ConvMixer是基于卷积层进行Mixer操作的模型,结构简单却精度不错。它与MLP Mixer类似,通过交替混合channel和token维度信息提取图像特征,但用卷积替代MLP。其用逐通道卷积提取token信息,1×1卷积提取channel信息,官方提供三个预训练模型,在ImageNet 1k验证集上表现良好,还可从头或微调训练。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
之前介绍了 MLP-Mixer,【MLP-Mixer:MLP is all you need ?】那么除了 MLP 其他的基础网络层可不可以也进行 Mixer 操作呢?结论当然也是可以的,所以这次就来介绍一个最近新鲜出炉的工作 ConvMixer。顾名思义 ConvMixer 就是使用卷积层进行 Mixer 操作来构建的一个模型结构上也非常简单,但是同样能够实现一个不错的精度表现
相关资料
论文:”Patches Are All You Need?”官方代码:tmp-iclr/convmixer
模型架构
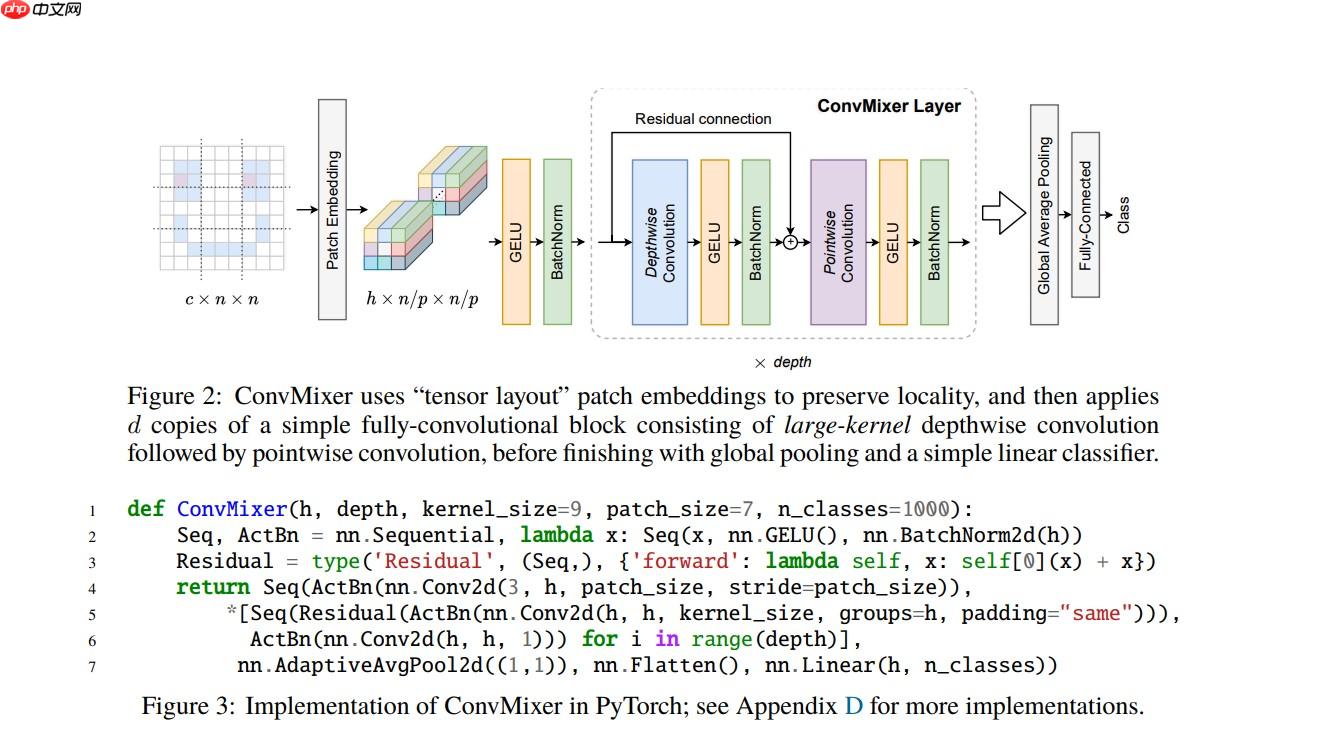
ConvMixer 与 MLP Mixer 模型一样模型的结构都十分简单
同样是通过 channel 和 token 两个维度的信息进行交替混合,实现图像特征的有效提取
只不过 ConvMixer 使用的基础网络层为卷积,而 MLP Mixer 使用的是 MLP(多层感知机)
在 ConvMixer 模型中:
使用 Depthwise Convolution(逐通道卷积) 来提取 token 间的相关信息,类似 MLP Mixer 中的 token-mixing MLP
使用 Pointwise Convolution(1×1 卷积) 来提取 channel 间的相关信息,类似 MLP Mixer 中的 channel-mixing MLP
然后将两种卷积交替执行,混合两个维度的信息
模型的大致架构如下图所示:
代码实现
模型的代码实现其实在上面的结构图中已经有出现了,不过由于过于精简可能比较不好理解下面给出官方代码中的另一种常规一些的实现方式,结构比较清晰,并且手动添加了一些注释,相对比较好理解
模型搭建
In [1]
import paddle.nn as nnclass Residual(nn.Layer): # Residual Block(残差层) # y = f(x) + x def __init__(self, fn): super().__init__() self.fn = fn def forward(self, x): return self.fn(x) + xdef ConvMixer(dim, depth, kernel_size=9, patch_size=7, act=nn.GELU, n_classes=1000): # ConvMixer Model # dim: hidden channal dim(ConvMixer 网络的隐藏层通道数) # depth: num of ConvMixer Block(网络层数也是其中 ConvMixer 层的数量) # kernel_size: kernel_size of Convolution in ConvMixer Block(ConvMixer 层中的卷积层的卷积核大小) # patch_size: patch_size in Patch Embedding (Patch Embedding 时 Patch 的大小) # act: activate function(激活函数) # n_classes: num of classes(输出的类别数量) return nn.Sequential( # Patch Embedding # Conv(kernel_size = stride = patch_size) + GELU + BN # 使用一个卷积核大小和步长都等于 Patch 大小的卷积层进行输入图像 Embedding 的操作 # 并连接一个 GELU 激活函数和 BN 批归一化层 nn.Conv2D(3, dim, kernel_size=patch_size, stride=patch_size), act(), nn.BatchNorm2D(dim), # ConvMixer Block x N(depth) # N(depth) 个 ConvMixer 层 *[nn.Sequential( # Residual Block + Depthwise Convolution + GELU + BN # 逐通道卷积提取 Token 之间的信息 # 并连接一个 GELU 激活函数和 BN 批归一化层 # 最后与原输入进行一个残差连接 Residual(nn.Sequential( nn.Conv2D(dim, dim, kernel_size, groups=dim, padding="same"), act(), nn.BatchNorm2D(dim) )), # Pointwise Convolution + GELU + BN # 1x1 卷积提取 Channel 之间的信息 # 并连接一个 GELU 激活函数和 BN 批归一化层 nn.Conv2D(dim, dim, kernel_size=1), act(), nn.BatchNorm2D(dim) ) for i in range(depth)], # Output Layers nn.AdaptiveAvgPool2D((1,1)), nn.Flatten(), nn.Linear(dim, n_classes) )
预设模型
目前官方提供了如下三个预训练模型的参数文件In [2]
import paddledef convmixer_1536_20(pretrained=False, **kwargs): model = ConvMixer(1536, 20, kernel_size=9, patch_size=7, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_1536_20_ks9_p7.pdparams') model.set_dict(params) return modeldef convmixer_1024_20(pretrained=False, **kwargs): model = ConvMixer(1024, 20, kernel_size=9, patch_size=14, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_1024_20_ks9_p14.pdparams') model.set_dict(params) return modeldef convmixer_768_32(pretrained=False, **kwargs): model = ConvMixer(768, 32, kernel_size=7, patch_size=7, act=nn.ReLU, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_768_32_ks7_p7_relu.pdparams') model.set_dict(params) return model
模型测试
In [3]
model = convmixer_768_32(pretrained=True)x = paddle.randn((1, 3, 224, 224))out = model(x)print(out.shape)model.eval()out = model(x)print(out.shape)
精度测试
标称精度
ConvMixer 与其他一些先进模型的精度对比:
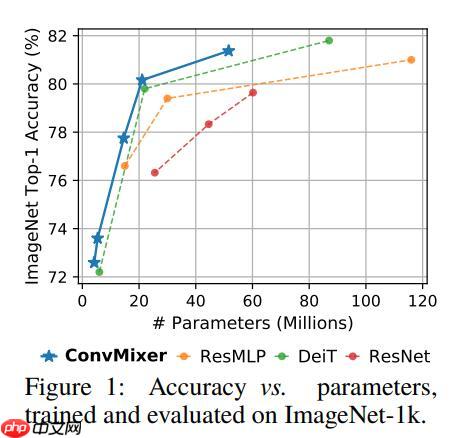
具体的精度表现如下表:
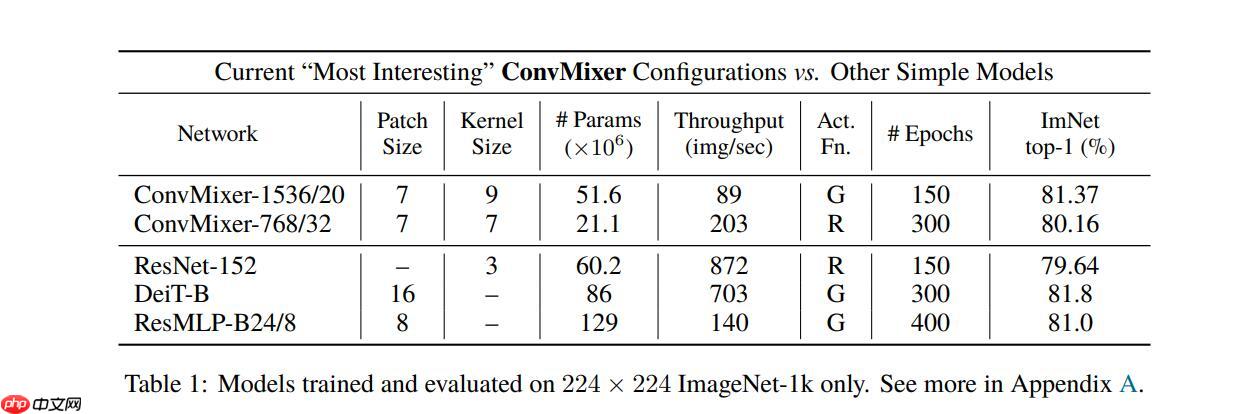
解压数据集
解压 ImageNet 1k 验证集In [8]
!mkdir data/ILSVRC2012
In [9]
!tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
精度验证
使用 ImageNet 1k 验证集对模型进行精度验证可以看到结果与官方给出的基本一致In [4]
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset): def __init__(self, root, label_list, transform, backend='pil'): self.transform = transform self.root = root self.label_list = label_list self.backend = backend self.load_datas() def load_datas(self): self.imgs = [] self.labels = [] with open(self.label_list, 'r') as f: for line in f: img, label = line[:-1].split(' ') self.imgs.append(os.path.join(self.root, img)) self.labels.append(int(label)) def __getitem__(self, idx): label = self.labels[idx] image = self.imgs[idx] if self.backend=='cv2': image = cv2.imread(image) else: image = Image.open(image).convert('RGB') image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self): return len(self.imgs)val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 配置模型model = convmixer_1536_20(pretrained=True)model = paddle.Model(model)model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=128, num_workers=0, verbose=1)print(acc)
Eval begin...step 391/391 [==============================] - acc_top1: 0.8137 - acc_top5: 0.9562 - 3s/step Eval samples: 50000{'acc_top1': 0.81366, 'acc_top5': 0.95616}
模型训练
从头训练
根据论文的模型配置训练一下 CIFAR-10 数据集的 BaseLine:
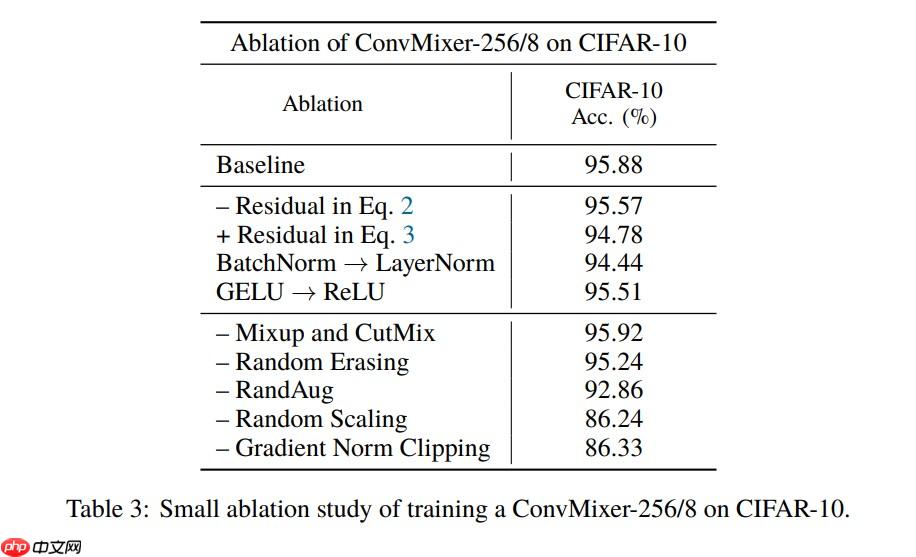
由于没有严格对齐各项训练参数,所以训练结果可能应该会有差异
In [ ]
import osimport cv2import numpy as npimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10from PIL import Imagefrom paddle.callbacks import EarlyStopping, VisualDL, ModelCheckpointtrain_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.RandomCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])model = ConvMixer(256, 8)opt = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters())model = paddle.Model(model)model.prepare(optimizer=opt, loss=nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy(topk=(1, 5)))train_dataset = Cifar10(transform=train_transforms, backend='pil', mode='train')val_dataset = Cifar10(transform=val_transforms, backend='pil', mode='test')checkpoint = ModelCheckpoint(save_dir='save')earlystopping = EarlyStopping(monitor='acc_top1', mode='max', patience=3, verbose=1, min_delta=0, baseline=None, save_best_model=True)vdl = VisualDL('log')model.fit(train_dataset, val_dataset, batch_size=32, num_workers=0, epochs=10, save_dir='save', callbacks=[checkpoint, earlystopping, vdl], verbose=1)
微调训练
基于预训练模型在 Cifar10 数据集上进行微调训练In [ ]
import osimport cv2import numpy as npimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10from PIL import Imagefrom paddle.callbacks import EarlyStopping, VisualDL, ModelCheckpointtrain_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.RandomCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])model = convmixer_768_32(n_classes=10, pretrained=True)opt = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters())model = paddle.Model(model)model.prepare(optimizer=opt, loss=nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy(topk=(1, 5)))train_dataset = Cifar10(transform=train_transforms, backend='pil', mode='train')val_dataset = Cifar10(transform=val_transforms, backend='pil', mode='test')checkpoint = ModelCheckpoint(save_dir='save')earlystopping = EarlyStopping(monitor='acc_top1', mode='max', patience=3, verbose=1, min_delta=0, baseline=None, save_best_model=True)vdl = VisualDL('log')model.fit(train_dataset, val_dataset, batch_size=32, num_workers=0, epochs=1, save_dir='save', callbacks=[checkpoint, earlystopping, vdl], verbose=1)
以上就是ConvMixer:Patches are all you need?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/67990.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫