
当我们在代码中,修改一个看似独立的“对象副本”时,之所以会意外地,同步改变了“原始对象”,其根本原因在于我们所复制的,并非对象本身,而仅仅是它的“内存地址”或“引用”。这种现象,源于编程语言对不同数据类型的底层处理机制,其核心逻辑涵盖:源于编程语言中“值类型”与“引用类型”的区分、变量存储的并非对象本身而是其“内存地址”、所谓的“副本”很可能只是地址的“浅拷贝”、多个变量最终指向了“同一个”内存中的对象实例、以及任何一方的修改都会通过这个共享的地址,反映到所有持有该地址的变量上。具体来说,当我们将一个对象变量A赋值给另一个变量B时(B = A),程序并没有在内存中,创建一个全新的、一模一样的对象。

它所做的,仅仅是复制了A变量中所存储的、那个指向原始对象的“内存地址”,并将其,存入了B变量。此时,A和B,就如同两把指向“同一间房子”的钥匙,无论你用哪一把钥匙开门,进去修改了房子的装修,另一个人,用另一把钥匙开门进来时,看到的,都将是这个已被修改过的房子。
一、问题的“幻象”:看似“两个”,实则“一个”
在编程的旅途中,尤其是对于初学者而言,这是一个极其常见,也极具迷惑性的“灵异事件”。让我们通过一段简单的JavaScript代码,来重现这个问题的“幻象”。
代码场景:JavaScript// 1. 我们先定义一个“原始”的用户对象 let originalUser = { name: "张三", details: { age: 30, city: "北京" } }; // 2. 我们创建了一个看似独立的“副本” let copiedUser = originalUser; // 3. 我们只修改“副本” copiedUser.details.age = 35; // 4. 我们来查看“原始”对象,期望它保持不变 console.log(originalUser.details.age);
预期的结果:30
实际的结果:35
我们明明只修改了copiedUser,为何连originalUser也一同被“诡异”地改变了? 这个“幻象”的背后,并没有任何超自然的力量,而是隐藏着计算机内存管理的一条最基本的、也最重要的核心原则:变量的“值”与“引用”的根本区别。
1. 一个关于“房子”与“钥匙”的说明 为了彻底地理解这个机制,我们可以使用一个简单的生活化说明:
内存中的“对象”:可以被看作是一间真实存在的“房子”。这间房子,包含了所有的家具和信息(即对象的属性)。
程序中的“变量”:则不是房子本身,而仅仅是一把能够打开这间房子的“钥匙”。钥匙上,记录着房子的“地址”。
当我们执行 let originalUser = { ... }; 时,计算机,实际上做了两件事:
在内存的某个地方(通常是“堆”内存),建造了一间包含了name和details等家具的“房子”(即对象实例)。
然后,它锻造了一把名为originalUser的“钥匙”,并将这间房子的“地址”,刻在了这把钥匙上。
而当我们,执行那句看似“复制”的 let copiedUser = originalUser; 时,计算机,并没有去另外建造一间一模一样的“新房子”。它所做的,仅仅是,去配钥匙的店里,完美地,复制了一把与originalUser一模一样的“钥匙”,并将其,命名为copiedUser。
至此,真相大白。我们手中,虽然有了两把“钥匙”(originalUser和copiedUser),但这两把钥匙,所能打开的,是同一间、唯一的“房子”。因此,无论你用哪把钥匙开门,进去把墙刷成蓝色,另一个人,用另一把钥匙进来时,看到的,必然是这面蓝色的墙。
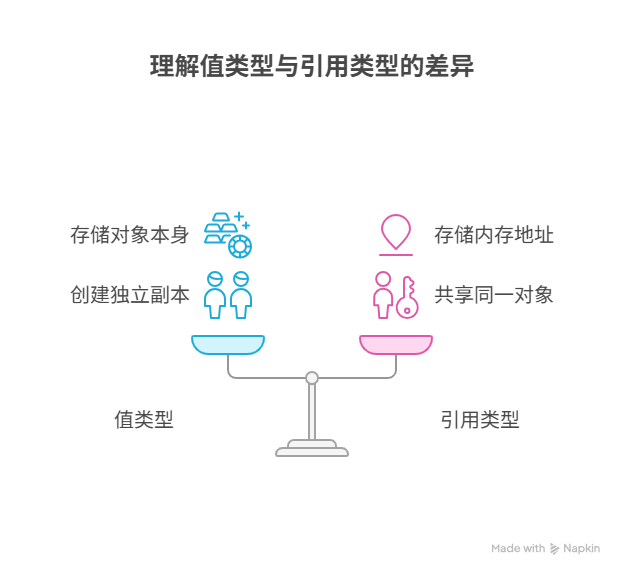
二、核心机制一:“值类型”与“引用类型”
要从更专业的角度,理解上述的“钥匙”与“房子”的区别,我们就必须引入“值类型”和“引用类型”这两个核心的计算机科学概念。
1. 值类型(原始类型)
定义:值类型的变量,其存储空间中,直接、完整地,保存着变量的“值”本身。
包含的种类:通常包括编程语言中最基础、最原始的数据类型,例如**数字(Number)、布尔值(Boolean)、字符串(String,在某些语言中表现特殊)、null、undefined**等。
复制行为:当对一个值类型的变量,进行复制时,计算机会为其,开辟一块全新的内存空间,并将原始变量的“值”,原封不动地,复制到这个新空间中。此后,两个变量,就变成了两个完全独立、互不相干的实体。JavaScriptlet a = 100; let b = a; // 计算机为b开辟了新空间,并将100这个值复制进去 b = 200; // 修改b的值 console.log(a); // 输出 100。a的值,完全不受b的影响。
2. 引用类型(复杂类型)
定义:引用类型的变量,其存储空间中,所保存的,并非是“对象”本身,而仅仅是一个指向该对象在内存中真实位置的“引用”或“指针”(即我们前面所说的“地址”或“钥匙”)。对象实体本身,则被统一地,存放在一个被称为“堆内存”的、更大的共享内存区域中。
包含的种类:通常包括所有由多个值组合而成的、更复杂的“对象”,例如**对象(Object)、数组(Array)、函数(Function)、集合(Map, Set)**等。
复制行为:当对一个引用类型的变量,进行复制时,计算机,只会复制那个“引用”(即内存地址),而不会去复制那个庞大的、位于“堆内存”中的对象实体。
三、核心机制二:“浅拷贝”与“深拷贝”
理解了“引用”的概念后,我们就进入了解决这个问题的核心环节。既然简单的=赋值,只是“复制钥匙”,那么,我们如何,才能真正地,去“克隆”一间“新房子”呢?这就引出了“拷贝”的两个不同层次:“浅拷贝”与“深拷贝”。
1. 浅拷贝:只复制“第一层”的房子
定义:浅拷贝,会创建一个新的、顶层的对象。但是,对于这个对象内部,那些属性值,本身,也是“引用类型”(例如,一个嵌套的对象或数组)的属性,它则只会,复制其“引用”,而不会,递归地,去复制那些被引用的对象。
代码示例:在JavaScript中,Object.assign({}, original) 和 {...original} 都是常见的、用于实现“浅拷贝”的方法。JavaScriptlet originalUser = { name: "张三", details: { // details属性,其值,是一个“引用类型” age: 30, } }; // 使用展开语法,进行一次“浅拷贝” let shallowCopiedUser = {...originalUser}; // 1. 修改顶层的“值类型”属性 shallowCopiedUser.name = "李四"; console.log(originalUser.name); // 输出 "张三"。顶层属性,是独立的。 // 2. 修改嵌套的“引用类型”属性 shallowCopiedUser.details.age = 35; console.log(originalUser.details.age); // 输出 35。嵌套的引用,依然是共享的!
执行过程分析:{...originalUser}这个操作,确实,在内存中,为shallowCopiedUser,创建了一个新的、顶层的“房子”。它也将name这个“值类型”的属性,复制了一份。但是,当它处理details这个属性时,它仅仅是,将originalUser.details这把“钥匙”,复制了一份,并放到了新房子里。因此,最终,shallowCopiedUser.details 和 originalUser.details,这两把位于不同“顶层房子”里的“钥匙”,打开的,依然是同一个、位于内存别处的、那个包含了age和city的“details”小房子。
2. 深拷贝:完整地、递归地,克隆“所有”的房子
定义:深拷贝,则会递归地,遍历原始对象的所有层级。每当遇到一个“引用类型”的属性时,它都会,为这个属性所引用的对象,也创建一个全新的、独立的“副本”,直至所有层级,都只剩下“值类型”为止。
如何实现:
方法一:JSON序列化/反序列化。这是最简单、最快捷的深拷贝方法。JavaScriptlet deepCopiedUser = JSON.parse(JSON.stringify(originalUser)); 原理:JSON.stringify会将一个对象,序列化为一个纯粹的“字符串”(所有引用关系,都在此过程中被“切断”)。然后,JSON.parse再将这个字符串,重新解析,构建出一个全新的、内存地址完全独立的对象。 局限性:这种方法,虽然简单,但并非万能。它无法处理一些特殊的数据类型,例如,对象中的函数、undefined、日期对象、正则表达式等,在序列化的过程中,都会被丢失或转换。
方法二:手动递归复制。自己编写一个递归函数,来遍历并复制对象的所有属性。
方法三(最佳实践):使用成熟的第三方库。在任何严肃的、生产级别的项目中,最推荐的、也最安全的做法,是使用像Lodash库中的cloneDeep方法这样,经过了充分测试的、能够处理各种复杂和边界情况的专业工具。
四、在实践中“防范”
除了在需要时,进行正确的“深拷贝”,我们还可以,在团队的“编码规范”和“协作流程”中,建立起更主动的“防范”机制。
建立“不可变性”的思维:在现代的前端(如React)和函数式编程范-式中,强烈推荐,采用“不可变性”的思维模式。即,永远不要,去“直接修改”一个已存在的对象或数组。而是应该,在每次需要变更时,都创建一个新的对象或数组,其中包含了你所需要的修改。这种做法,虽然在性能上,可能会有微小的开销,但它能够从根本上,杜绝所有因“意外的副作用”和“共享引用”所导致的、难以排查的缺陷。
明确“函数”的契约:团队的编码规范,应明确规定:一个函数,原则上,不应,修改其接收到的、作为参数的“引用类型”变量。如果一个函数,其核心职责,就是为了“修改”一个对象,那么,它的函数名,应该被清晰地,命名为mutateObject(...)之类的形式,以向调用者,明确地,警示其“副作用”。
代码审查的“火眼金睛”:在进行代码审查时,审查者,应将“检查是否存在对‘共享引用’的不安全修改”,作为一个重要的检查项。
工具的支撑:在 PingCode 或 Worktile 这样的协作平台中,团队,可以将其共同制定的《关于对象引用与拷贝的最佳实践》文档,沉淀在知识库中,作为所有成员,随时可以查阅和学习的“标准操作流程”。对于一些关键的、高风险的模块,甚至可以在 PingCode 的任务描述中,明确地,添加一条“检查清单”,提醒开发者,在进行相关修改时,必须对“深浅拷贝”问题,进行二次确认。
常见问答 (FAQ)
Q1: 什么是“值类型”和“引用类型”?
A1: “值类型”,是指变量,直接存储了数据“本身”(例如,数字100)。而“引用类型”,是指变量,存储的,仅仅是一个指向数据真实存放位置的“内存地址”或“引用”(例如,一个对象)。
Q2: 为什么let b = a;在a是数字时是复制值,在a是对象时却是复制引用?
A2: 这是由编程语言,对这两种数据类型的、底层的、不同的处理机制所决定的。对于小而简单的“值类型”,直接复制其值,成本很低。而对于可能很大、很复杂的“对象”,如果每次赋值,都进行一次完整的复制,其性能开销,将是无法接受的,因此,语言设计者,选择了只复制其“引用”。
Q3: “浅拷贝”在什么情况下是足够安全的?
A3: 当一个对象,其所有的属性,都是“值类型”(即,它是一个“扁平”的、不包含任何嵌套对象或数组的对象)时,使用“浅拷贝”,其效果,就等同于“深拷贝”,是完全安全的。
Q4: 为什么 JSON.parse(JSON.stringify(obj)) 这种深拷贝方法并不总是可靠?
A4: 因为JSON这种数据格式,其本身,所能表示的数据类型是有限的。它无法表示像“函数”、“undefined”、“日期对象”、“正则表达式”等JavaScript中的特殊对象类型。在stringify(序列化)的过程中,这些类型的信息,会被丢失或错误地转换。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:百晓生,转转请注明出处:https://www.chuangxiangniao.com/p/639306.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















