
本文介绍知识蒸馏技术及基于PaddleNLP加载CPM-Distill模型实现文本生成。知识蒸馏是模型压缩方法,以“教师-学生网络”思想,让简单模型拟合复杂模型输出,效果优于从头训练。CPM-Distill由GPT-2 Large蒸馏得到,文中还给出安装依赖、加载模型、解码方法及文本生成示例。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
近些年来,随着 Bert 这样的大规模预训练模型的问世,NLP 领域的模型也逐渐变得越来越大了受限于算力水平,如此大规模的模型要应用在实际的部署场景都是不太实际的因此需要通过一些方式对大规模的模型进行压缩,使其能够在部署场景下达到一个相对可用的速度常见的模型压缩方法有:剪枝、量化、知识蒸馏等最近 CPM(Chinese Pre-Trained Models)项目又开源了一个使用知识蒸馏得到的小型文本生成模型 CPM-Distill本次项目就简单介绍一下知识蒸馏技术并且通过 PaddleNLP 套件加载 CPM-Distill 模型实现文本生成
相关项目
Paddle2.0:构建一个经典的文本生成模型GPT-2文本生成:使用GPT-2加载CPM-LM模型实现简单的问答机器人文本生成:让AI帮你写文章吧【AI创造营】PaddleHub 配合 PaddleNLP 实现简单的文本生成
相关资料
论文:CPM: A Large-scale Generative Chinese Pre-trained Language ModelDistilling the Knowledge in a Neural Network官方实现:TsinghuaAI/CPM-Distill
模型压缩技术

知识蒸馏(Knowledge Distillation)
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法。
由 Hinton 在 2015 年 Distilling the Knowledge in a Neural Network 的论文首次提出了知识蒸馏的并尝试在 CV 领域中使用,旨在把大模型学到的知识灌输到小模型中,以达到缩小模型的目标,示意图如下:
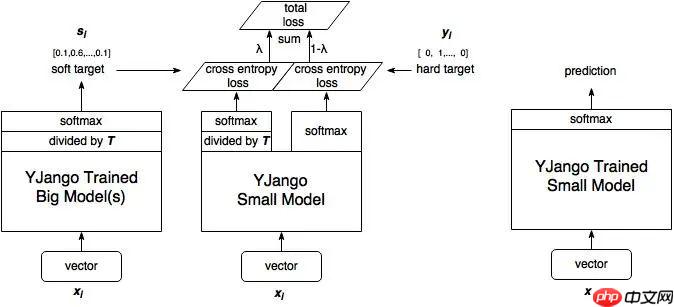
说人话就是指用一个简单模型去拟合复杂模型的输出,这个输出也叫做“软标签”,当然也可以加入真实数据作为“硬标签”一同训练。使用知识蒸馏技术相比直接从头训练的效果一般会更好一些,因为教师模型能够指导学生模型收敛到一个更佳的位置。

知识蒸馏技术除了可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近 emsemble 的结果。
蒸馏模型信息
教师模型为 GPT-2 Large,具体的模型参数如下:
teacher_model = GPTModel( vocab_size=30000, hidden_size=2560, num_hidden_layers=32, num_attention_heads=32, intermediate_size=10240, hidden_act="gelu", hidden_dropout_prob=0.1, attention_probs_dropout_prob=0.1, max_position_embeddings=1024, type_vocab_size=1, initializer_range=0.02, pad_token_id=0, topo=None)
学生模型为 GPT-2 Small,具体的模型参数如下:
teacher_model = GPTModel( vocab_size=30000, hidden_size=768, num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, hidden_act="gelu", hidden_dropout_prob=0.1, attention_probs_dropout_prob=0.1, max_position_embeddings=1024, type_vocab_size=1, initializer_range=0.02, pad_token_id=0, topo=None)
蒸馏 loss
将大模型和小模型每个位置上输出之间的 KL 散度作为蒸馏 loss,同时加上原来的 language model loss。总 loss 如下:
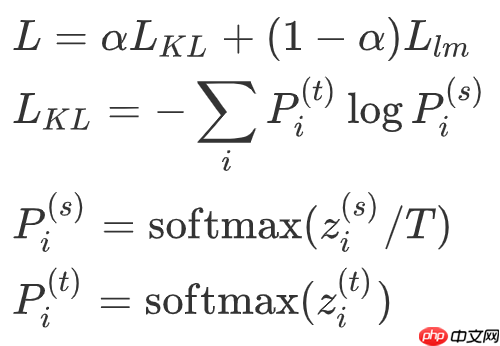
其中 LlmLlm 为 GPT-2 原始的 language modeling loss。
安装依赖
In [ ]
!pip install paddlenlp==2.0.1 sentencepiece==0.1.92
加载模型
In [1]
import paddlefrom paddlenlp.transformers import GPTModel, GPTForPretraining, GPTChineseTokenizer# tokenizer 与 CPM-LM 模型一致tokenizer = GPTChineseTokenizer.from_pretrained('gpt-cpm-large-cn')# 实例化 GPT2-small 模型gpt = GPTModel( vocab_size=30000, hidden_size=768, num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, hidden_act="gelu", hidden_dropout_prob=0.1, attention_probs_dropout_prob=0.1, max_position_embeddings=1024, type_vocab_size=1, initializer_range=0.02, pad_token_id=0, topo=None)# 加载预训练模型参数params = paddle.load('data/data92160/gpt-cpm-small-cn-distill.pdparams')# 设置参数gpt.set_dict(params)# 使用 GPTForPretraining 向模型中添加输出层model = GPTForPretraining(gpt)# 将模型设置为评估模式model.eval()
[2021-05-28 19:38:04,469] [ INFO] - Found /home/aistudio/.paddlenlp/models/gpt-cpm-large-cn/gpt-cpm-cn-sentencepiece.model
模型解码
In [40]
import paddleimport numpy as np# Greedy Searchdef greedy_search(text, max_len=32, end_word=None): # # 终止标志 if end_word is not None: stop_id = tokenizer.encode(end_word)['input_ids'] length = len(stop_id) else: stop_id = [tokenizer.eod_token_id] length = len(stop_id) # 初始预测 ids = tokenizer.encode(text)['input_ids'] input_id = paddle.to_tensor(np.array(ids).reshape(1, -1).astype('int64')) output, cached_kvs = model(input_id, use_cache=True) next_token = int(np.argmax(output[0, -1].numpy())) ids.append(next_token) # 使用缓存进行继续预测 for i in range(max_len-1): input_id = paddle.to_tensor(np.array([next_token]).reshape(1, -1).astype('int64')) output, cached_kvs = model(input_id, use_cache=True, cache=cached_kvs) next_token = int(np.argmax(output[0, -1].numpy())) ids.append(next_token) # 根据终止标志停止预测 if ids[-length:]==stop_id: if end_word is None: ids = ids[:-1] break return tokenizer.convert_ids_to_string(ids)
In [39]
import paddleimport numpy as np# top_k and top_p filteringdef top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=-float('Inf')): """ Filter a distribution of logits using top-k and/or nucleus (top-p) filtering Args: logits: logits distribution shape (vocabulary size) top_k > 0: keep only top k tokens with highest probability (top-k filtering). top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering). Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751) From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317 """ top_k = min(top_k, logits.shape[-1]) # Safety check logits_np = logits.numpy() if top_k > 0: # Remove all tokens with a probability less than the last token of the top-k indices_to_remove = logits_np < np.sort(logits_np)[-top_k] logits_np[indices_to_remove] = filter_value if top_p top_p # Shift the indices to the right to keep also the first token above the threshold sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1] sorted_indices_to_remove[..., 0] = 0 indices_to_remove = sorted_indices[sorted_indices_to_remove] logits_np[indices_to_remove] = filter_value return paddle.to_tensor(logits_np)# Nucleus Sampledef nucleus_sample(text, max_len=32, end_word=None, repitition_penalty=1.0, temperature=1.0, top_k=0, top_p=1.0): # 终止标志 if end_word is not None: stop_id = tokenizer.encode(end_word)['input_ids'] length = len(stop_id) else: stop_id = [tokenizer.eod_token_id] length = len(stop_id) # 初始预测 ids = tokenizer.encode(text)['input_ids'] input_id = paddle.to_tensor(np.array(ids).reshape(1, -1).astype('int64')) output, cached_kvs = model(input_id, use_cache=True) next_token_logits = output[0, -1, :] for id in set(ids): next_token_logits[id] /= repitition_penalty next_token_logits = next_token_logits / temperature filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p) next_token = paddle.multinomial(paddle.nn.functional.softmax(filtered_logits, axis=-1), num_samples=1).numpy() ids += [int(next_token)] # 使用缓存进行继续预测 for i in range(max_len-1): input_id = paddle.to_tensor(np.array([next_token]).reshape(1, -1).astype('int64')) output, cached_kvs = model(input_id, use_cache=True, cache=cached_kvs) next_token_logits = output[0, -1, :] for id in set(ids): next_token_logits[id] /= repitition_penalty next_token_logits = next_token_logits / temperature filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p) next_token = paddle.multinomial(paddle.nn.functional.softmax(filtered_logits, axis=-1), num_samples=1).numpy() ids += [int(next_token)] # 根据终止标志停止预测 if ids[-length:]==stop_id: if end_word is None: ids = ids[:-1] break return tokenizer.convert_ids_to_string(ids)
文本生成
In [41]
# 输入文本inputs = input('请输入文本:')print(inputs)# 使用 Nucleus Sample 进行文本生成outputs = greedy_search( inputs, # 输入文本 max_len=128, # 最大生成文本的长度 end_word=None)# 打印输出print(outputs)
请输入文本:请在此处输入你的姓名请在此处输入你的姓名,然后点击“确定”,就可以开始游戏了。游戏目标:在限定时间内,成功地把所有的牌都通通打完。
In [43]
# 输入文本inputs = input('请输入文本:')print(inputs)for x in range(5): # 使用 Nucleus Sample 进行文本生成 outputs = nucleus_sample( inputs, # 输入文本 max_len=128, # 最大生成文本的长度 end_word='。', # 终止符号 repitition_penalty=1.0, # 重复度抑制 temperature=1.0, # 温度 top_k=3000, # 取前k个最大输出再进行采样 top_p=0.9 # 抑制概率低于top_p的输出再进行采样 ) # 打印输出 print(outputs)
请输入文本:请在此处输入你的姓名请在此处输入你的姓名、学校、专业及学科,并在社交媒体上公布你的个人简介。请在此处输入你的姓名或者电话,对方会及时通知你。请在此处输入你的姓名、民族及籍贯信息,当您找到 CADULI 的联系方式后,我们会按您所选择的申请中心,以电子邮件的形式向您发送邮件。请在此处输入你的姓名和电话号码,由资深会所接待员进行介绍,因为此处有不少中国的大老板,英文能看。请在此处输入你的姓名、联系电话、银行卡号和手机号。
以上就是CPM-Distill:经过知识蒸馏的小型文本生成模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/66523.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























