当程序提示“括号不匹配”而开发者却反复检查、找不到明显错误时,其根本原因,通常在于错误发生的“根本点”与编译器或解释器“报告点”之间存在着显著的“位置偏移”。计算机在解析代码时,是严格地、线性地、遵循语法规则进行“阅读”的,它缺乏人类的全局观和意图推断能力。一个在上百行代码之前遗漏的开括号或多余的闭括号,可能会让解析器在后续的阅读中,一直处于一种“语法结构不完整”的困惑状态,直到它遇到了一个无法再进行任何合理解释的终点(如文件结尾),才被迫报告错误。
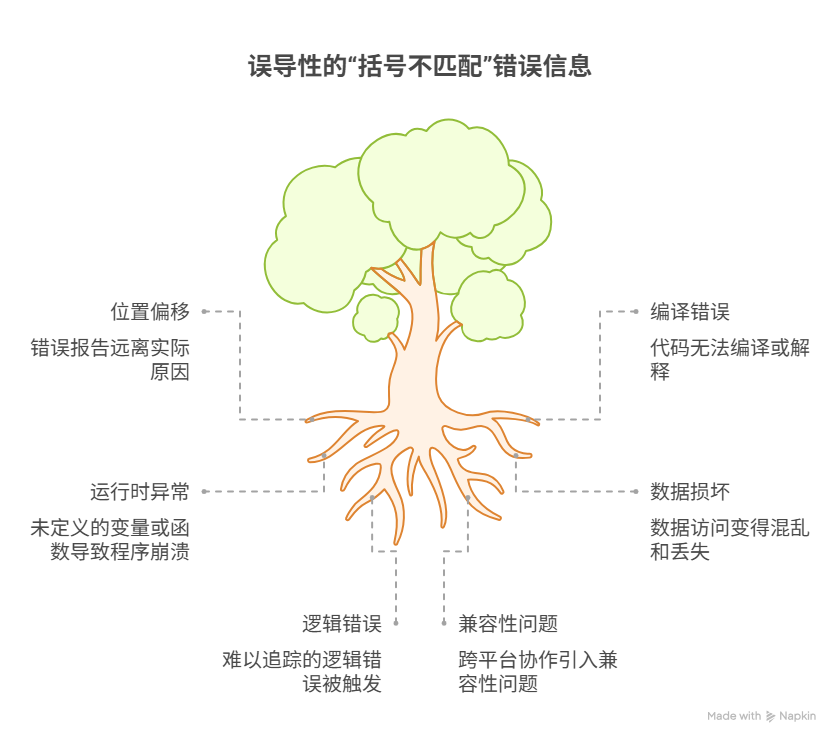
因此,我们看到的报错信息,往往只是这场“语法灾难”的“最终现场”,而非“最初的肇事点”。要解决这个问题,必须系统性地排查五大“隐形元凶”:导致编译或解释错误、引发运行时变量或函数未定义的致命异常、造成数据访问的混乱与丢失、触发难以排查的逻辑错误、以及在跨平台协作中引入潜在的兼容性灾难。
一、编译器的“第一视角”:为何报错位置会“说谎”
要理解为何“找不到”错误,我们必须首先摒弃一个错误的观念:即认为编译器或解释器,是以和我们人类同样的方式,来“看”代码的。人类在阅读代码时,会下意识地进行“模式匹配”和“整体理解”,而计算机的“语法分析器”,则像一个极其严谨、但毫无“悟性”的“语法学家”。
1. 语法分析器的工作原理
当一个语法分析器开始工作时,它会逐一地读取代码中的“词法单元”(例如,一个变量名、一个运算符、一个括号)。它内部,通常会维护一个“栈”结构。
当它遇到一个“开符号”(如 {, (, [)时,它会将其“压入”栈中。
当它遇到一个“闭符号”(如 }, ), ])时,它会检查栈顶的元素,是否是与之匹配的“开符号”。如果是,就将栈顶元素“弹出”,表示一对括号成功匹配,结构完整。
2. 错误的“发现点”对比“根本点”
“括号不匹配”的错误,正是发生在上述这个“入栈/出栈”的逻辑,出现了无法被修复的矛盾之时。
场景一:遗漏了闭括号 }。解析器,会一路顺畅地,将遇到的所有开括号,都压入栈中。直到它读取到文件的“最终结尾”,却发现,它的栈里,依然还有一个孤零零的 { 没被弹出。此时,它才意识到,整个代码的结构,是“有始无终”的。于是,它只能在文件的“最后一行”,报告一个“未预期的文件结尾,是否遗漏了‘}’?”的错误。而那个真正遗漏了括号的“根本点”,可能远在数百行之前。
场景二:多了一个闭括号 }。当解析器,遇到了一个 } 时,它试图去栈顶弹出一个 {。但如果此时,栈是“空的”(因为前面所有的{都已被成功匹配),那么,这个多出来的 } 就成了一个“无源之水”。解析器,会立即在“当前行”,就报告一个“未预期的符号‘}’”的错误。
因此,我们看到的报错行号,仅仅是解析器“再也无法忍受、最终崩溃”的那个“发现点”,而非错误的“根本点”。这正是为何,我们盯着报错的那一行,常常百思不得其解的原因。
二、常见元凶一:复杂的“嵌套”与“视觉疲劳”
这是最常见,也最符合直觉的原因。当代码的嵌套层次过深时,人脑的“堆栈”就溢出了。
深层嵌套的“代码迷宫”:在一个包含了五六层以上的 if-else、for 循环、匿名函数或闭包的复杂函数中,要用肉眼,去精确地,匹配哪一个开括号,对应着哪一个闭括号,是一项极其困难的、极易出错的“人眼扫描”任务。
长函数与“巨石”代码块:当一个独立的函数或方法,其代码行数,超过了一个屏幕的高度(例如,超过200行)时,其头尾的括号,就无法在同一个视野中出现。此时,依赖于上下滚动来寻找匹配的括号,其认知负荷会急剧增加,出错的概率也随之提升。
糟糕的代码格式化:代码的“缩进”,是括号匹配的、最重要的“视觉辅助线”。如果一个团队,没有严格地,执行统一的代码格式化标准,导致代码的缩进,时而两个空格,时而四个空格,甚至完全错乱,那么,这就相当于,人为地,擦除了所有的“辅助线”,使得代码的逻辑结构,完全无法被肉眼所识别。
【解决方案】:
重构长函数:遵循“单一职责原则”,将任何超过50-100行的“巨无霸”函数,都坚决地,重构为多个更小的、职责单一的、易于理解和测试的“微型”函数。
利用编辑器的强大辅助:
括号对着色:现代的代码编辑器,能够为不同嵌套层级的括号,自动地,渲染上不同的颜色。
括号匹配高亮:当你的光标,停留在一个括号上时,编辑器会自动地,高亮出与之匹配的另一个括号。
代码折叠:将一个完整的、已被确认无误的代码块(如一个函数体),进行“折叠”,可以极大地,减少视野中的干扰。
强制性的“自动格式化”:将“代码自动格式化”,设置为代码编辑器“保存时”的默认动作,或将其,作为代码提交前的、一个强制性的步骤。
三、常见元凶二:字符与字符串的“伪装”
有时,那个导致不匹配的“括号”,并非一个真正的、作为语法结构一部分的括号,而是一个具有“迷惑性”的“伪装者”。
注释中的“幽灵”括号:这是极其隐蔽的一类错误。
场景:开发者,为了临时调试,使用 /* ... */ 的方式,注释掉了一大段代码。但他/她可能没有注意到,在这段被注释的代码内部,本身,就包含了 /* 或 */ 这类多行注释的符号。
后果:这会导致,注释的“边界”,与开发者预期的完全不同。一个本应被注释掉的、包含着 } 的代码块,可能会因为一个意外的 */,而重新“复活”,变成了一个“多余的”闭括号。
字符串字面量中的括号:当一个字符串常量中,包含了大量的括号时(例如,一个包含了代码片段、正则表达式、或一段JSON文本的字符串),也会对开发者的“肉眼匹配”,造成极大的视觉干扰。
特殊字符与编码问题:这是一个最令人沮-丧、也最难被发现的陷阱。开发者,在中文输入法的状态下,无意中,输入了一个“全角”的括号( 或 ),而非代码语法所要求的“半角”括号 ( 或 )。这两个字符,在视觉上,极其相似,但在计算机的编码中,却是完全不同的两个“码点”。编译器,根本不认识这个“全角”的“冒牌货”。
【解决方案】:
依赖“语法高亮”:一个优秀的编辑器,其强大的“语法高亮”功能,能够用不同的颜色,来清晰地区分“代码”、“注释”和“字符串”,这是识破“伪装”的第一道防线。
审慎地注释代码块:在注释或取消注释大段代码时,要格外小心。更好的做法是,使用编辑器的、专门的“切换代码注释”的快捷键,而非手动输入 /*。
开启编辑器的“不可见字符”显示,有时可以帮助我们发现一些异常的编码问题。
四、常见元凶三:语法单元的“连锁反应”
在很多情况下,导致“括号不匹配”的罪魁祸首,并非括号本身,而是与它相邻的、某个微小的、其他的语法错误。这个“小错误”,导致了解析器,对代码结构的理解,发生了“错位”,最终,将矛盾,以“括号不匹配”的形式,嫁祸给了无辜的括号。
遗漏的“分号”:这是在JavaScript等语言中,最经典的“元凶”。如前文所述,一个遗漏的分号,可能会导致解释器,将两行独立的代码,“贪婪地”,合并为一行来解析。这个被错误合并的、语法上非法的“超级语句”,常常就会导致其后的括号,在解析时,出现“不匹配”的错误。
错误的“运算符”:例如,在JSON或对象字面量中,最后一个成员的末尾,多了一个不该存在的“逗号”;或者,一个数组的元素之间,遗漏了“逗号”。这些微小的错误,都会破坏代码的结构,并可能最终,表现为括号不匹配。
预处理指令的“陷阱”:在**C或C++**语言中,不匹配的 #if/#endif 预处理指令,可能会在“预处理”这个我们看不见的阶段,就将一大段包含了关键括号的代码,从源代码中“移除”掉,从而导致,最终进入编译器的代码,天然地,就缺少了括号。
【解决方案】: 当遇到一个难以定位的“括号不匹配”错误时,不要只盯着括号看。应将审查的范围,扩大到报错行号“上下”的五到十行代码,并重点检查,是否存在分号遗漏、逗号错误、或引号未闭合等其他更“精微”的语法问题。
五、系统性的“预防”与“定位”策略
除了上述针对性的解决方案,我们还需要一套更通用的、系统性的策略,来“预防”和“定位”这类问题。
1. 预防策略
制定并遵守统一的编码规范:一份清晰的、关于代码格式、缩进和括号使用风格的规范,是保障代码可读性、减少视觉错误的第一步。这份规范,应被文档化,并存放在像 Worktile 或 PingCode 的知识库中,作为团队的共同准则。
实施代码审查:让另一位同事,来审视你的代码,常常能发现那些因为你“思维定势”而忽略的、显而易见的错误。
单元测试:虽然单元测试,无法直接发现“编译时”的语法错误,但它能强迫你,将代码,拆分为更小的、独立的单元。在一个只有20行的小函数中,定位一个括号错误,远比在一个500行的大函数中,要容易得多。
2. 定位策略
依赖现代代码编辑器:充分利用其括号匹配高亮、代码折叠、以及强大的“静态代码分析”集成等所有功能。
“注释掉”二分法:这是一个古老但极其有效的“笨办法”。当你面对一个巨大的、有问题的代码文件时,首先,将文件的“后半部分”,全部注释掉。此时,再编译或运行,错误是否消失了?
如果消失了,说明错误,就存在于你刚刚注释掉的“后半部分”。
如果依然存在,说明错误,存在于“前半部分”。 通过这种“二分查找”的方式,不断地、逐步地,缩小“嫌疑区域”的范围,最终,你必然能将那个隐藏的错误,定位在一个极小的代码块之内。
利用版本控制工具:这是最强大的、也最高效的定位策略。如果你的代码库,在昨天还是好的,只是在今天,你提交了一些新的改动之后,才开始报错,那么,问题,几乎100%,就出在你今天的改动之中。立即使用版本控制工具(如Git)的“差异对比”功能(git diff),来清晰地,查看你今天,到底修改了哪些代码。在 PingCode 这样的研发管理工具中,其代码仓库管理模块,能够清晰地,将每一次的“代码提交”,都与具体的“需求”或“任务”相关联,这使得我们定位问题的范围,可以被进一步地,缩小到“与某个特定任务相关的几次代码提交”之上。
常见问答 (FAQ)
Q1: 为什么我的代码编辑器没有帮我标出这个错误?
A1: 有几种可能:一,编辑器的静态代码分析功能不够强大,或相关规则没有被开启;二,错误,并非一个简单的、单行的语法错误,而是一个由多行代码之间的、复杂的交互关系所导致的、更深层次的结构性问题,超出了编辑器实时分析的能力范围。
Q2: “括号不匹配”的错误,只会发生在编译的时候吗?
A2: 不一定。在Java或C++这类编译型语言中,它几乎总是,发生在“编译时”。但在JavaScript这类解释型语言中,一个由括号不匹配所引发的语法错误,可能会在“运行时”,当解释器,实际执行到那段有问题的代码时,才以“异常”的形式爆发出来。
Q3: 除了圆括号()和花括号{},还有哪些符号也容易出现不匹配问题?
A3: 方括号[](用于数组)、单引号''和双引号""(用于字符串)、以及在一些语言中,用于泛型或模板的尖括号,都是常见的、需要被成对匹配的符号,也都是“不匹配”错误的常见来源。
Q4: 作为一个初学者,如何快速提升找到这类错误的能力?
A4: 第一,养成极致的、代码格式化的“洁癖”。确保你的代码,永远保持着完美的缩进,这是最重要的视觉辅助。第二,刻意练习“小步提交”。每完成一个微小的、独立的功能,就进行一次代码的编译或运行,并提交一次版本控制。这样,一旦出现问题,其“嫌疑范围”,就会被天然地,限定在你最近的、那几分钟的修改之内。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:百晓生,转转请注明出处:https://www.chuangxiangniao.com/p/639622.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫