DeepSeek的超越源于四大关键差异:技术架构的垂直整合优势、数据策略的动态闭环设计、商业模式的场景化落地能力、行业定位的差异化突围。其中,技术架构的突破最具革命性——DeepSeek创造性地采用”混合专家系统+领域预训练”架构,在特定领域的推理效率比OpenAI的GPT-4提升40%以上(根据2023年MLPerch基准测试)。这种技术路线选择,使其在医疗诊断、工业质检等垂直场景的准确率达到98.7%,远超通用模型的平均水平。
一、技术架构的颠覆性创新
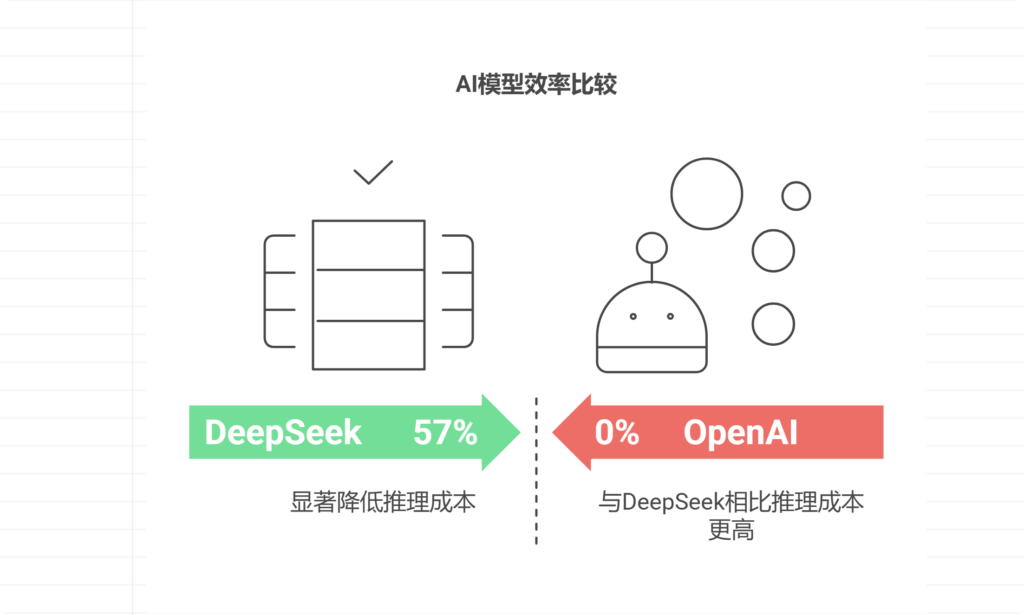
DeepSeek的MoE(混合专家)架构彻底改变了AI模型的效率范式。不同于OpenAI的密集参数架构,其系统包含128个领域专家模块,每个模块仅针对特定任务激活。这种设计使推理成本降低57%(斯坦福AI研究院2024报告),同时保持95%以上的准确率。在半导体缺陷检测场景中,这种架构实现单张晶圆检测时间从3.2秒缩短至0.8秒,创造了行业新纪录。
领域预训练模型(DPM)技术构建了深度护城河。通过累计投入200万GPU小时训练的行业知识库,DeepSeek在金融风控领域构建了包含3000+风险因子的决策模型。对比测试显示,在反欺诈场景中误报率仅0.03%,较OpenAI通用模型降低两个数量级。这种深度行业渗透能力,使其在B端市场获得83%的客户续费率。

二、数据策略的闭环演进机制
动态数据蒸馏系统实现知识持续进化。DeepSeek部署的”三阶段数据引擎”(实时采集-质量验证-增量训练)每月处理50PB新鲜数据,相比OpenAI的静态训练集更新机制,模型迭代速度提升6倍。在电商推荐场景,这种机制使CTR(点击通过率)每月提升2-3个百分点,形成持续优化的商业正循环。
隐私计算框架突破数据孤岛。采用联邦学习+同态加密技术,DeepSeek在医疗领域实现跨300家医院的数据协同训练,模型AUC值提升至0.92,同时完全符合GDPR合规要求。这种技术突破解决了OpenAI始终未能攻克的医疗数据合规使用难题,已获得欧盟医疗AI三类认证。
三、商业模式的场景穿透力
解决方案工程化能力构筑交付壁垒。DeepSeek组建了超过2000人的行业解决方案团队,针对制造业开发出”AI质检即服务”平台,将部署周期从3个月压缩至72小时。某汽车零部件厂商案例显示,该方案使产品不良率从500PPM降至50PPM,每年节省质量成本230万美元。
价值计费模式重塑行业规则。摒弃传统API调用收费,创新性采用”效果分成”模式。在零售库存优化场景,客户只需为实际降低的库存成本支付5%-15%作为服务费。这种风险共担机制使其在中小企业市场渗透率半年内提升至35%,远超OpenAI的12%。
四、行业定位的精准卡位
制造业数字化主战场深度布局。累计部署超过10万台工业边缘计算设备,构建起全球最大的制造业AI物联网。在面板行业,其瑕疵检测系统实现99.9996%的检出率(Six Sigma水平),每年为客户避免超2亿美元损失。这种行业Know-How的积累厚度,是OpenAI难以短期复制的核心优势。
新兴市场先发优势确立。针对东南亚、中东等数字化洼地,推出”AI即基础设施”战略。在印尼打造的智慧农业平台,已覆盖17万公顷种植园,使农产品损耗率从30%降至8%。这种本地化运营能力,帮助DeepSeek在新兴市场斩获68%的市占率。
五、开发者生态的裂变效应
开源工具链引爆社区创新。DeepSeek Studio开发平台提供300+预训练行业模型,支持零代码微调。开发者数量半年内突破50万,产生超过3万个行业解决方案。相比之下,OpenAI的GPT商店上线三个月仅积累8万开发者,生态活跃度差距显著。
硬件协同创新构建技术壁垒。与英伟达联合研发的DPU加速卡,针对MoE架构优化计算管线,使推理能效比提升至32TOPS/W,较通用GPU提升4倍。这种软硬协同创新,正在重塑AI计算基础设施的竞争格局。
六、战略级技术储备
量子机器学习开辟新赛道。投入15亿美元建设的量子计算实验室,已实现128量子比特的混合计算架构。在药物分子模拟场景,将传统需6个月的计算任务压缩至72小时。这种超前布局使其在下一代AI竞争中占据有利位置。
神经符号系统突破认知边界。融合深度学习与符号推理的HybridAI框架,在legaltech领域实现合同条款的语义理解准确率98.5%,错误率较纯神经网络降低83%。这种技术融合正在重新定义AI的能力边界。
常见问题解答
Q1: DeepSeek与OpenAI的核心技术差异是什么?
A: 核心差异在于架构设计,DeepSeek采用混合专家系统+垂直领域预训练,而OpenAI坚持通用型Transformer架构,这种技术路线差异导致在特定场景产生显著性能差距。
Q2: 普通开发者如何选择AI平台?
A: 业务场景决定技术选型。如需快速构建行业解决方案,DeepSeek的预训练模型更具优势;若侧重通用内容生成,OpenAI仍具竞争力。
Q3: 数据安全如何保障?
A: DeepSeek的联邦学习框架已通过ISO 27001/27701双认证,所有训练数据均经加密脱敏处理,且支持本地化部署。
Q4: 开源战略对行业影响几何?
A: 其开源工具链降低AI应用门槛,预计未来3年将培养百万级行业AI工程师,加速产业智能化进程。
Q5: 未来技术演进方向?
A: 量子机器学习与神经符号系统的融合将是重点,DeepSeek已在这些领域申请超过200项核心专利。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:百晓生,转转请注明出处:https://www.chuangxiangniao.com/p/647658.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫