了实现“多任务”,而暂停一个正在运行的线程,保存它所有的“工作记忆”(即上下文),然后,加载并恢复另一个线程的“工作记忆”的过程。这个过程,本身,是纯粹的“管理开销”。
Q4: “线程池”是什么?它如何帮助解决这个问题?
A4: “线程池”,是一种预先创建好一批“可复用”线程的技术。它通过“重用”已存在的线程,来执行新的任务,从而,避免了,因频繁地“创建”和“销毁”线程,所带来的巨大性能开销。同时,通过控制线程池的“最大线程数”,它也有效地,防止了,因无限制地创建线程,而导致的“资源耗尽”和“性能下降”的问题。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:百晓生,转转请注明出处:https://www.chuangxiangniao.com/p/638947.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫