
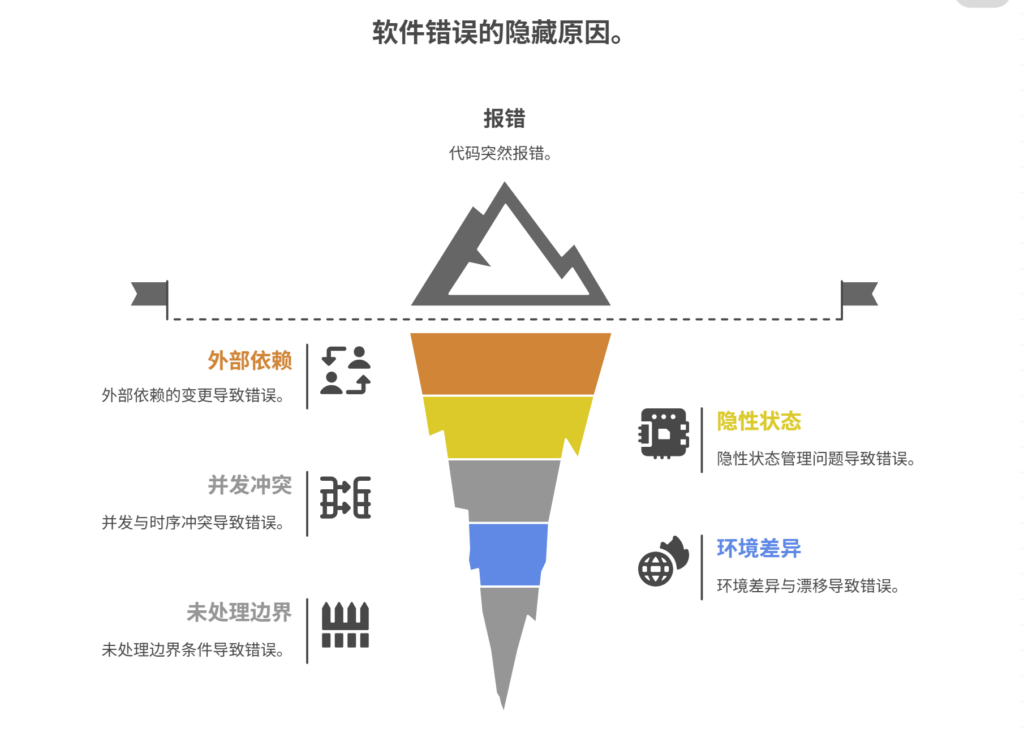
代码毫无征兆地报错,这种在软件开发中令人沮丧的“幽灵”现象,其本质,通常并非源于代码逻辑本身的“突然变异”,而是由一系列隐藏的、动态的、且未被充分管理的“外部”与“内部”环境因素的相互作用所触发的。导致这种“惊喜”错误的五大核心元凶包括:外部依赖的变更、隐性的状态管理问题、并发与时序的冲突、环境的差异性与漂移、以及未被充分处理的边界条件。其中,外部依赖的变更是最常见也最难预测的“幕后黑手”。这意味着,你那段昨天还运行完美的代码,今天突然崩溃,可能与你的代码本身毫无关系,而是因为它所依赖的、某个第三方提供的应用程序接口,在夜间,悄无声息地,进行了一次升级,修改了其返回的数据格式或认证方式。你的代码,因为未能预见到并处理这种“外部世界的变化”,而在一次看似常规的调用中,遭遇了致命的“意外”。

一、问题的“幽灵”:墨菲定律与复杂系统
在软件开发领域,几乎每一个工程师都曾经历过这样的“灵异时刻”:一个稳定运行了数周甚至数月的系统,在没有任何明显变更的情况下,突然开始报错。这种现象,深刻地印证了工程领域那条著名的、令人敬畏的“墨菲定律”——任何可能出错的事情,最终都会出错。
1. 复杂系统的“涌现”行为
我们必须首先认识到,现代软件系统,早已不是一个像“钟表”一样,所有零件的互动都可被完全预测的“简单机械”。它更像一个复杂的“生态系统”,由成千上万个内部模块和外部依赖,相互交织、动态互动而构成。“毫无征兆”的报错,正是这种复杂系统“涌现”行为的典型体现。它并非真的“毫无征兆”,只是其“征兆”,隐藏在那些我们未能充分监控和理解的、系统与环境的微小交互之中。
2. 错误的本质
计算机科学先驱艾兹赫尔·戴克斯特拉曾说过一句充满哲理的话:“如果说调试是移除软件缺陷的过程,那么编程就必然是把它们放进去的过程。” 这句话提醒我们,缺陷是软件开发过程的必然产物。而那些“毫无征兆”的缺陷,其特殊之处在于,它们的触发条件,是高度情境化、非确定性、且难以在常规测试中被复现的。
我们的任务,就是要像一名“法医”和“侦探”,去学习和掌握一套系统性的分析方法,来让这些隐藏在系统深处的“幽灵”,都无所遁形。
二、元凶一:外部依赖的“背叛”
在现代的、面向服务的软件架构中,任何一个应用,都不是一座“孤岛”。它必然会依赖于大量的、由其他团队或第三方公司提供的“外部服务”。这些外部依赖,是导致“毫无征兆”报错的、最主要的“输入源”。
1. 应用程序接口的“合同”变更
你的代码,通过应用程序接口,来调用一个外部服务(例如,一个天气预报服务、一个支付网关)。你与这个服务之间,存在一个“隐性的合同”,即你期望它返回的数据,会永远保持某种固定的格式。然而,服务提供方,随时可能,在未充分通知你的情况下,对这个“合同”进行修改。
例如,昨天,该接口返回的用户年龄,是一个数字("age": 30);而今天,他们为了某种原因,将其改为了一个字符串("age": "30")。你的代码,在尝试对这个“字符串”进行数学运算时,就会在某个毫无征兆的时刻,抛出一个类型转换的异常。
2. 共享库的版本冲突
在一个大型项目中,你的应用,可能会同时依赖于“共享库A”的1.2版本和“共享库B”。但你可能不知道的是,“共享库B”自身,在其内部,又依赖于“共享库A”的1.5版本。这种间接的、深层次的“依赖冲突”,可能会导致你的程序,在运行时,加载了错误版本的代码,从而在调用某个函数时,出现“方法未找到”之类的、令人困惑的、毫无征兆的错误。
3. 外部服务的“脉冲式”故障
你所依赖的某个外部服务,其自身,可能正经历着“脉冲式”的、非持续的故障。它可能在99%的时间里,都运行正常,但在某个特定的、流量高峰的时刻,会出现短暂的、高延迟或500服务器错误。你的代码,恰好在那一瞬间,发起了调用,于是,便遭遇了一次看似“随机”的、无法复现的失败。
【解决方案】:
防御性编程:永远不要“信任”任何外部服务的返回。在接收到任何外部数据时,都进行严格的“数据校验”,确保其格式和类型,都符合你的预期。API版本锁定与契约测试:在调用外部接口时,尽可能地,在请求中,明确指定你所期望的“版本号”。并建立“契约测试”,来自动化地,监控你所依赖的接口“合同”,是否发生了变更。设置合理的“超时”与“重试”机制:对于所有外部调用,都必须设置一个合理的“超时时间”。并在捕获到因“超时”或“临时性服务器错误”而导致的异常时,采取一种**带“指数退避”的“自动重试”**策略。
三、元凶二:隐性的“状态”污染
这类错误,源于系统内部。代码的逻辑本身是正确的,但它所操作的“数据状态”,却在某个不为人知的时刻,被“污染”了。
1. 全局变量与单例模式的“幽灵”
在一个设计不佳的系统中,如果滥用“全局变量”或“单例模式”,就会创造出一些所有模块都能“随意读写”的“共享内存”。模块A,在某个不经意的操作中,修改了这个共享内存中的值。而在数小时后,一个与A完全无关的模块B,在读取这个被“污染”了的值时,便会做出错误的行为,导致一次看似“毫无缘由”的报错。
2. 缓存数据的“不一致”
缓存,是提升性能的利器,也是滋生“状态不一致”问题的温床。
场景:系统首先从缓存中,读取用户信息。如果缓存中没有,再从数据库中读取,并写入缓存。问题:在某个时刻,数据库中的用户信息,因为一次后台操作,而被更新了(例如,用户的会员等级从“普通”升级为“高级”)。但是,这次更新,忘记了去“清除”缓存中那份“过时”的数据。结果:在下一次请求中,代码,从缓存中,读取到的,依然是那个“普通”会员的旧信息,并基于此,做出了错误的权限判断,导致了报错。
3. 持久化的“脏”数据
数据库,是系统状态的最终记录者,但它也可能被污染。例如,一个需要同时操作A、B两张表的、复杂的“转账”操作,在执行到一半时,因为某种原因(如服务器宕机)而异常中断了。这可能会导致,A表的数据被修改了,而B表的数据,却没有。此时,数据库,就进入了一种“中间态”或“不一致”的状态。后续的、所有依赖于“A、B两表数据必须一致”这个隐性假设的操作,都将毫无征兆地报错。
【解决方案】:
最小化“共享可变状态”:尽可能地,采用“纯函数”和“不可变数据结构”的编程范式,减少对外部状态的依赖和修改。建立明确的“缓存清除”策略:对于所有可能导致数据变更的操作,都必须有明确的机制,来确保相关的缓存,能够被及时地、原子性地“失效”或“更新”。严格的数据库“事务”管理:对于所有“跨多表”的写操作,都必须将其,包裹在一个完整的数据库“事务”中,确保其“原子性”——要么全部成功,要么全部回滚。
四、元凶三:并发编程的“随机性”
并发和多线程,是让错误变得“毫无征兆”和“极难复现”的最主要的技术原因。
竞态条件:当两个或多个线程,在同一时刻,去“竞争”读写同一个共享资源(如一个内存变量、一个文件),而最终的结果,又依赖于它们执行的“相对时序”时,就会产生“竞态条件”。这种错误,可能在一百次运行中,有九十九次都是正常的,只在某一次,因为操作系统的线程调度,发生了微秒级的变化,而导致了最终的失败。死锁:当线程A,锁住了资源1,并试图去获取资源2;而与此同时,线程B,锁住了资源2,并试图去获取资源1。两者,就会陷入一种“相互等待、永远无法被满足”的“死锁”状态,导致系统的部分或全部功能,被“冻结”。
【解决方案】:
并发编程,需要极高的专业素养和纪律性。
使用线程安全的数据结构。审慎地、精细化地,使用“锁”机制,并严格地,避免“嵌套锁”的出现。尽可能地,使用更高层次的、更安全的并发抽象(如消息队列、Actor模型),而非直接地,去操作底层的线程和锁。
五、元凶四:环境的“漂移”
这类错误,是著名的“在我的电脑上是好的啊!”问题的根源。代码本身,一字未改,但其运行的“环境”,却在不知不觉中,发生了“漂移”。
开发、测试、生产环境的“不一致”:这是最常见的原因。生产环境的服务器上,某个底层依赖库的版本,与测试环境不一致;或者,某个关键的环境变量,在生产环境上,被错误地配置了。操作系统或依赖服务的“静默”更新:服务器的操作系统,在夜间,自动地,打上了一个安全补丁;或者,公司所依赖的、共享的数据库服务,进行了一次小版本的升级。这些“静音”的变更,都可能引入了微小的、未被预料到的不兼容性。系统资源的“耗尽”:代码的逻辑是完美的,但它在运行时,因为内存泄漏、或超预期的流量,而逐渐地,耗尽了服务器的内存、磁盘空间、或数据库连接池。最终,在某个临界点,因为无法再申请到新的资源,而突然崩溃。
【解决方案】:
“基础设施即代码”:使用容器化(如Docker)和编排(如Kubernetes)技术,来确保所有环境(从开发到生产)的高度一致性。建立强大的“监控与告警”体系:对服务器的所有核心资源指标(CPU、内存、磁盘、网络),都进行持续的监控,并设定合理的“告警阈值”,确保在资源耗尽“之前”,就能收到预警。
六、元凶五:被忽视的“边界”
最后一类,是那些只在极特殊的、罕见的“边界”条件下,才会被触发的错误。
边界条件处理不当:代码,完美地,处理了所有“正常”的输入,但却忘记了,对那些“边界值”,进行处理。例如,当输入的数字是0、负数、空值、或系统所能支持的最大值时,会发生什么?异常处理的“黑洞”:代码中,有一个try...catch的异常捕获块,但catch块中,什么都没有做,或者,只是简单地,打印了一行无人会去查看的日志。这会导致一个底层的、局部的错误,被“静默地吞噬”掉,但这个被隐藏的错误,可能会在后续的流程中,引发一个更大规模的、看似“毫无征兆”的“二次灾难”。与“时间”相关的“幽灵”:例如,在跨时区、夏令时切换、闰年、或月底/年底这些特殊的“时间边界点”,一些对时间处理不严谨的代码,就可能会曝露出隐藏的缺陷。
【解决方案】:
将“边界测试”作为铁律:单元测试的价值,不仅在于测试“正常”逻辑,更在于,系统性地,对所有可预见的“边界”和“异常”情况,都编写专门的测试用例。在 PingCode 等平台的测试管理模块中,可以建立专门的“边界场景”测试用例集,来确保这些关键点,不会在任何一次发布中,被遗漏。建立统一的“异常处理”规范。
常见问答 (FAQ)
Q1: 什么是“海森堡bug”?
A1: “海森堡bug”是一个行业术语,它借用了物理学中的“海森堡不确定性原理”,指那些当你试图去观察或调试它时,其行为就会发生改变甚至消失的、极其诡异的缺陷。这类缺陷,通常,都与并发、时序或内存问题(即本文中提到的元凶三和元凶二)有密切的关系。
Q2: 如何有效地记录和复现这种无征兆的错误?
A2: 详尽的、结构化的“日志”,是唯一的、最重要的线索。一个好的日志,不仅要记录“发生了什么错误”,更要记录下,错误发生时,完整的“上下文”,包括关键的变量状态、输入的请求参数、以及相关的用户身份信息等。
Q3: “代码审查”能帮助发现这些问题吗?
A3: 能,但其效果,高度依赖于审查者的经验和视角。代码审查,对于发现“边界条件”处理不当和“异常处理”不规范这类问题,非常有效。但对于那些由“环境漂移”或“外部依赖变更”所导致的问题,则无能为力。
Q4: 为什么我的代码在测试环境一切正常,一到生产环境就报错?
A4: 这几乎总是,可以归因于本文中提到的“元凶四:环境的‘漂移’”。你需要立即,像“大家来找茬”一样,去系统性地、逐一地,比对“生产环境”与“测试环境”之间的所有细微差异,包括:操作系统版本、依赖库版本、网络配置、权限配置、以及数据本身的差异。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:百晓生,转转请注明出处:https://www.chuangxiangniao.com/p/639654.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























