
linux探索学习:
https://blog.csdn.net/2301_80220607/category_12805278.html?spm=1001.2014.3001.5482
前言:
为什么需要进程通信?
在Linux中,每个进程都有独立的地址空间,这种隔离性保障了系统的稳定性和安全性,但也使得进程间直接访问彼此的内存成为不可能。因此,为了在不同进程之间交换数据,操作系统提供了多种IPC机制。
常见的进程通信使用场景包括:
Linux中的进程通信机制概览
Linux 提供了多种进程通信方式,适用于不同场景。以下是常见的几种机制:
通信方式
描述
优点
缺点
管道(Pipe)
单向或双向数据流,父子进程间通信
简单、效率高
只能在亲缘进程之间通信,不适合大数据量传输
FIFO(命名管道)
像管道一样,但可用于无亲缘关系的进程间通信
灵活性更高
性能较低
消息队列
基于消息的异步通信方式
可传递结构化消息
管理复杂,性能受限
共享内存
不同进程共享内存区域进行通信
高效,适合大数据量传输
同步机制复杂,需额外处理同步问题
信号量
用于进程同步和资源管理
简单、轻量级
不适合复杂的通信场景
套接字(Socket)
网络通信和本地进程通信的强大工具
强大且灵活,支持多种协议
实现较复杂,需学习成本
接下来,我们详细探讨这些通信方式,重点讲解管道和命名管道。(信号量和套接字的内容不作为重点)
1. 管道(Pipe)通信(匿名管道)
管道是Linux中最简单、最常用的进程通信方式之一。它提供了一个单向数据流,可以在父子进程之间传递数据。
原理
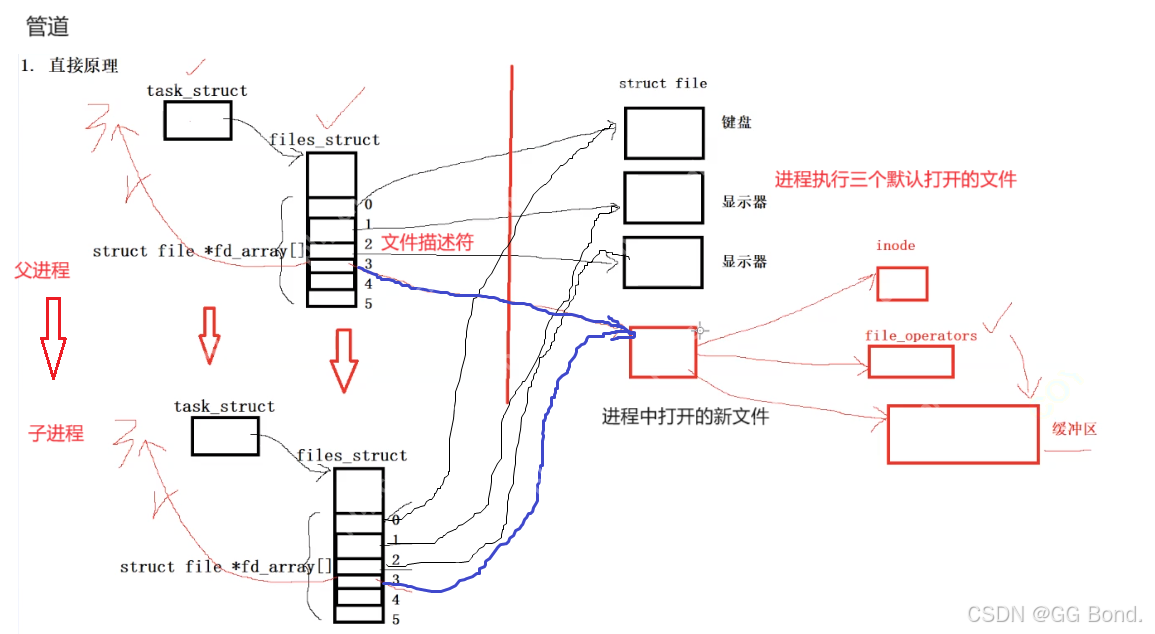
上面内容补充说明:
内存级文件:当我们进程打开一个文件并向里面写入时,是要先写入缓冲区的,然后系统再刷新进入磁盘中的,但是文件其实并不是一定要存在在磁盘中的,也可以直接存在内存中的,内存级文件与普通文件的区别就是不会刷新到显示屏中,其它基本一致子进程在创建时会对父进程进行拷贝,files struct也会拷贝,但是拷贝方式类似于指针拷贝的浅拷贝,只会拷贝结构体,并不会把父进程打开的文件拷贝一份一样的,所以子进程的文件描述符与父进程一样,与父进程用的相同的文件(比如:当我们创建一个父子进程时,在不同的窗口打开它们,让这两个进程同时向显示屏上刷新内容时,都会刷新在父进程的显示屏上)实现进程通信的前提就是让不同的进程看到同一份“资源”,所以我们就可以让父进程和子进程通过这样的内存级文件建立联系管道的本质就是内存级文件特性 单向性:标准管道是单向的,即数据只能沿一个方向流动。 亲缘关系:标准管道只能用于具有亲缘关系的进程间通信。 内核缓冲区:管道依赖于内核缓冲区,数据写入后,只有在被读取时才会释放缓冲区。 系统调用
Linux 提供以下系统调用与管道相关:
pipe(): 创建一个管道,返回两个文件描述符:fd[0](用于读)和 fd[1](用于写)。示例代码:管道的基本用法
以下代码展示了父子进程通过管道进行通信:
代码语言:javascript代码运行次数:0运行复制
#include #include #include #include int main() { int pipefd[2]; pid_t pid; char buffer[128]; // 创建管道 if (pipe(pipefd) == -1) { perror("pipe failed"); return 1; } pid = fork(); // 创建子进程 if (pid < 0) { perror("fork failed"); return 1; } else if (pid == 0) { // 子进程 close(pipefd[1]); // 关闭写端 read(pipefd[0], buffer, sizeof(buffer)); // 读取数据 printf("Child process received: %sn", buffer); close(pipefd[0]); // 关闭读端 } else { // 父进程 close(pipefd[0]); // 关闭读端 const char *msg = "Hello from parent!"; write(pipefd[1], msg, strlen(msg) + 1); // 写入数据 close(pipefd[1]); // 关闭写端 wait(NULL); // 等待子进程结束 } return 0;}预期结果代码语言:javascript代码运行次数:0运行复制
Child process received: Hello from parent!
管道的局限性 单向数据流:默认情况下,管道只支持单向通信。 仅限亲缘进程:标准管道仅适用于父子进程之间。 容量限制:管道的内核缓冲区有限,写入数据量过大会阻塞。(不同的操作系统内核下内存级文件的大小是不同的,默认规定的是4kb,但比如centos7.0下就是16kb) 双向通信
通过创建两个管道,可以实现双向通信(不常用)。例如:
代码语言:javascript代码运行次数:0运行复制
int pipe1[2], pipe2[2];pipe(pipe1);pipe(pipe2);// 使用 pipe1 进行父->子通信,使用 pipe2 进行子->父通信。2. FIFO(命名管道)
FIFO(命名管道)克服了标准管道只能在亲缘进程间通信的限制。它是文件系统中的一种特殊文件,允许无亲缘关系的进程间通信。
创建命名管道
命名管道可以使用以下方法创建:
命令行工具:使用 mkfifo 命令。
系统调用:使用 mkfifo() 函数。具体方式可以通过man手册来查看
代码语言:javascript代码运行次数:0运行复制
man mkfifo示例代码:命名管道
以下代码演示了两个独立进程通过命名管道通信:
写入进程:writer.c
代码语言:javascript代码运行次数:0运行复制
#include #include #include int main() { const char *fifo = "/tmp/my_fifo"; mkfifo(fifo, 0666); // 创建命名管道 int fd = open(fifo, O_WRONLY); // 打开管道写端 const char *msg = "Hello from writer!"; write(fd, msg, strlen(msg) + 1); // 写入数据 close(fd); // 关闭文件描述符 return 0;}读取进程:reader.c
代码语言:javascript代码运行次数:0运行复制
#include #include #include int main() { const char *fifo = "/tmp/my_fifo"; char buffer[128]; int fd = open(fifo, O_RDONLY); // 打开管道读端 read(fd, buffer, sizeof(buffer)); // 读取数据 printf("Reader process received: %sn", buffer); close(fd); // 关闭文件描述符 return 0;}运行步骤
启动 reader 进程:
代码语言:javascript代码运行次数:0运行复制
./reader启动 writer 进程:
代码语言:javascript代码运行次数:0运行复制
./writer预期结果代码语言:javascript代码运行次数:0运行复制
Reader process received: Hello from writer!特点 支持无亲缘关系的进程通信。 可以通过文件路径访问。 数据读完即从管道中移除。
3. 消息队列
消息队列允许进程以消息的形式传递数据,并支持消息的优先级。
示例代码
发送端代码:
代码语言:javascript代码运行次数:0运行复制
#include #include #include #include struct msg_buffer { long msg_type; char msg_text[100];};int main() { key_t key; int msgid; // 创建唯一的键值 key = ftok("progfile", 65); // 创建消息队列 msgid = msgget(key, 0666 | IPC_CREAT); struct msg_buffer message; message.msg_type = 1; strcpy(message.msg_text, "Hello, Message Queue!"); // 发送消息 msgsnd(msgid, &message, sizeof(message), 0); printf("Data sent: %sn", message.msg_text); return 0;}接收端代码:
代码语言:javascript代码运行次数:0运行复制
#include #include #include #include struct msg_buffer { long msg_type; char msg_text[100];};int main() { key_t key; int msgid; // 创建唯一的键值 key = ftok("progfile", 65); // 获取消息队列 msgid = msgget(key, 0666 | IPC_CREAT); struct msg_buffer message; // 接收消息 msgrcv(msgid, &message, sizeof(message), 1, 0); printf("Data received: %sn", message.msg_text); // 删除消息队列 msgctl(msgid, IPC_RMID, NULL); return 0;}运行结果
运行发送端程序后,再运行接收端程序,结果如下:
发送端输出:
代码语言:javascript代码运行次数:0运行复制
Data sent: Hello, Message Queue!接收端输出:
代码语言:javascript代码运行次数:0运行复制
Data received: Hello, Message Queue!消息队列的优点和缺点
优点
缺点
支持优先级队列,消息可以按优先级读取
需要显式创建和销毁队列,操作较复杂
数据结构化,适合传递小型消息
消息大小受系统限制,传递大数据性能较差
进程间解耦,无需直接建立父子关系
存在队列上限,可能导致阻塞或失败
4. 共享内存
共享内存是Linux中效率最高的进程通信方式,因为数据直接存储在内存中,无需拷贝。它非常适合用于传递大规模数据。
特性 高效:内存共享避免了数据拷贝,通信效率高。 需同步机制:由于共享内存区域可以同时被多个进程访问,需要使用信号量或其他同步机制防止数据冲突。 适合大数据量传输:特别适合需要频繁通信的场景。 示例代码
以下展示了共享内存的基本用法。
创建和写入共享内存的进程:
代码语言:javascript代码运行次数:0运行复制
#include #include #include #include int main() { // 创建唯一键值 key_t key = ftok("shmfile", 65); // 创建共享内存段 int shmid = shmget(key, 1024, 0666 | IPC_CREAT); // 将共享内存附加到进程地址空间 char *str = (char *) shmat(shmid, (void *)0, 0); // 写入数据 strcpy(str, "Hello, Shared Memory!"); printf("Data written to shared memory: %sn", str); // 分离共享内存 shmdt(str); return 0;}读取共享内存的进程:
代码语言:javascript代码运行次数:0运行复制
#include #include #include int main() { // 创建唯一键值 key_t key = ftok("shmfile", 65); // 获取共享内存段 int shmid = shmget(key, 1024, 0666 | IPC_CREAT); // 将共享内存附加到进程地址空间 char *str = (char *) shmat(shmid, (void *)0, 0); // 读取数据 printf("Data read from shared memory: %sn", str); // 分离共享内存 shmdt(str); // 销毁共享内存 shmctl(shmid, IPC_RMID, NULL); return 0;}运行结果
写入进程输出:
代码语言:javascript代码运行次数:0运行复制
Data written to shared memory: Hello, Shared Memory!读取进程输出:
代码语言:javascript代码运行次数:0运行复制
Data read from shared memory: Hello, Shared Memory!优缺点
优点
缺点
高效,适合大数据传输
需显式同步,复杂度较高
数据共享无需频繁拷贝
进程需要协同管理内存
持续性强,共享内存在进程间保持有效
易出现数据一致性问题
总结
Linux中的进程通信机制为开发者提供了多种灵活的工具,应根据应用场景选择合适的方式:
管道与命名管道:简单场景下的首选,适用于中小型数据流。 消息队列:适合需要传递结构化消息的异步场景。 共享内存:性能需求高或传输大数据时的最佳选择,但需同步机制配合。
通信机制
数据传输方向
数据持久性
是否需同步
优化场景
管道(Pipe)
单向
瞬时
不需要
父子进程通信,简单小型数据流
FIFO
单向
瞬时
不需要
无亲缘关系的进程间通信
消息队列
单/多向
瞬时
不需要
传递结构化消息,任务解耦
共享内存
双向
持久
需要
频繁通信或大数据传输
以上就是【Linux探索学习】第二十六弹——进程通信:深入理解Linux中的进程通信的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/73779.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























