
多进程高并发设计框架建议根据cpu核心数量来设置子进程的数量。建议将对应某一进程绑定到某一cpu上(cpu亲缘性),以充分利用多核系统的并发处理能力。多个进程在多个不同的核心上运行,实现负载均衡。职责明确,管理进程仅负责管理,工作进程负责处理业务逻辑。
示例:
multip_process.c
代码语言:C
#define _GNU_SOURCE#include #include #include #include #include// 函数指针定义,返回void,参数为voidtypedef void (spawn_proc_pt)(void *data);
// 工作进程的处理周期函数static void worker_process_cycle(void *data);
// 启动工作进程static void start_worker_processes(int n);
// 创建子进程pid_t spawn_process(spawn_proc_pt proc, void data, char name);
int main(int argc, char **argv) {// 启动4个工作进程start_worker_processes(4);// 管理子进程wait(NULL);}
// 启动子进程void start_worker_processes(int n) {int i = 0;for (i = n - 1; i >= 0; i--) {// 第一个参数为工作进程的处理周期spawn_process(worker_process_cycle, (void *)(intptr_t)i, "worker process");}}
// 创建子进程pid_t spawn_process(spawn_proc_pt proc, void data, char name) {pid_t pid;pid = fork(); // 创建子进程switch (pid) {case -1:fprintf(stderr, "fork() failed while spawning "%s"n", name);return -1;case 0:proc(data);return 0;default:break;}printf("start %s %ldn", name, (long int)pid);return pid;}
// 设置CPU亲缘关系,将进程绑定在其中的一个核上static void worker_process_init(int worker) {cpu_set_t cpu_affinity; // 多核高并发处理CPU_ZERO(&cpu_affinity);// 参数 - CPU编号 - 掩码地址CPU_SET(worker % CPU_SETSIZE, &cpu_affinity);// sched_setaffinityif (sched_setaffinity(0, sizeof(cpu_set_t), &cpu_affinity) == -1) {fprintf(stderr, "sched_setaffinity() failedn");}}
void worker_process_cycle(void *data) {int worker = (intptr_t)data;// 工作进程初始化worker_process_init(worker);// 干活for (;;) {sleep(10);printf("pid %ld ,doing ...n", (long int)getpid());}}
执行:
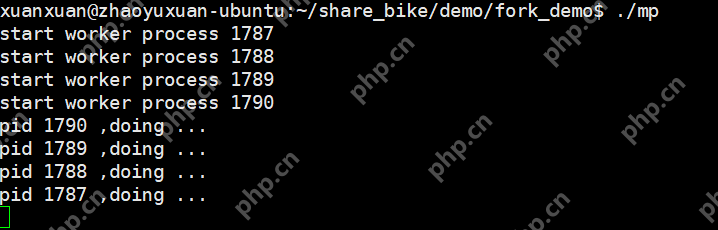
补充:
查看进程在CPU核心上的命令:
ps -eLo ruser,pid,lwp,psr,args
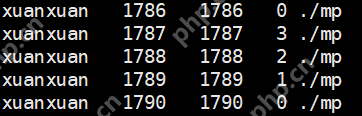
设置CPU亲缘性后,可以发现每个子进程对应一个核心。若不设置,则存在进程与核心之间的切换,进程从一个核切换到另一个核,进行拷贝与复制,从而浪费了CPU的性能,降低了执行效率。有关函数指针和typedef的结合运用,请参考相关文章。
以上就是【Linux】多进程高并发设计框架示例的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/70598.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























