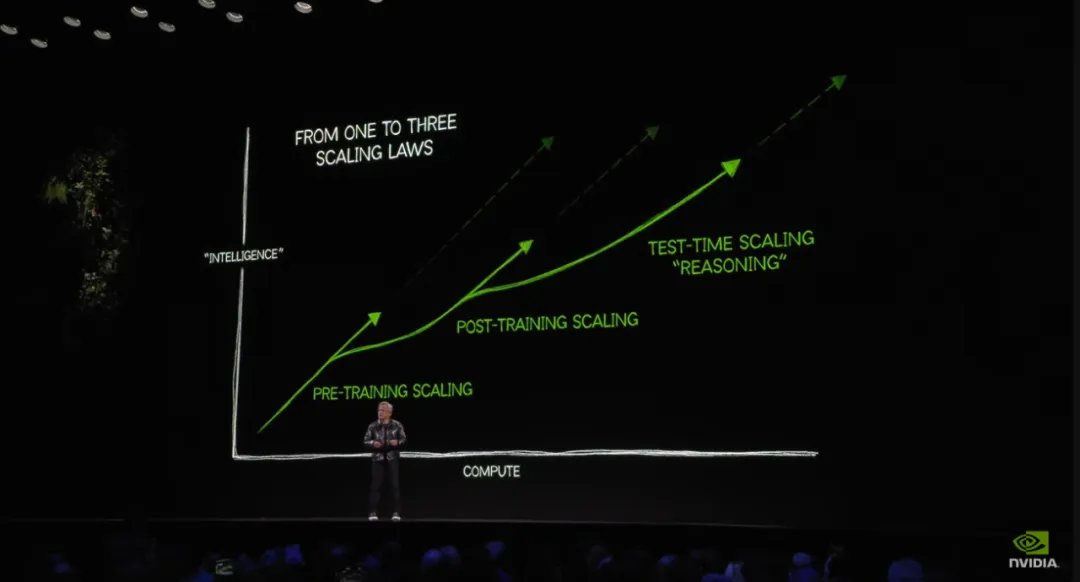
优化大模型的测试时计算是提升模型部署效率和节省计算资源的关键一环。前段时间,黄仁勋在 CES 2025 的演讲中把测试时 Scaling 形容为大模型发展的三条曲线之一。如何优化测试时计算成为业界关注的重要课题。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

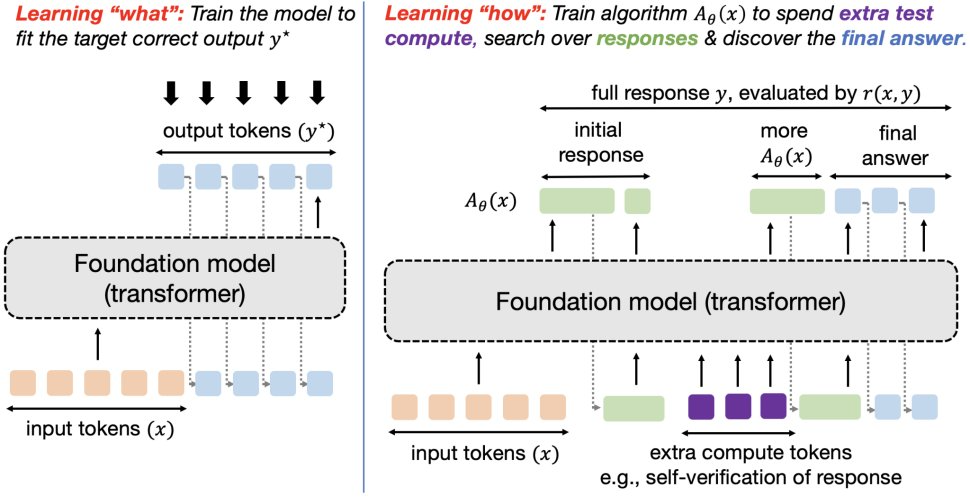
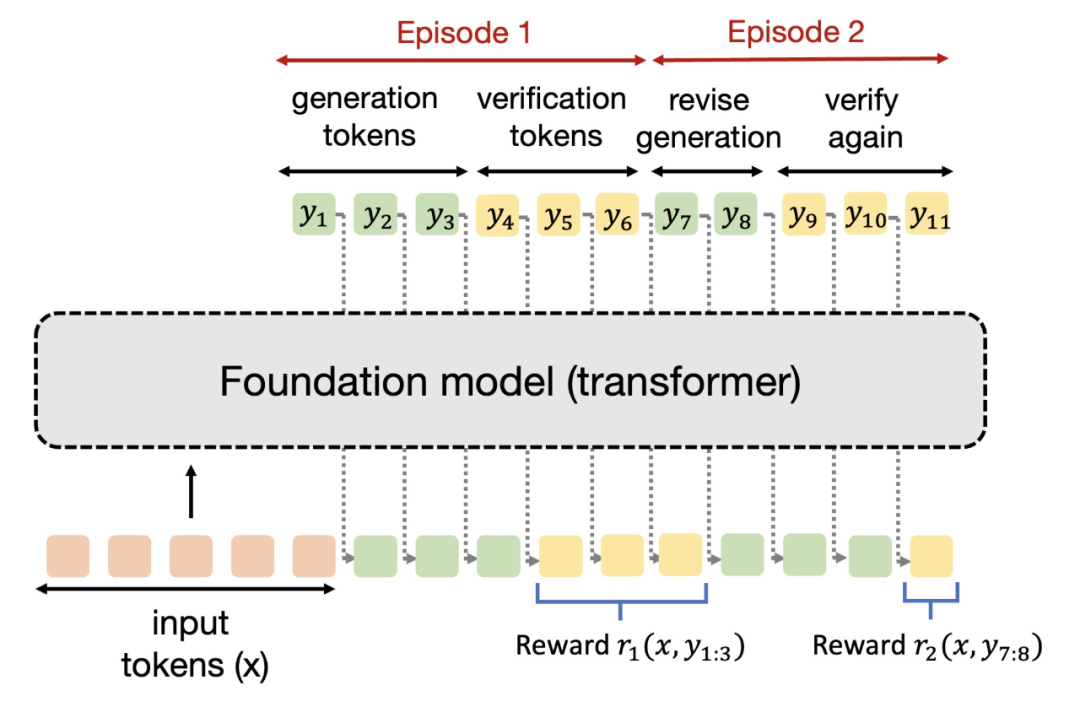
到目前为止,改进大型语言模型 (LLM) 的主要策略是使用越来越多的高质量数据进行监督微调 (SFT) 或强化学习 (RL)。不幸的是,这种扩展形式似乎很快就会遇到瓶颈,预训练的扩展定律会趋于稳定,有报告称,用于训练的高质量文本数据可能在 2028 年耗尽,特别是对于更困难的任务,例如解决推理问题,这似乎需要将当前数据扩展约 100 倍才能看到任何显著的改进。LLM 在这些困难任务中的问题上的当前表现仍然不尽如人意。因此,迫切需要数据高效的方法来训练 LLM,这些方法可以超越数据扩展并解决更复杂的挑战。在这篇文章中,我们将讨论这样一种方法:通过改变 LLM 训练目标,我们可以重用现有数据以及更多的测试时计算来训练模型以做得更好。博客地址:https://blog.ml.cmu.edu/2025/01/08/optimizing-llm-test-time-compute-involves-solving-a-meta-rl-problem/ 图 1:训练模型以优化测试时计算并学习「如何发现」正确答案,而不是学习输出「什么答案」的传统学习范式。当前训练模型的主要原则是监督它们为输入产生特定的输出。例如,监督微调尝试匹配给定输入的直接输出 token,类似于模仿学习,而 RL 微调训练响应以优化奖励函数,该函数通常应该在 oracle 响应上取最高值。无论哪种情况,我们都在训练模型以产生它可以表示的 y* 的最佳近似值。从抽象上讲,这种范式训练模型以产生单个输入输出映射,当目标是直接解决给定分布中的一组类似查询时,这种方法很有效,但无法发现分布外查询的解决方案。固定的、一刀切的方法无法有效适应任务的异质性。我们更希望有一个强大的模型,它能够通过尝试多种方法并在不同程度上寻求信息,或者在无法完全解决问题时表达不确定性,从而推广到新的、未见过的问题。为了解决上述问题,一个新想法是允许模型在测试时使用计算资源来寻找「元(meta)」策略或算法,这些策略或算法可以帮助它们理解「如何」得出一个好的答案。实现能够赋予模型系统性程序运行能力的元策略,应该能够使其在测试时外推和泛化到不同复杂度的输入查询。例如,如果一个模型被教了柯西 – 施瓦茨不等式的含义,它就应该能够在简单和困难的证明问题上在适当的时候运用它。换句话说,给定一个测试查询,我们希望模型能够执行包含多个基本推理步骤的策略,这可能需要消耗更多的 token。图 2 展示了解决一个给定问题的两种不同策略的例子。我们如何训练模型来做到这一点呢?我们将把这个目标形式化为一个学习问题,并通过元强化学习的思路来解决它。 图 2: 展示了两种算法及其各自生成的 token 流示例。对于每个问题 x∈X,假设我们有一个奖励函数 r (x,⋅):Y↦{0,1}, 可以针对任何输出 token 流 y 进行查询。例如,对于数学推理问题 x,其 token 输出流为 y,奖励 r (x,y) 可以是检查某个 token 子序列是否包含正确答案的函数。我们只获得了训练问题数据集 D_train, 因此也只有奖励函数集合 {r (x,⋅):x∈D_train}。我们的目标是在事先未知的测试问题分布 P_test 上获得高奖励。测试问题的难度可能与训练问题不同。对于未知的测试问题分布 P_test 和有限的测试时计算预算 C,我们可以从训练问题数据集 D_train 中学习一个算法 A∈A_C (D_train), 这个算法属于推理计算受限的测试时算法类 A_C。这个类中的每个算法都以问题 x∼P_test 作为输入,并输出一个 token 流。在图 2 中,我们给出了一些例子来帮助理解这个 token 流可以是什么。例如,A_θ(x) 可能首先包含针对问题 x 的某些尝试 token,然后是一些用于预测尝试正确性的验证 token,如果验证为不正确,接着是对初始尝试的一些改进,所有这些都以「线性」方式串联在一起。另一个算法 A_θ(x) 可能是以线性方式模拟某种启发式引导搜索算法。算法类 A_C (D_train) 将由上述所有可能的 A_θ(x) 产生的下一个 token 分布组成。注意,在这些例子中,我们希望使用更多的 token 来学习一个通用但可泛化的程序,而不是去猜测问题 x 的解决方案。我们的学习目标是学习由自回归大语言模型参数化的 A_θ(x)。我们将这整个流 (包括最终答案) 称为响应 y∼A_θ(x)。算法 A_θ(x) 的效用由奖励 r (x,y) 衡量的平均正确性给出。因此,我们可以将学习算法表述为解决以下优化问题:接下来的问题是:我们如何解决由语言模型参数化的、在计算受限算法类 A_c 上的优化问题 (Op-How)?显然,我们既不知道测试问题的结果,也没有任何监督信息。因此,计算外部期望是徒劳的。对问题 x 猜测最佳可能响应的「标准」大语言模型策略似乎也不是最优的,因为如果充分利用计算预算 C,它可能会做得更好。主要思路是优化 (Op-How) 的算法 A_θ(x)∈A_c,类似于强化学习中的自适应策略,它使用额外的 token 预算来实现某种算法策略来解决输入问题 x。有了这个联系,我们可以从类似问题通常的解决方式中获得启发:通过元学习的视角来看待 (Op-How),具体来说是元强化学习:「元」是因为我们希望学习算法而不是直接回答给定问题,而「强化学习」是因为 (Op-How) 是一个奖励最大化问题。通常,强化学习训练一个策略来最大化马尔可夫决策过程 (MDP) 中的给定奖励函数。相比之下,元强化学习问题设定假设可以访问任务分布 (每个任务都有不同的奖励函数和动态特性)。在这种设定下,目标是在来自训练分布的任务上训练策略,使其能够在从相同或不同测试分布抽取的测试任务上表现良好。此外,这种设定不是根据策略在测试任务上的零样本表现来评估它,而是让它通过在测试时执行几个「训练」回合来适应测试任务,在执行这些回合之后再评估策略。回到我们的设定,你可能会想知道马尔可夫决策过程(MDP)和多个任务 (用于元强化学习) 是如何体现的。每个问题 x∈X 都会引发一个新的强化学习任务,这个任务被形式化为马尔可夫决策过程 (MDP) M_x,其中问题 x 中的 token 集合作为初始状态,我们的大语言模型 A_θ(x) 产生的每个 token 作为一个动作,而简单的确定性动态则通过将新的 token ∈T 与到目前为止的 token 序列连接来定义。注意,所有 MDP 共享动作集合和状态集合  ,这些对应于词汇表中可能出现的变长 token 序列。然而,每个 MDP M_x 都有一个不同的未知奖励函数,由比较器 r (x,⋅) 给出。那么解决 (Op-How) 就对应着找到一个策略,该策略能够在计算预算 C 内快速适应测试问题 (或测试状态) 的分布。从认知 POMDP 的视角来看这种测试时泛化的概念是另一种方式,这是一个将在 M_x 族上学习策略视为部分观察强化学习问题的构造。这个视角提供了另一种激发自适应策略和元强化学习需求的方式:对于那些有强化学习背景的人来说,解决 POMDP 等同于运行元强化学习这一点应该不足为奇。因此,通过解决元强化学习目标,我们正在寻求这个认知 POMDP 的最优策略并实现泛化。在元强化学习中,对于每个测试 MDP M_x,策略 A_θ 在通过 A_θ 生成最终响应进行评估之前,可以通过消耗测试时计算来获取信息。在元强化学习术语中,获得的关于测试 MDP M_x 的信息可以被视为在测试问题 x 引发的 MDP 上收集「训练」回合的奖励,然后再在测试回合上进行评估。注意,所有这些回合都是在模型部署后执行的。因此,为了解决 (Op-How),我们可以将来自 A_θ(x) 的整个 token 流视为分成几个训练回合的流。为了优化测试时计算,我们需要确保每个回合都能提供一些信息增益,以便在测试 MDP M_x 的后续回合中表现更好。如果没有信息增益,那么学习 A_θ(x) 就退化为一个标准的强化学习问题 —— 只是计算预算更高 —— 这样就不清楚学习「如何做」是否有用。可以获得什么样的信息?当然,如果 token 流中涉及外部接口,我们可以获得更多信息。但是,如果不涉及外部工具,我们是否在利用免费午餐?我们指出不是这种情况,在 token 流进行过程中不需要涉及外部工具也能获得信息。流中的每个回合都可以有意义地增加更多信息,也就是说,我们可以将消耗更多的测试时计算视为从模型对最优解的后验近似 P (⋅|x,θ) 中采样的一种方式,其中每个回合 (或输出流中的 token) 都在改进这个近似。因此,显式地调整先前生成的 token 可以提供一种计算可行的方式,用固定大小的大语言模型来表征这个后验。综上所述,当被视为元强化学习问题时,A (⋅|⋅) 成为一个历史条件 (「自适应」) 策略,通过在给定测试问题上花费最多 C 的计算来优化奖励 r。 图 3:智能体 – 环境交互协议。图源:https://arxiv.org/pdf/1611.02779 图 4:A_θ(x) 的响应包括一串 token。我们如何解决这样一个元强化学习问题?也许解决元强化学习问题最明显的方法是采用黑盒元强化学习方法。这将涉及最大化输出轨迹 A_θ(x) 中想象的「episodes」的奖励总和。例如,如果 A_θ(x) 对应于使用自我纠正策略,那么每个 episode 的奖励将对轨迹中出现的单个响应进行评分。如果 A_θ(x) 规定了一种在生成和生成验证之间交替的策略,那么奖励将对应于生成和验证的成功。然后我们可以优化:一般情况下,输出 token 流可能无法清晰地分成生成和验证片段。在这种情况下,可以考虑元强化学习问题的更抽象形式,直接使用信息增益的某种估计作为奖励。可以通过多轮强化学习方法来解决 (Obj-1) 和 (Obj-2)。实际上,只要能够使用某种执行定期在线策略采样的强化学习算法来解决优化问题,强化学习方法的选择 (基于价值还是基于策略) 可能并不重要。我们还可以考虑另一种制定元强化学习训练目标的方法:只优化测试回合获得的奖励,而不是训练回合的奖励,从而避免量化信息增益的需要。
,这些对应于词汇表中可能出现的变长 token 序列。然而,每个 MDP M_x 都有一个不同的未知奖励函数,由比较器 r (x,⋅) 给出。那么解决 (Op-How) 就对应着找到一个策略,该策略能够在计算预算 C 内快速适应测试问题 (或测试状态) 的分布。从认知 POMDP 的视角来看这种测试时泛化的概念是另一种方式,这是一个将在 M_x 族上学习策略视为部分观察强化学习问题的构造。这个视角提供了另一种激发自适应策略和元强化学习需求的方式:对于那些有强化学习背景的人来说,解决 POMDP 等同于运行元强化学习这一点应该不足为奇。因此,通过解决元强化学习目标,我们正在寻求这个认知 POMDP 的最优策略并实现泛化。在元强化学习中,对于每个测试 MDP M_x,策略 A_θ 在通过 A_θ 生成最终响应进行评估之前,可以通过消耗测试时计算来获取信息。在元强化学习术语中,获得的关于测试 MDP M_x 的信息可以被视为在测试问题 x 引发的 MDP 上收集「训练」回合的奖励,然后再在测试回合上进行评估。注意,所有这些回合都是在模型部署后执行的。因此,为了解决 (Op-How),我们可以将来自 A_θ(x) 的整个 token 流视为分成几个训练回合的流。为了优化测试时计算,我们需要确保每个回合都能提供一些信息增益,以便在测试 MDP M_x 的后续回合中表现更好。如果没有信息增益,那么学习 A_θ(x) 就退化为一个标准的强化学习问题 —— 只是计算预算更高 —— 这样就不清楚学习「如何做」是否有用。可以获得什么样的信息?当然,如果 token 流中涉及外部接口,我们可以获得更多信息。但是,如果不涉及外部工具,我们是否在利用免费午餐?我们指出不是这种情况,在 token 流进行过程中不需要涉及外部工具也能获得信息。流中的每个回合都可以有意义地增加更多信息,也就是说,我们可以将消耗更多的测试时计算视为从模型对最优解的后验近似 P (⋅|x,θ) 中采样的一种方式,其中每个回合 (或输出流中的 token) 都在改进这个近似。因此,显式地调整先前生成的 token 可以提供一种计算可行的方式,用固定大小的大语言模型来表征这个后验。综上所述,当被视为元强化学习问题时,A (⋅|⋅) 成为一个历史条件 (「自适应」) 策略,通过在给定测试问题上花费最多 C 的计算来优化奖励 r。 图 3:智能体 – 环境交互协议。图源:https://arxiv.org/pdf/1611.02779 图 4:A_θ(x) 的响应包括一串 token。我们如何解决这样一个元强化学习问题?也许解决元强化学习问题最明显的方法是采用黑盒元强化学习方法。这将涉及最大化输出轨迹 A_θ(x) 中想象的「episodes」的奖励总和。例如,如果 A_θ(x) 对应于使用自我纠正策略,那么每个 episode 的奖励将对轨迹中出现的单个响应进行评分。如果 A_θ(x) 规定了一种在生成和生成验证之间交替的策略,那么奖励将对应于生成和验证的成功。然后我们可以优化:一般情况下,输出 token 流可能无法清晰地分成生成和验证片段。在这种情况下,可以考虑元强化学习问题的更抽象形式,直接使用信息增益的某种估计作为奖励。可以通过多轮强化学习方法来解决 (Obj-1) 和 (Obj-2)。实际上,只要能够使用某种执行定期在线策略采样的强化学习算法来解决优化问题,强化学习方法的选择 (基于价值还是基于策略) 可能并不重要。我们还可以考虑另一种制定元强化学习训练目标的方法:只优化测试回合获得的奖励,而不是训练回合的奖励,从而避免量化信息增益的需要。以上就是如何优化测试时计算?解决「元强化学习」问题的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/762866.html



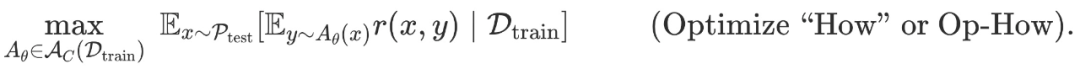
 ,这些对应于词汇表中可能出现的变长 token 序列。然而,每个 MDP M_x 都有一个不同的未知奖励函数,由比较器 r (x,⋅) 给出。
,这些对应于词汇表中可能出现的变长 token 序列。然而,每个 MDP M_x 都有一个不同的未知奖励函数,由比较器 r (x,⋅) 给出。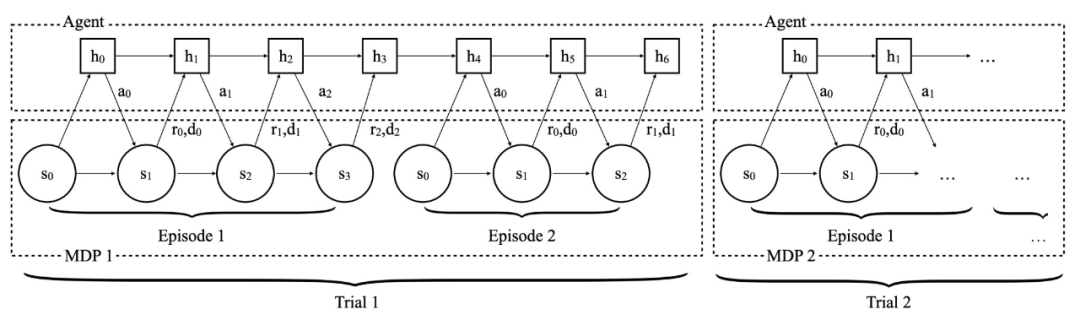

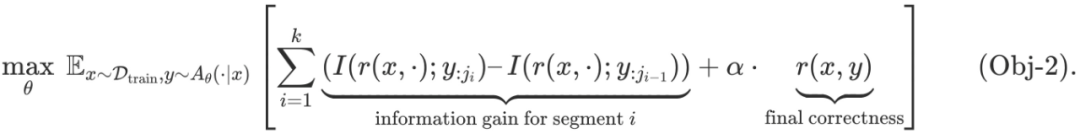
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























