
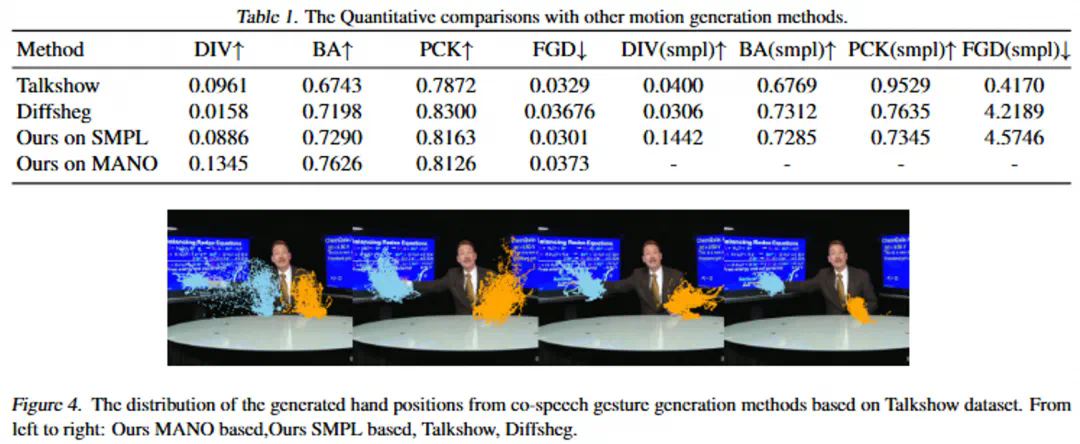
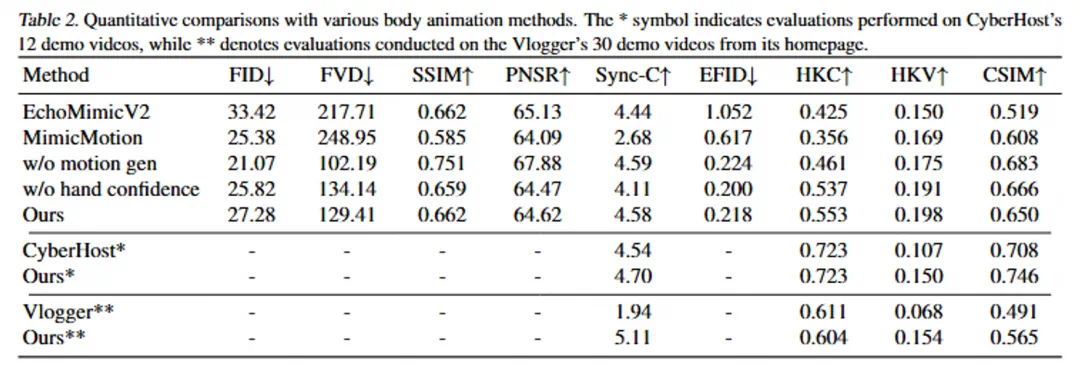
阿里巴巴通义实验室的最新研究成果emo2,实现了仅需一张肖像照片和任意长度音频,即可生成高度逼真、感染力十足的ai人像视频。该技术突破了以往音频驱动人像视频生成在动作流畅度和表现力上的局限,为虚拟主播、数字人等领域带来革新。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏持续报道全球顶尖AI实验室的学术技术成果,至今已发布2000余篇高质量文章。欢迎投稿分享您的研究成果!投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
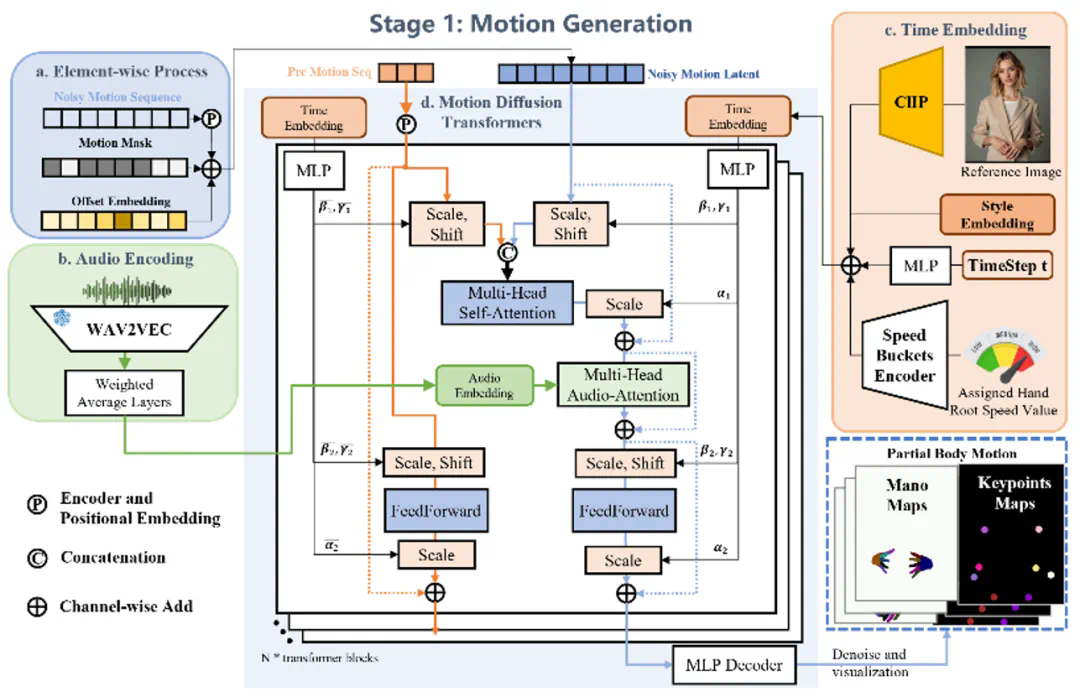
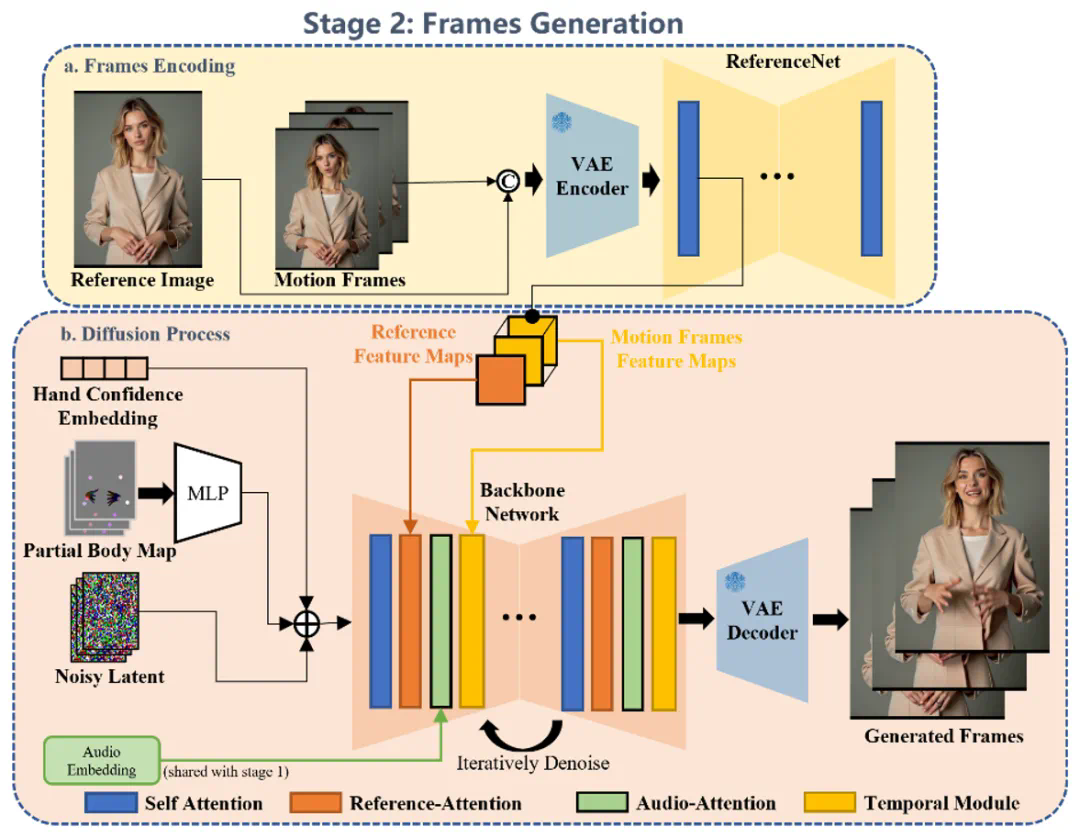
EMO2的核心创新在于其“末端执行器”引导的生成策略。研究者巧妙地借鉴机器人控制系统中的“末端执行器”(例如机械手)概念,将手部动作作为关键驱动因素。由于手部动作与人类意图关联紧密,且与音频信号的相关性显著,因此优先生成手部动作,再利用逆向运动学和像素先验知识,生成其他身体部位的自然动作,从而避免了传统方法中容易出现的动作僵硬、不协调等问题。

论文标题:EMO2: End-Effector Guided Audio-Driven Avatar Video Generation论文地址:https://www.php.cn/link/5f1b9c5afb9283895ff098846faacf50项目地址:https://www.php.cn/link/0f92c979a6541ca6b7f292ae1dcf5ec8
以下是一些EMO2生成的视频示例:
 绘蛙AI视频
绘蛙AI视频
绘蛙推出的AI模特视频生成工具
 127 查看详情
127 查看详情 



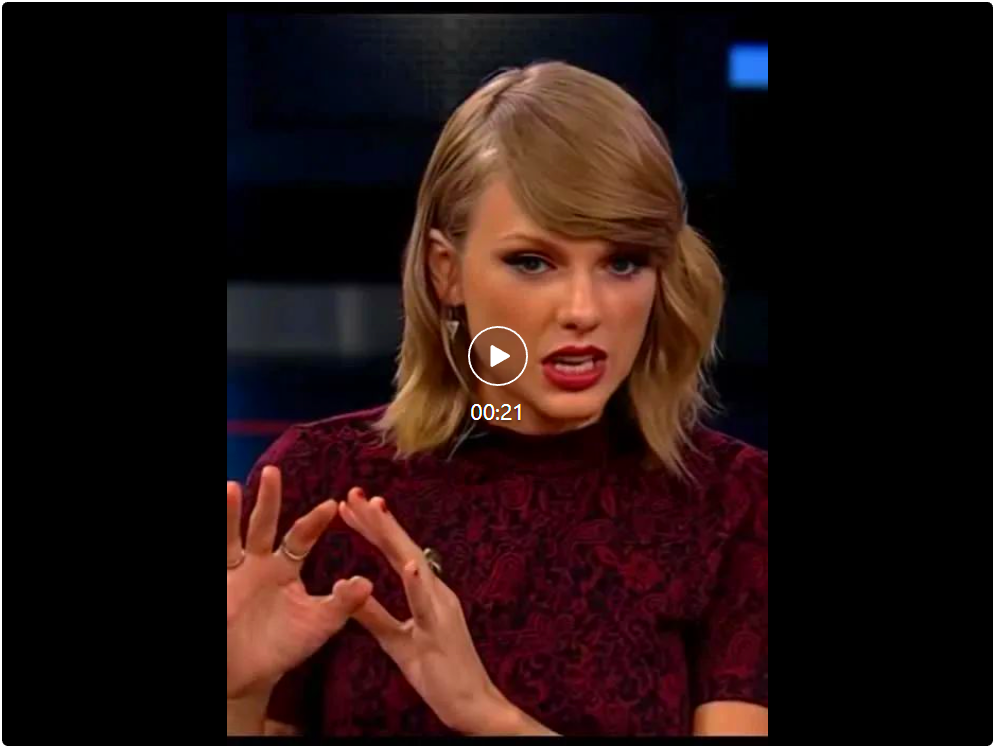

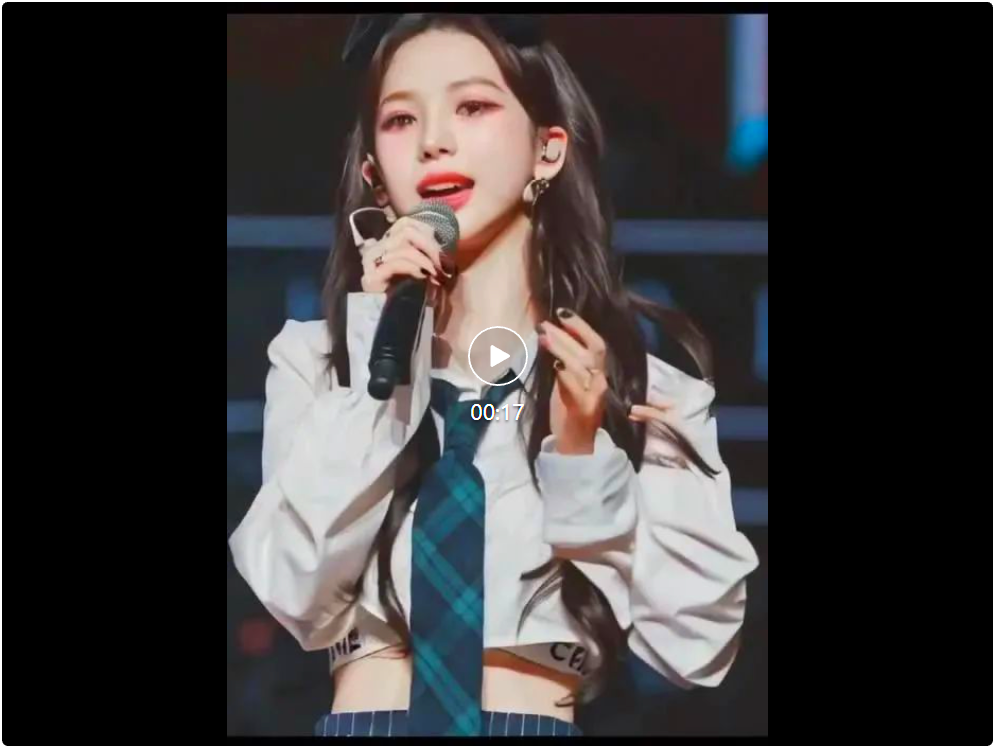
EMO2采用两阶段框架:首先基于DIT模型生成精准的手部动作,然后利用基于扩散UNet的视频生成模型,以手部动作作为引导,合成包含自然面部表情和身体动作的完整视频。实验结果表明,EMO2在动作多样性、流畅度和与音频的一致性方面均显著优于现有方法。 这为音频驱动视频生成技术提供了新的方向。

以上就是真假难辨!阿里升级AI人像视频生成,表情动作直逼专业水准的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/761762.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























