
该项目基于YOLOv3实现小麦麦穗检测,使用kaggle的Global Wheat Detection数据集。先处理数据,转换真实框格式、解压、分组,切分训练和验证集,清洗微小和巨大标注边框。构建MyDataset类生成数据集,搭建以Darknet53为骨干的YOLOv3模型,设置锚框和损失函数训练,最后通过预测流程输出结果并可视化,助力小麦研究与种植管理。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于YoloV3的小麦麦穗检测
本项目是实现基于Yolov3目标检测算对来自kaggle的 Global Wheat Detection 数据集的训练和预测。yolov3本融合多种先进方法,尤其在小目标检测上效果有一定的提升,是一个速度和精度均衡的目标检测网络。

香软好吃的面包、美味小笼包、可口的饺子、以及各种特色诱人面食,你常常都会品尝到小麦加工的产品,这些作为备受欢迎的食物使小麦被广泛研究。植物科学家使用“麦穗”(含有谷物的植物顶部的尖刺)的图像检测方法,图像是全球麦田的大量准确数据,估计不同品种小麦头的密度和大小。农民在管理小麦决策时,可以使用这些数据来评估健康状况和成熟度。
然而,在室外田间图像中准确检测小麦头在视觉上可能具有挑战性。茂密的小麦植物经常重叠,风会模糊照片。两者都使得很难识别单个头部。此外,外观因成熟度、颜色、基因型和头部方向而异。最后,由于小麦在世界范围内种植,因此必须考虑不同的品种、种植密度、模式和田间条件。为小麦表型开发的模型需要在不同的生长环境之间进行泛化。目前的检测方法涉及单级和两级检测器(Yolo-V3和Faster-RCNN),但即使使用大型数据集进行训练,仍然存在对训练区域的偏差。
小麦是全球的主食,这就必须考虑到不同的生长条件。为小麦表型开发的模型需要能够在环境之间进行泛化。如果成功,研究人员可以准确地估计不同品种的小麦头的密度和大小。通过改进的检测,农民可以更好地评估他们的作物。而目标检测是先行条件。
YOLO系列算法模型设计思想
YOLO系列算法的基本流程:
样本标注。按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。建立损失函数。使用卷积神经网络模型提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数(位置回归损失,类别交叉熵损失)。
YOLO系列算法训练过程的流程图如 图1 所示:

图1:YOLO系列算法训练流程图
图1 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的132321。图1 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×3232×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
注: 没有的代码已放在work下
一、数据处理
数据集是来自kaggle的全球小麦检测数据集,真实框格式为左上点xywh,而yolov3的输入输出都为中心点xywh格式。需要转换:
bboxes[:, 0] = bboxes[:, 0] + bboxes[:, 2] / 2.0 # 将真实框位置由左上转为中心点的xywh格式bboxes[:, 1] = bboxes[:, 1] + bboxes[:, 3] / 2.0
解压数据集
In [1]
# 解压数据集!unzip -q -d data data/data198878/global-wheat-detection.zip
In [ ]
# 导入模块import numpy as npimport pandas as pdimport paddleimport osimport cv2from PIL import Image, ImageDraw, ImageEnhancefrom paddle.vision import transforms as Timport matplotlib.pyplot as pltfrom tqdm.notebook import tqdm # 进度条模块
In [5]
ROOT_PATH = 'data' def get_path(*args,fp_postfix=None): # 获取文件路径 ''' Params: fp_postfix 文件后缀 如:jpg、png、gif等 Params: *args 获取路径参数 example: f = get_path('a', 'b', 'c', 'd') print(f) # data/a/b/c/d f = get_path('a', 'b', 'c', 'd',fp_postfix='jpg') print(f) # data/a/b/c/d.jpg ''' if fp_postfix: obj_path = os.path.join(ROOT_PATH, *args) + '.' + fp_postfix return obj_path obj_path = os.path.join(ROOT_PATH, *args) return obj_path
In [6]
# 查看数据集信息img_nums = len(os.listdir(get_path('train')))print(f'train中的图片张数:{img_nums}') # 查看train中的图片张数labels = pd.read_csv(get_path('train.csv')) # 读取train.csv中的数据print("n训练集有效图片数目:{}".format(labels["image_id"].nunique()))print("训练的真实框gt_box数目:",labels.shape[0])labels.head()
train中的图片张数:3422训练集有效图片数目:3373训练的真实框gt_box数目: 147793
image_id width height bbox source0 b6ab77fd7 1024 1024 [834.0, 222.0, 56.0, 36.0] usask_11 b6ab77fd7 1024 1024 [226.0, 548.0, 130.0, 58.0] usask_12 b6ab77fd7 1024 1024 [377.0, 504.0, 74.0, 160.0] usask_13 b6ab77fd7 1024 1024 [834.0, 95.0, 109.0, 107.0] usask_14 b6ab77fd7 1024 1024 [26.0, 144.0, 124.0, 117.0] usask_1
在原始数据中,bbox的数据格式为字符串,需转换为数组。下面的代码根据image_id对边界框bbox进行分组,并将边界框作为 numpy 数组放置在每个image_id中,便于使用image_id快速检索所有边界框。
In [7]
def group_boxes(group): # 将image_id相同的图片 boundaries = group["bbox"].str.split(",", expand = True) boundaries[0] = boundaries[0].str.slice(start = 1) # 去掉bbox字符串的'[' boundaries[3] = boundaries[3].str.slice(stop = -1) # 去掉bbox字符串的']' return boundaries.values.astype(float)labels = labels.groupby("image_id").apply(group_boxes)
以下是其中一张图片的信息展示。
In [ ]
print('单张图片真实框形状:', labels["ffbf75e5b"].shape)labels["ffbf75e5b"]
从数据中提取的labels,需要将图像加载为 numpy 数组。此时,值得将数据拆分为训练和验证数据集。由于数据集很小,为了绝大多数图像作为训练数据,所以只将最后15张图像作为验证数据集。这可能不是标准验证的最佳尺寸,但考虑到可用图像的数量和任务的复杂性,采取了折衷方案。
In [9]
# 切分数据集train_image_ids = np.unique(labels.index.values)[0:3358]val_image_ids = np.unique(labels.index.values)[3358:3373]
In [10]
# 加载训图片,将尺寸1024,1024 转成 256,256,以便更快训练def load_image(image_id): img_path = get_path('train', image_id, fp_postfix='jpg') img = Image.open(img_path) img = img.resize((256, 256)) return np.asarray(img)
In [11]
# 获取图像和真实框并存储为字典def get_data(image_ids): data_pixels = {} # 图像内容 data_labels = {} # 真实框坐标 for image_id in tqdm(image_ids): data_pixels[image_id] = load_image(image_id) data_labels[image_id] = labels[image_id].copy() / 4 return data_pixels, data_labels
In [12]
# 训练集数据train_pixels, train_labels = get_data(train_image_ids)
0%| | 0/3358 [00:00<?, ?it/s]
In [13]
# 验证集数据val_pixels, val_labels = get_data(val_image_ids)
0%| | 0/15 [00:00<?, ?it/s]
可视化图像
在继续之前,先看看数据集中的一些图像和边界框。
In [14]
def draw_bboxes(image_id, bboxes, source = "train"): img_path = get_path(source, image_id, fp_postfix="jpg") image = Image.open(img_path) # 读取图片 image = image.resize((256,256)) # 调整尺寸256*256 # image = transform()(image) # 测试图像增广################# draw = ImageDraw.Draw(image) # 实例化图片 for bbox in bboxes: # 遍历bboxes draw_bbox(draw, bbox) # 画出bbox return np.asarray(image)def draw_bbox(draw, bbox): # 画方框函数 x, y, width, height = bbox draw.rectangle([x, y, x + width, y + height], width = 2, outline='red')
In [15]
def show_images(image_ids, bboxes, source = 'train'): # 多个图像多次调用此函数。 pixels = [] for image_id in image_ids: pixels.append( draw_bboxes(image_id, bboxes[image_id], source) ) num_of_images = len(image_ids) fig, axes = plt.subplots(1, num_of_images, figsize = (5 * num_of_images, 5 * num_of_images)) for i, image_pixels in enumerate(pixels): axes[i].imshow(image_pixels)
In [17]
show_images(train_image_ids[0:2], train_labels)
标注边框优化
此数据集中有少量不包含麦穗的边界框。虽然很少,但仍会影响麦穗检测,导致不准确。下面是搜索不含麦穗的微小边界框,以及标注出错的巨大边框。
In [18]
tiny_bboxes = []for i, image_id in enumerate(train_image_ids): for label in train_labels[image_id]: if (label[2] * label[3]) <= 10 and label[2] * label[3] != 0: tiny_bboxes.append((image_id, i)) print(str(len(tiny_bboxes)) + " 个微小边框")# print(tiny_bboxes)
50 个微小边框
In [19]
huge_bboxes = []for i, image_id in enumerate(train_image_ids): for label in train_labels[image_id]: if label[2] * label[3] > 8000: huge_bboxes.append((image_id, i)) print(str(len(huge_bboxes)) + " 个巨大边框")# print(huge_bboxes)
13 个巨大边框
In [ ]
# 展示部分无麦穗的边框show_images(train_image_ids[19:21], train_labels)
In [21]
# 抽取边框好的训练数据,重新生成训练集,不改变原有数据def clean_labels(train_image_ids, train_labels): good_labels = {} for i, image_id in enumerate(train_image_ids): good_labels[image_id] = [] for j, label in enumerate(train_labels[image_id]): # remove huge bbox if label[2] * label[3] > 8000 and i not in [1079, 1371, 2020]: continue # remove tiny bbox elif label[2] < 5 or label[3] < 5: continue else: good_labels[image_id].append( train_labels[image_id][j] ) return good_labelstrain_labels = clean_labels(train_image_ids, train_labels)
数据准备完整代码
In [6]
# 数据加载全整体代码# 导入模块import osimport numpy as npimport pandas as pdfrom tqdm.notebook import tqdm # 进度条模块import cv2from PIL import Image, ImageDraw, ImageEnhanceimport matplotlib.pyplot as pltimport paddlefrom paddle.vision import transforms as T# 数据集目录ROOT_PATH = 'data' # 输入图片尺寸IMG_SIZE = 416def get_path(*args,fp_postfix=None): # 获取文件路径 ''' Params: fp_postfix 文件后缀 如:jpg、png、gif等 Params: *args 获取路径参数 example: f = get_path('a', 'b', 'c', 'd') print(f) # data/a/b/c/d f = get_path('a', 'b', 'c', 'd',fp_postfix='jpg') print(f) # data/a/b/c/d.jpg ''' if fp_postfix: obj_path = os.path.join(ROOT_PATH, *args) + '.' + fp_postfix return obj_path obj_path = os.path.join(ROOT_PATH, *args) return obj_path# bbox分组,转numpydef group_boxes(group): # 将image_id相同的图片 boundaries = group["bbox"].str.split(",", expand = True) boundaries[0] = boundaries[0].str.slice(start = 1) # 去掉bbox字符串的'[' boundaries[3] = boundaries[3].str.slice(stop = -1) # 去掉bbox字符串的']' return boundaries.values.astype(float)# 加载训图片,将尺寸1024,1024 转成 IMG_SIZE*IMG_SIZE,以便更快训练def load_image(image_id): img_path = get_path('train', image_id, fp_postfix='jpg') img = Image.open(img_path) img = img.resize((IMG_SIZE, IMG_SIZE)) return np.asarray(img)# 切分数据集def train_seq_val(ration_size): train_image_ids = np.unique(labels.index.values)[0:ration_size] val_image_ids = np.unique(labels.index.values)[ration_size:3373] return train_image_ids, val_image_ids# 获取图像和真实框并存储为字典def get_data(image_ids): data_pixels = {} # 图像内容 data_labels = {} # 真实框坐标 for image_id in tqdm(image_ids): data_pixels[image_id] = load_image(image_id) data_labels[image_id] = labels[image_id].copy() / (1024 / IMG_SIZE) # 缩放标签 return data_pixels, data_labels# 抽取边框好的训练数据,重新生成训练集,不改变原有数据def clean_labels(train_image_ids, train_labels): good_labels = {} for i, image_id in enumerate(train_image_ids): good_labels[image_id] = [] for j, label in enumerate(train_labels[image_id]): # remove huge bbox if label[2] * label[3] > 8000 and i not in [1079, 1371, 2020]: continue # remove tiny bbox elif label[2] < 5 or label[3] < 5: continue else: good_labels[image_id].append( train_labels[image_id][j]) return good_labelslabels = pd.read_csv(get_path('train.csv')) # 读取train.csv中的数labels = labels.groupby("image_id").apply(group_boxes) # 格式转换,真实框分组# 切分数据集train_image_ids, val_image_ids = train_seq_val(ration_size=3358)# 训练集数据train_pixels, train_labels = get_data(train_image_ids)# 验证集数据val_pixels, val_labels = get_data(val_image_ids)# 进一步优化真实框数据train_labels = clean_labels(train_image_ids, train_labels)
0%| | 0/3358 [00:00<?, ?it/s]
0%| | 0/15 [00:00<?, ?it/s]
生成数据集
通常我会使用 Paddle data API 数据生成器来构建pipeline用于将数据传入模型中。需要为此模型完成的预处理并非微不足道,事实证明创建自定义数据生成器更容易。
定义数据集大小。随机打乱数据集顺序。获取图像并对其进行扩充,以增加数据集的多样性。这包括在图像中的麦穗变化时修改边界框。将边界框的形状调整为标签网格。
麦穗检测可以看作是一分类目标检测任务,由于原数据集没有类别标签数据,需对数据添加类别标签。
def get_bbox(self, gt_bbox): # 对于一般的检测任务来说,一张图片上往往会有多个目标物体 # 设置参数MAX_NUM = 55, 即一张图片最多取55个真实框;如果真实 # 框的数目少于55个,则将不足部分的gt_bbox的各项数值全设置为0 MAX_NUM = 55 gt_bbox2 = np.zeros((MAX_NUM, 4)) gt_class2 = np.zeros((MAX_NUM,)) # 1分类 gt_bbox = np.array(gt_bbox) for i in range(len(gt_bbox)): if i >= MAX_NUM: break gt_bbox2[i, :] = gt_bbox[i, :] gt_class2[i] = 0 # 一分类标签为0 return gt_bbox2, gt_class2
生成数据集
In [7]
class MyDataset(paddle.io.Dataset): def __init__(self, image_ids, image_pixels, img_size, labels = None, mode = None): super(MyDataset, self).__init__() self.image_ids = image_ids self.image_pixels = image_pixels self.img_size = img_size self.labels = labels self.transform = None self.mode = mode if self.mode == "train": self.transform =T.Compose([ T.BrightnessTransform(0.4), # 亮度调节 T.ContrastTransform(0.4), # 对比度调节 T.HueTransform(0.4), # 色调 # T.RandomErasing(), # 随机擦除 T.Normalize(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375],data_format='HWC'), # 标准化 T.Transpose() # 数据格式转换,Transpose默认参数(2,0,1) ]) if self.mode == "val": self.transform =T.Compose([ T.Normalize(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375],data_format='HWC'), T.Transpose() ]) def get_bbox(self, gt_bbox): # 对于一般的检测任务来说,一张图片上往往会有多个目标物体 # 设置参数MAX_NUM = 55, 即一张图片最多取55个真实框;如果真实 # 框的数目少于55个,则将不足部分的gt_bbox的各项数值全设置为0 MAX_NUM = 55 gt_bbox2 = np.zeros((MAX_NUM, 4)) gt_class2 = np.zeros((MAX_NUM,)) # 1分类 gt_bbox = np.array(gt_bbox) for i in range(len(gt_bbox)): if i >= MAX_NUM: break gt_bbox2[i, :] = gt_bbox[i, :] gt_class2[i] = 0 return gt_bbox2, gt_class2 def __getitem__(self, index): image_id = self.image_ids[index] X = self.image_pixels[image_id] w = X.shape[0] h = X.shape[1] bboxes, gt_labels = self.get_bbox(self.labels[image_id]) box_idx = np.arange(bboxes.shape[0]) # 随机打乱真实框排列顺序 np.random.shuffle(box_idx) gt_labels = gt_labels[box_idx] bboxes = bboxes[box_idx] # 真实框位置是左上点的xywh格式 bboxes[:, 0] = bboxes[:, 0] + bboxes[:, 2] / 2.0 # 将真实框位置由左上转为中心点的xywh格式 bboxes[:, 1] = bboxes[:, 1] + bboxes[:, 3] / 2.0 y = bboxes if self.transform: X = self.transform(X) return X.astype('float32'), np.array(y, dtype = 'float32') / self.img_size, np.array(gt_labels, dtype = 'int32'), np.array([h, w],dtype='int32') def __len__(self): return len(self.image_ids)
In [9]
train_dataset = MyDataset(train_image_ids, train_pixels, IMG_SIZE, train_labels, mode='train')val_dataset = MyDataset(val_image_ids, val_pixels, IMG_SIZE, val_labels, mode='val')# 查看数据集形状d = paddle.io.DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=0)print(next(d())[0].shape, next(d())[1].shape)
[4, 3, 416, 416] [4, 55, 4]
二、网络搭建
准备好数据后,我将定义和训练模型。通过连续使用多层卷积和池化等操作,能得到语义含义更加丰富的特征图。在检测问题中,也使用卷积神经网络逐层提取图像特征,通过最终的输出特征图来表征物体位置和类别等信息。
YOLOv3算法使用的骨干网络是Darknet53。Darknet53网络的具体结构如 图16 所示,在ImageNet图像分类任务上取得了很好的成绩。在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。YOLOv3模型会在骨干网络的基础上,再添加检测相关的网络模块。
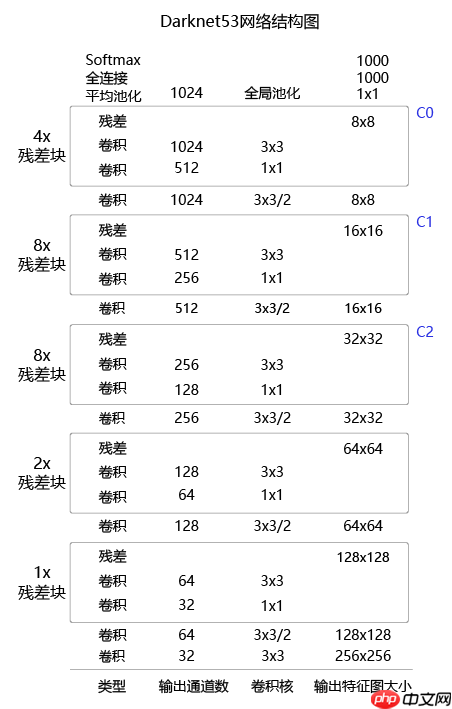 图2 DarkNet53网络结构图
图2 DarkNet53网络结构图
网络层输出C0->y1、C1->y2、C2->y3 ,由YoloDetectionBlock实现
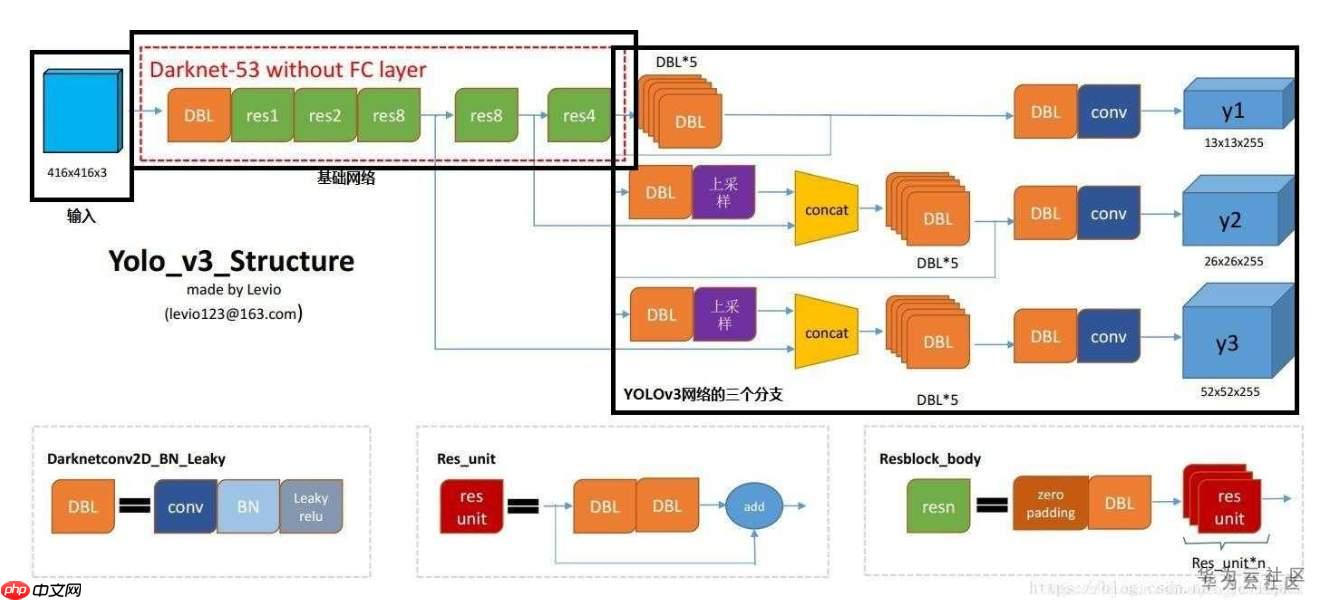 图3 YoloDetectionBlock右边的框
图3 YoloDetectionBlock右边的框
输出形状对应的信息如下图:
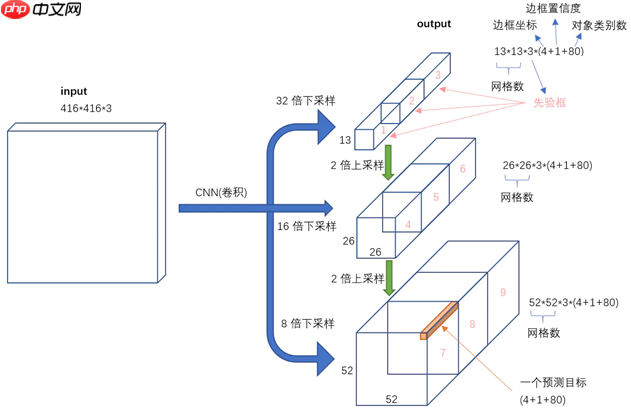 图4 输出特征形状
图4 输出特征形状
YoloV3 模型的基本组件
移至work/utils.py
Yolov3多尺度检测模型
多尺度检测可以解决目标稠密以及大小差异大的问题。
三、模型训练
anchor:由于我的训练图像尺寸为416 * 416,使用默认anchor。loss :yolo的loss比较复杂,直接使用飞桨的提供的yolo loss算子:
loss_obj = paddle.nn.fucntional.binary_cross_entropy_with_logits(pred_classification, label_classification)
训练流程: 训练过程如 图 所示,输入图片经过特征提取得到三个层级的输出特征图P0(stride=32)、P1(stride=16)和P2(stride=8),相应的分别使用不同大小的小方块区域去生成对应的锚框和预测框,并对这些锚框进行标注。
P0层级特征图,对应着使用32×32的小方块,在每个区域中心生成大小分别为 [116,90], [156,198], [373,326] 的三种锚框。
P1层级特征图,对应着使用16×16大小的小方块,在每个区域中心生成大小分别为 [30,61], [62,45], [59,119] 的三种锚框。
P2层级特征图,对应着使用8×8大小的小方块,在每个区域中心生成大小分别为 [10,13], [16,30], [33,23] 的三种锚框。
将三个层级的特征图与对应锚框之间的标签关联起来,并建立损失函数,总的损失函数等于三个层级的损失函数相加。通过极小化损失函数,可以开启端到端的训练过程。
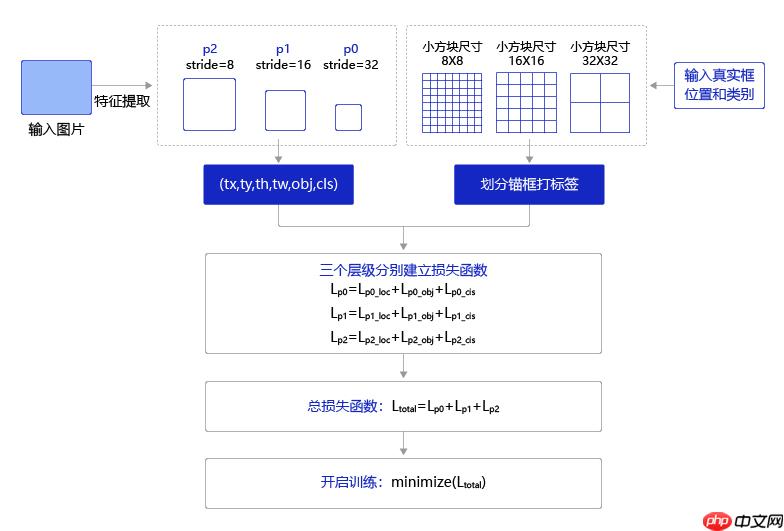 图5 训练流程图
图5 训练流程图
开启训练
In [ ]
import timeimport osimport paddlefrom work.model import YOLOv3from work.utils import new_anchorsIMG_SIZE = 416ANCHORS = new_anchors(IMG_SIZE)ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]IGNORE_THRESH = 0.7# 类别数NUM_CLASSES = 1# 训练轮数MAX_EPOCH = 10def get_lr(base_lr = 0.000125, lr_decay = 0.1): bd = [10000, 20000] lr = [base_lr, base_lr * lr_decay, base_lr * lr_decay * lr_decay] learning_rate = paddle.optimizer.lr.PiecewiseDecay(boundaries=bd, values=lr) return learning_rateif __name__ == '__main__': # 设置gpu paddle.device.set_device("gpu") # 实例化数据集 train_dataset = MyDataset(train_image_ids, train_pixels, IMG_SIZE, train_labels, mode='train') val_dataset = MyDataset(val_image_ids, val_pixels, IMG_SIZE, val_labels, mode='val') # 实例化数据生成器 train_loader = paddle.io.DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=2) val_loader = paddle.io.DataLoader(val_dataset, batch_size=15, shuffle=False, num_workers=2) # 实例化模型 model = YOLOv3(num_classes = NUM_CLASSES) # 学习率设置 learning_rate = get_lr() # 优化策略 opt = paddle.optimizer.Momentum( learning_rate=learning_rate, momentum=0.9, weight_decay=paddle.regularizer.L2Decay(0.0005), parameters=model.parameters()) #创建优化器 # opt = paddle.optimizer.Adam(learning_rate=learning_rate, weight_decay=paddle.regularizer.L2Decay(0.0005), parameters=model.parameters()) # 开启训练 for epoch in range(MAX_EPOCH): for i, data in enumerate(train_loader()): img, gt_boxes, gt_labels, img_scale = data gt_scores = np.ones(gt_labels.shape).astype('float32') gt_scores = paddle.to_tensor(gt_scores) img = paddle.to_tensor(img) gt_boxes = paddle.to_tensor(gt_boxes) gt_labels = paddle.to_tensor(gt_labels) outputs = model(img) # 前向传播,输出[P0, P1, P2] loss = model.get_loss(outputs, gt_boxes, gt_labels, gtscore=gt_scores, anchors = ANCHORS, anchor_masks = ANCHOR_MASKS, ignore_thresh=IGNORE_THRESH, use_label_smooth=False) # 计算损失函数 loss.backward() # 反向传播计算梯度 opt.step() # 更新参数 opt.clear_grad() if i % 100 == 0: timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time())) print('{}[TRAIN]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy())) # 保存参数 if (epoch % 5 == 0) or (epoch == MAX_EPOCH -1) or (epoch == 6): # 这里是为了保存第6轮 paddle.save(model.state_dict(), 'yolo_epoch{}'.format(epoch)) # 每个epoch结束之后在验证集上进行测试 model.eval() for i, data in enumerate(val_loader()): img, gt_boxes, gt_labels, img_scale = data gt_scores = np.ones(gt_labels.shape).astype('float32') gt_scores = paddle.to_tensor(gt_scores) img = paddle.to_tensor(img) gt_boxes = paddle.to_tensor(gt_boxes) gt_labels = paddle.to_tensor(gt_labels) outputs = model(img) loss = model.get_loss(outputs, gt_boxes, gt_labels, gtscore=gt_scores, anchors = ANCHORS, anchor_masks = ANCHOR_MASKS, ignore_thresh=IGNORE_THRESH, use_label_smooth=False) if i % 1 == 0: timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time())) print('{}[VALID]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy())) model.train()
四、模型预测
预测过程流程如下所示:
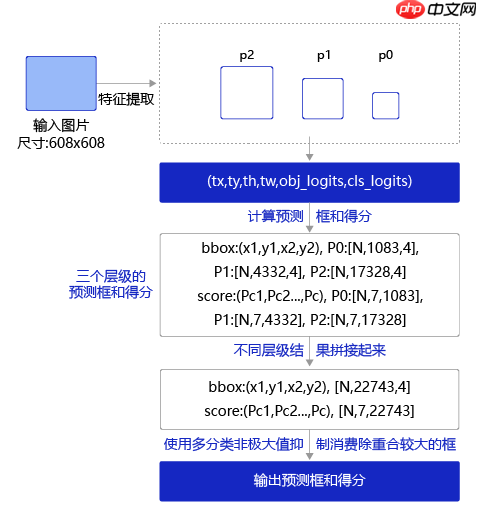
图6 预测流程图
预测过程可以分为两步:
通过网络输出计算出预测框位置和所属类别的得分。 使用非极大值抑制来消除重叠较大的预测框。 对于第1步,前面我们已经讲过如何通过网络输出值计算pred_objectness_probability, pred_boxes以及pred_classification_probability,这里推荐大家直接使用paddle.vision.ops.yolo_box,关键参数含义如下:
paddle.vision.ops.yolo_box(x, img_size, anchors, class_num, conf_thresh, downsample_ratio, clip_bbox=True, name=None, scale_x_y=1.0)
:x,网络输出特征图,例如上面提到的P0或者P1、P2。
:imgsize,输入图片尺寸。
:anchors,使用到的anchor的尺寸,如'[10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]。
:classnum,物体类别数。
:confthresh, 置信度阈值,得分低于该阈值的预测框位置数值不用计算直接设置为0.0。
:downsampleratio, 特征图的下采样比例,例如P0是32,P1是16,P2是8。
:name=None,名字,例如’yolobox’,一般无需设置,默认值为None。
返回值包括两项,boxes和scores,其中boxes是所有预测框的坐标值,scores是所有预测框的得分。
预测框得分的定义是所属类别的概率乘以其预测框是否包含目标物体的objectness概率,即
$score = P_{obj} * P_{classification}$
在上面定义的类YOLOv3下面添加函数,get_pred,通过调用paddle.vision.ops.yolo_box获得P0、P1、P2三个层级的特征图对应的预测框和得分,并将他们拼接在一块,即可得到所有的预测框及其属于各个类别的得分。
非极大值抑制NMS
移至work/utils.py
加载测试集
测试结果并保存
In [1]
from work.predict import predictdatadir = 'data/test'predict(datadir)
W0501 17:21:15.915298 7022 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2W0501 17:21:15.919631 7022 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
五、模型效果及可视化展示
上面的程序展示了如何读取测试数据集的图片,并将最终结果保存在json格式的文件中。
json文件中保存着测试结果,是包含所有图片预测结果的list,其构成如下:
[[img_name, [[label, score, x1, y1, x2, y2], ..., [label, score, x1, y1, x2, y2]]], [img_name, [[label, score, x1, y1, x2, y2], ..., [label, score, x1, y1, x2, y2]]], ... [img_name, [[label, score, x1, y1, x2, y2],..., [label, score, x1, y1, x2, y2]]]]
list中的每一个元素是一张图片的预测结果,list的总长度等于图片的数目,每张图片预测结果的格式是:
[img_name, [[label, score, x1, y1, x2, y2],..., [label, score, x1, y1, x2, y2]]]
其中第一个元素是图片名称image_name,第二个元素是包含该图片所有预测框的list, 预测框列表:
[[label, score, x1, x2, y1, y2],..., [label, score, x1, y1, x2, y2]]
预测框列表中每个元素[label, score, x1, y1, x2, y2]描述了一个预测框,label是预测框所属类别标签,score是预测框的得分;x1, y1, x2, y2对应预测框左上角坐标(x1, y1),右下角坐标(x2, y2)。每张图片可能有很多个预测框,则将其全部放在预测框列表中。
为了更直观的展示模型效果,下面的程序添加了读取单张图片,并画出其产生的预测框。
单张图片加载
定义画图函数
单样本展示
In [ ]
from work.fnc import fnfrom PIL import Image import matplotlib.pyplot as plt image_name = '2fd875eaa.jpg'plt.figure()plt.imshow(fn(image_name, 0.15, 0.15))plt.show()
Gradio webui
直观感受nms_thresh和valid_thresh变化对结果的影响。
1 双击 detection.gradio.py 文件2 点击选择图片3 滑杠调整nms_thresh和valid_thresh值4 submit等待结果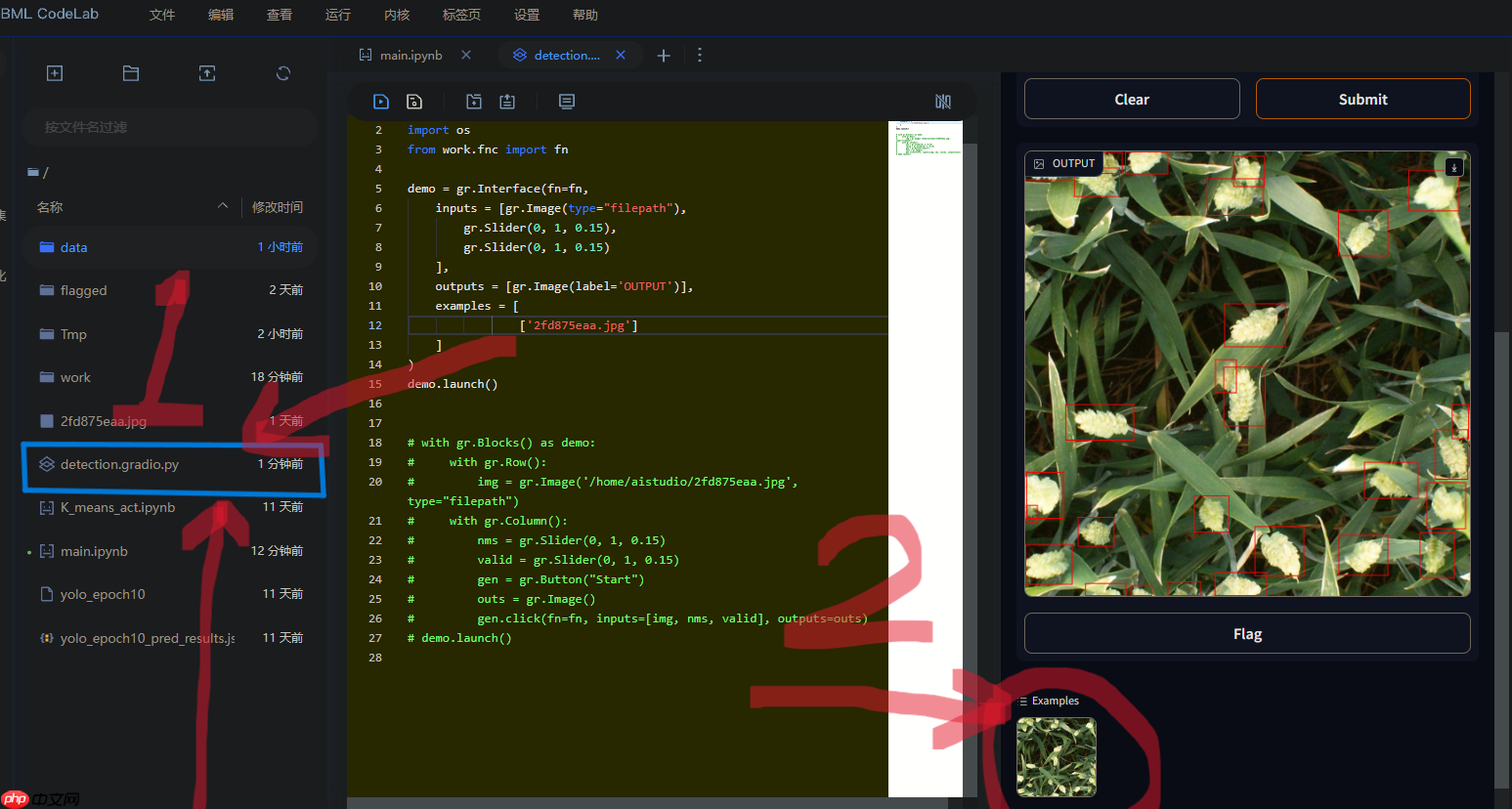
以上就是【AI达人特训营第三期】全球小麦麦穗检测的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/71739.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























