
重新认识fork()函数在linux系统编程中的应用
初识fork()函数:在Linux中,fork()函数是一个非常重要的系统调用,它用于从一个已存在的进程中创建一个新的进程。新创建的进程被称为子进程,而原进程则被称为父进程。
#include pid_t fork(void);返回值:子进程中返回0,父进程返回子进程的ID,错误时返回-1
当一个进程调用fork()函数时,控制权转移到内核中的fork代码。内核执行以下操作:
为子进程分配新的内存块和内核数据结构将父进程的部分数据结构内容复制到子进程将子进程添加到系统进程列表中fork()函数返回,调度器开始调度
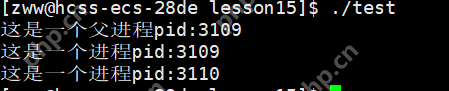 可以看到,这里的例子创建了一个进程,PID为3109,这就是子进程。
可以看到,这里的例子创建了一个进程,PID为3109,这就是子进程。
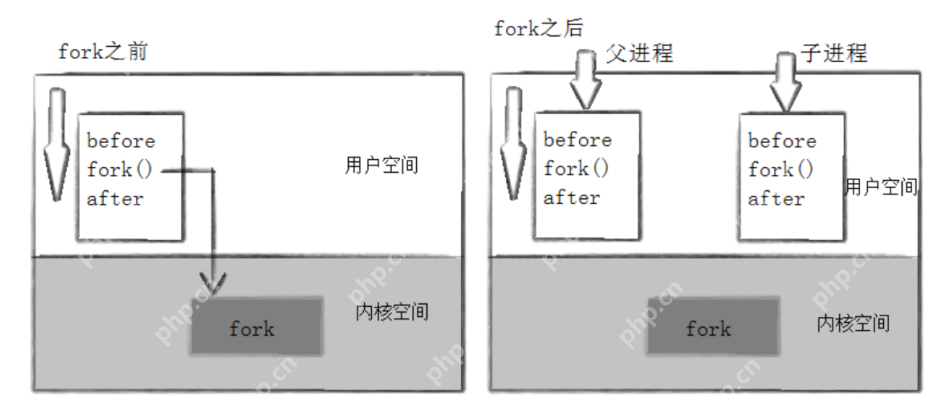 当一个进程调用fork()函数后,会产生两个具有相同二进制代码的进程,且它们都运行到相同的点。但每个进程可以开始它们自己的执行路径,如下面的程序所示。
当一个进程调用fork()函数后,会产生两个具有相同二进制代码的进程,且它们都运行到相同的点。但每个进程可以开始它们自己的执行路径,如下面的程序所示。
int main(void) { pid_t pid; printf("Before: pid is %dn", getpid()); if ((pid=fork()) == -1) perror("fork()"),exit(1); printf("After: pid is %d, fork return %dn", getpid(), pid); sleep(1); return 0;}
运行结果:
[root@localhost linux]# ./a.outBefore: pid is 43676After: pid is 43676, fork return 43677After: pid is 43677, fork return 0
这里可以看到三行输出,一行是Before,两行是After。进程43676先打印Before消息,然后它打印了After。另一个After消息是由进程43677打印的。注意,进程43677没有打印Before,为什么呢?如下图所示:
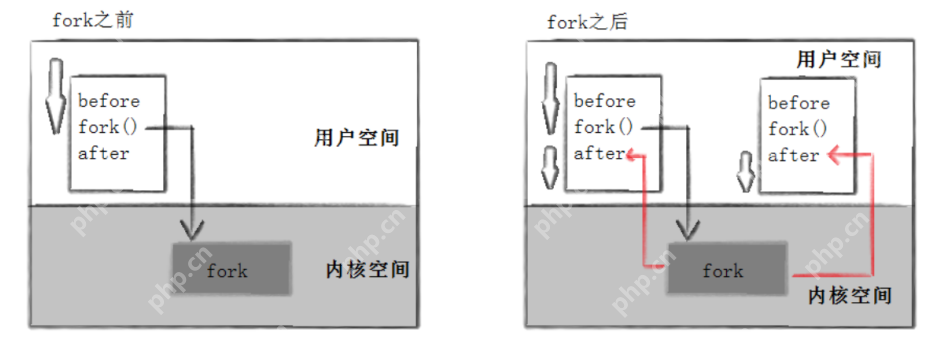 因此,在fork之前,父进程独立执行;在fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
因此,在fork之前,父进程独立执行;在fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
fork()函数的返回值:子进程返回0,父进程返回子进程的PID。
写时拷贝(Copy-on-write, COW)是计算机系统中广泛应用的一种优化技术,尤其是在操作系统、虚拟化和内存管理领域。其主要目的是节省内存资源和提高效率。
工作原理:写时拷贝的基本思想是,当多个进程共享相同的资源(例如内存或文件)时,如果一个进程对这些资源进行修改,系统并不会立即为该进程创建资源的副本,而是推迟到该进程真正进行修改时,才为它分配一个新的副本。具体步骤如下:
共享资源:多个进程最初可以共享同一块内存区域或文件(即资源是只读的)。标记只读:系统会将这些共享的资源标记为只读。修改时拷贝:当一个进程尝试修改共享资源时,操作系统会为该进程创建资源的副本,并将其设为可写。其他进程仍然使用原始资源,而修改的进程则使用新的副本。继续共享:如果其他进程继续只读访问原始资源,不会进行拷贝,节省内存和计算资源。
具体的理解可以看下面这一张图片:
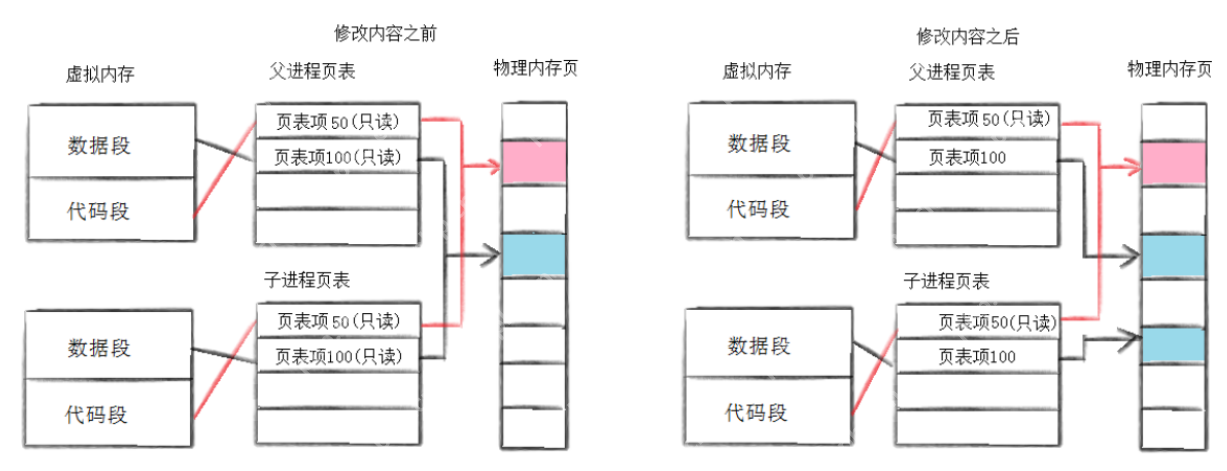
优点:
节省内存:由于多个进程或线程可以共享同一资源副本,减少了内存的消耗。提高性能:避免不必要的拷贝操作,只有在修改资源时才进行拷贝,从而提高了效率。提高数据一致性:写时拷贝确保在修改数据时不会影响其他进程或线程读取到的数据,避免了数据冲突。
缺点:
延迟开销:在第一次修改资源时,系统需要创建资源的副本,这可能带来一定的性能开销。资源消耗:如果多个进程频繁进行写操作,系统会进行多次资源拷贝,可能增加资源消耗。
fork的常规用法以及调用失败的原因:一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
原因:
系统中有太多的进程实际用户的进程数超过了限制进程终止
进程终止的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码。
进程终止对应的三种情况:
代码运行完毕,结果正确代码运行完毕,结果不正确代码异常终止
进程常见的退出方法:
正常终止(可以通过 echo $? 查看进程退出码):
从main返回调用exit
_exit
异常退出:
ctrl + c,信号终止
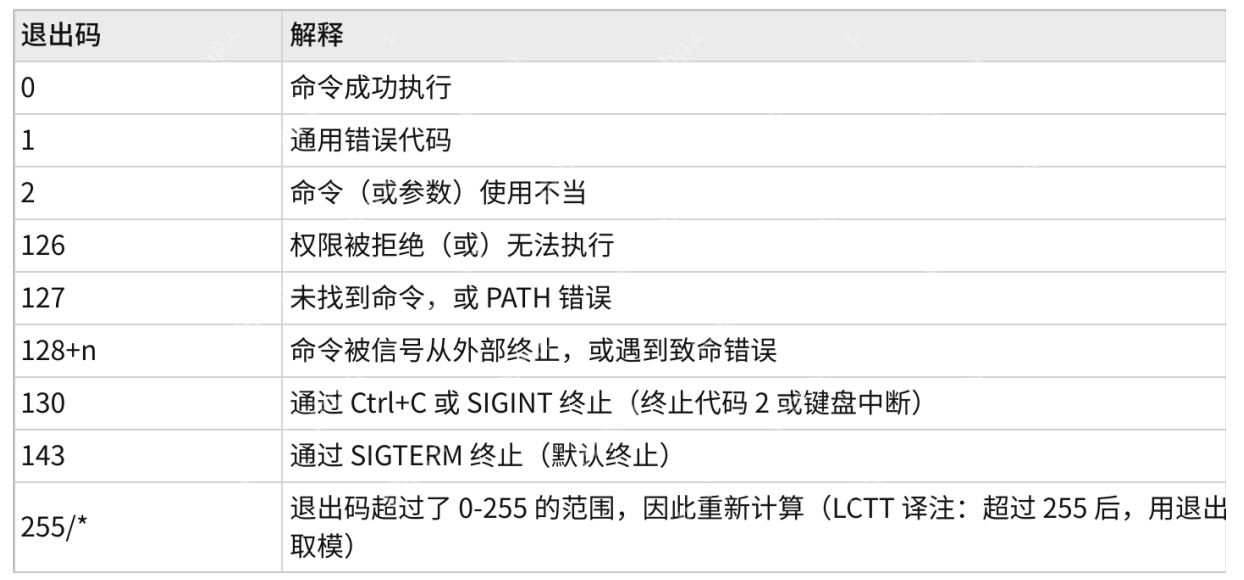
退出码(退出状态)可以告诉我们最后一次执行的命令的状态。在命令结束以后,我们可以知道命令是成功完成的还是以错误结束的。其基本思想是,程序返回退出代码 0 时表示执行成功,没有问题。
代码 1 或 0 以外的任何代码都被视为不成功。
下面是Linux shell常见的退出码:
 智谱AI开放平台
智谱AI开放平台
智谱AI大模型开放平台-新一代国产自主通用AI开放平台
 85 查看详情
85 查看详情 
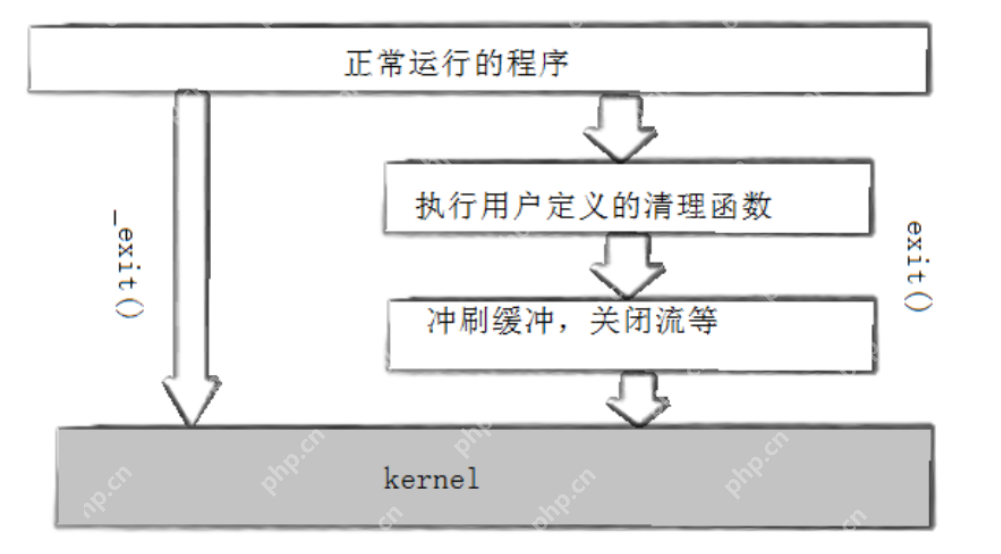
_exit函数:
#include void _exit(int status);参数:status 定义了进程的终止状态,父进程通过wait来获取该值
说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值是255。
exit函数:
#include void exit(int status);
exit最后也会调用_exit, 但在调用_exit之前,还做了其他工作:
执行用户通过 atexit或on_exit定义的清理函数。关闭所有打开的流,所有的缓存数据均被写入调用_exit
示例:
int main() { printf("hello"); exit(0);}int main() {printf("hello");_exit(0);}
上面的结果分别为:
运行结果:[root@localhost linux]# ./a.outhello[root@localhost linux]#运行结果:[root@localhost linux]# ./a.out[root@localhost linux]#
return退出:return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值作为exit的参数。
进程等待:进程等待是指在操作系统中,当一个进程无法继续执行时,它进入一种阻塞状态,等待某些条件或事件的发生才能恢复执行。等待通常发生在进程需要等待资源(如CPU、内存、I/O设备等)或与其他进程之间的同步和通信。
进程等待的必要性:
资源共享与避免冲突:多个进程共享资源时,等待机制确保不会发生冲突,避免竞争条件。进程同步与通信:确保进程按照正确顺序执行,例如生产者和消费者模型。CPU资源管理:避免无谓的CPU占用,让等待的进程释放CPU,提高系统效率。防止死锁:通过合理设计等待策略,避免多个进程互相等待,进入死锁状态。提升并发性:使系统能够并发执行多个进程,最大化资源利用。提高系统稳定性:管理进程优先级,保证重要任务及时执行,确保系统稳定运行。
进程等待的方法:
wait方法:
#includeinclude
pid_t wait(int status);返回值:成功返回被等待进程的PID,失败返回-1。参数:输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
waitpid方法:
pid_t waitpid(pid_t pid, int status, int options);返回值:当正常返回的时候waitpid返回收集到的子进程的进程ID;如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;参数:pid:Pid=-1,等待任意一个子进程。与wait等效。Pid>0.等待其进程ID与pid相等的子进程。status: 输出型参数WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)options:默认为0,表示阻塞等待。WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。
如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退出信息。如果在任意时刻调用wait/waitpid,子进程存在且正常运行,则进程可能阻塞。如果不存在该子进程,则立即出错返回。
获取子进程的status:wait和waitpid都有status参数,该参数是一个输出型参数,由操作系统填充。如果传递NULL,表示不关心子进程的退出状态信息。否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16位):
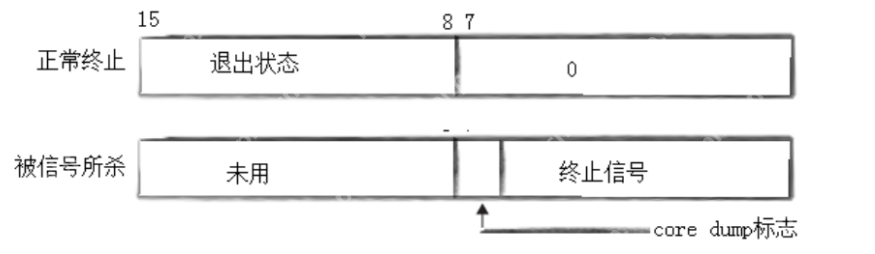
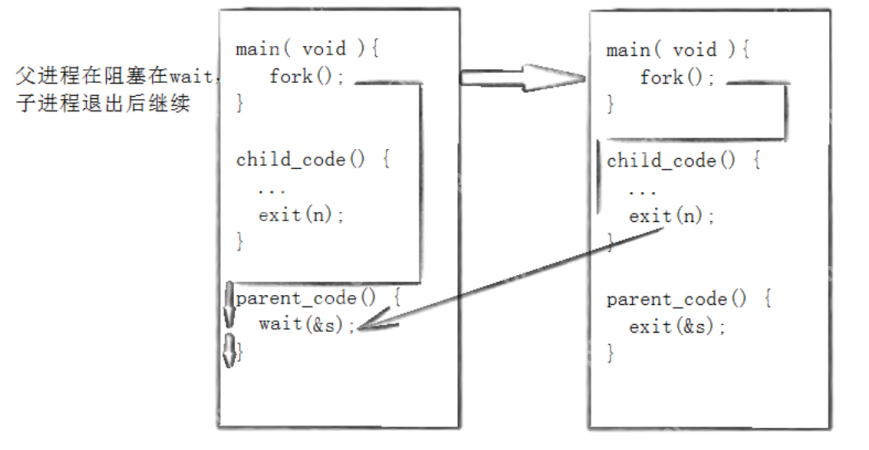
进程的阻塞等待方式:
int main() {pid_t pid;pid = fork();if(pid < 0) {perror("fork");exit(1);} else if(pid == 0) {printf("子进程运行中,PID=%dn", getpid());sleep(5);exit(0);} else {printf("父进程等待子进程...n");wait(NULL);printf("子进程已终止,父进程继续...n");}return 0;}
进程的非阻塞等待方式:
#includeinclude
include
include
include
typedef void (*handler_t)(); // 函数指针类型std::vector handlers; // 函数指针数组
void fun_one() {printf("这是一个临时任务1n");}
void fun_two() {printf("这是一个临时任务2n");}
void Load() {handlers.push_back(fun_one);handlers.push_back(fun_two);}
void handler() {if (handlers.empty()) Load();for (auto iter : handlers) iter();}
int main() {pid_t pid;pid = fork();if (pid < 0) {perror("fork");exit(1);} else if (pid == 0) {printf("子进程运行中,PID=%dn", getpid());sleep(5);exit(0);} else {printf("父进程非阻塞等待子进程...n");int status;while (waitpid(pid, &status, WNOHANG) == 0) {printf("父进程继续执行...n");sleep(1);handler();}if (WIFEXITED(status)) {printf("子进程正常终止,退出码=%dn", WEXITSTATUS(status));} else {printf("子进程异常终止n");}}return 0;}
以上就是【Linux系统编程】—— 深度解析进程等待与终止:系统高效运行的关键的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/739191.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























